Python语言学习-----Ubuntu16.04上基于YoloV4 的Keras物体识别目录
随着深度学习的发展,目前已经出现了很多算法(或者训练技巧,tricks)来提升神经网络的准确率。在实际测试中评价一个算法的好坏优劣主要看两点,一是能否在大规模的数据集中起作用(work),二是是否有理论依据。一些算法仅能在某些特定的模型上或者某类特定的问题上运行,亦或是适用于一些小规模的数据集。然而,还有一些算法,例如batch normalization(BN)或者残差连接(residual-connections)已经被用在了不同的模型,任务以及不同的数据集中,已经被充分的证明了这些算法的普适性,是一个general的算法。我们假设这样的general(or universal)的算法包括Weighted-residual-connection(WRC),cross-stage-partial-connections(SCP),cross mini-batch Normalization(CmBN),self-adversarial-training(SAT)以及mish-activation。
此外,我们还加了一些其余的tricks,包括Mosaic data augmentation,DropBlock regularization,CIoU loss,设计了一个YOLO-V4,并且在MS coco数据集中取得了新的state-of-the-art的结果:在Tesla V100显卡能达到43.5% AP(65.7% AP)的精度,且达到~65FPS的速度。目前代码已经开源,本次博客,林君学长将带大家了解如何通过YoloV4 实现对物体的识别并标注!
一、YoloV4-Keras包的下载
1、下载
git clone https://github.com/Ma-Dan/keras-yolo4
2、yolov4.weights下载
1)、通过如下百度网盘链接进行权重文件下载,下载后上传至YoloV4-Keras的包中,链接如下:(提取码:dc2j)
https://pan.baidu.com/s/1FF79PmRc8BzZk8M_ARdMmw

2)、yolo4_weights.h5是coco数据集的权重;yolo4_voc_weights.h5是voc数据集的权重。
3、VOC训练集、测试集下载
1)、进入YoloV4-Keras包中,然后打开终端,通过如下命令下载VOC训练集和测试集
cd keras-yolo4
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
2)、解压
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
3)、修改解压后VOCdevkit文件夹名为count,并且修改 count文件夹中的VOC2007为VOC2012,只因为后面代码中是这个

二、yolov4.weights的h5模型转换
1、修改包中convert.py代码内容
1)、打开
gedit convert.py
2)、下翻,修改

2、权重转换模型
1)、通过运行convert.py进行模型装换
cd keras-yolo4
python3 convert.py

2)、转换完成之后,便会生成一个h5模型文件,当然,我们也可以使用上面下载完成的yolo4_weights.h5和yolo4_voc_weights.h5,建议使用yolo4_voc_weights.h5模型,前面模型我进行 测试的时候有错误

三、基于YoloV4 的Keras物体识别
1、修改test.py代码
1)、打开文件
gedit test.py
2)、解决python默认路径问题,在大马开头添加如下代码
import sys
sys.path.remove('/opt/ros/kinetic/lib/python2.7/dist-packages')

因为有的小伙伴在Ubuntu系统上安装ROS,而ROS默认的是python2.7的环境路径,而本次的实验是用python3语言进行编写,所以不进行环境修改会使得运行报错,通过添加如上两行代码可以很好的解决这个问题,而且还不影响ROS的正常使用!
3)、下翻,找到model_path,修改为如上下载的yolo4_voc_weights.h5模型

2、数据图片准备,百度一张小车图片,放进YoloV4-Keras包

3、终端运行测试
1)、通过如下命令,进行对应的物体识别
cd keras-yolo4
python3 test.py
2)、输入图片名称
在运行之后,终端会提示输入文件名称,这时候,输入你命名的小车图片的文件名

3)、运行结果

到这里,本地博客便基本结束了,下面进行模型训练的扩展,有兴趣的小伙伴自己下载VOC数据集进行模型训练,林君学长没有训练出结果,原因是训练途中一直被杀死,正在寻找解决办法中
四、扩展一----5h模型训练
1、修改voc_annotation.py文件

2、修改train.py
1)、在文件内容开始处添加如下代码,修改python环境
sys.path.remove('/opt/ros/kinetic/lib/python2.7/dist-packages')
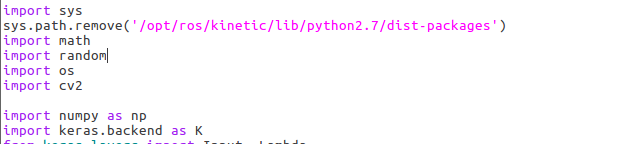
2)、下翻,修改batch_size,防止内存不够

以上是两段哦,两段有相似内容的都需要改哈
3、进行模型训练
1)、运行train.py进行模型训练
python3 train.py
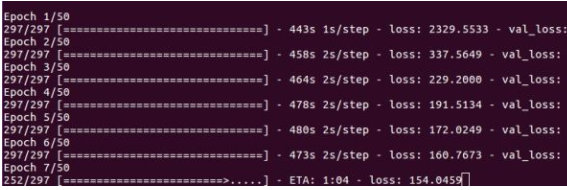
2)、训练正确应该如下所示:
3)、林君学长训练错误结果如下所示:

出现以上错误的具体原因暂未查明,如后续查明,定会更新此博客,同时,希望能够有解决该问题的小伙伴,不言腻舍的在评论区说出你的解决方案啦,我们一起交流一下,解决该问题,谢谢啦!
五、扩展二----YoloV3的物体识别
1、YoloV3下载编译
1)、YoloV3下载
git clone https://github.com/pjreddie/darknet

2)、编译
cd darknet
make -j8
2、下载YoloV3权重文件
wget https://pjreddie.com/media/files/yolov3.weights
以上方法下载很慢,小伙伴可以自己进行百度搜索yolov3.weights权重文件下载,很多百度网盘资源、CSDN资源可以下载,这里就不给出链接啦,搜索一下吧!
3、测试
1)、在终端运行以下命令,进行YoloV3物体识别测试
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
2)、终端运行结果如下所示:

3)、运行完成之后,该工程资源包下便会自己生成一张识别后的图片,如下所示:

4)、识别结果展示,包括狗狗、自行车、卡车

扩展就到这里啦,有兴趣的小伙伴自己深入了解哈,更多学习请参考yolov3官网进行学习,链接如下所示:
https://pjreddie.com/darknet/yolo/
以上就是本次博客的全部内容啦,希望通过本地博客,小伙伴们能够理解YoloV4是如何通过模型训练然后进行对应物体识别的哦,理解原理,编写代码,当然,这代码还是有难度的,至少自己编写不出来,能够看懂就不错啦,这里,林君学长再次感谢网络大佬,让自己能够站在巨人的肩膀上,不过可惜的是,没有人再站在我的肩膀上面了(low不是我我自己想要的)!
遇到问题的小伙伴记得在评论区留言讨论,林君学长看到会为大家解答的,同时,希望有解决以上问题方案的小伙伴能够和学长一起交流一下,阿里嘎多!
陈一月的又一天编程岁月^ _ ^