Python 豆瓣电影Top250爬取并生成csv文件
久违的博客更新,事出有因,晚上有朋友叫我帮忙爬取豆瓣电影Top250数据用来做分析,不过呢网上的这方面的文章有些不好使,我就自己重写了,更新一下网络上这个空缺。
虽然这次的爬取很容易,因为这个网址是静态网页,直接网页源码就可以解析了,不过还是值得你一看,有些细小的点说不定你未曾见识过。
网页链接是这个: https://movie.douban.com/top250
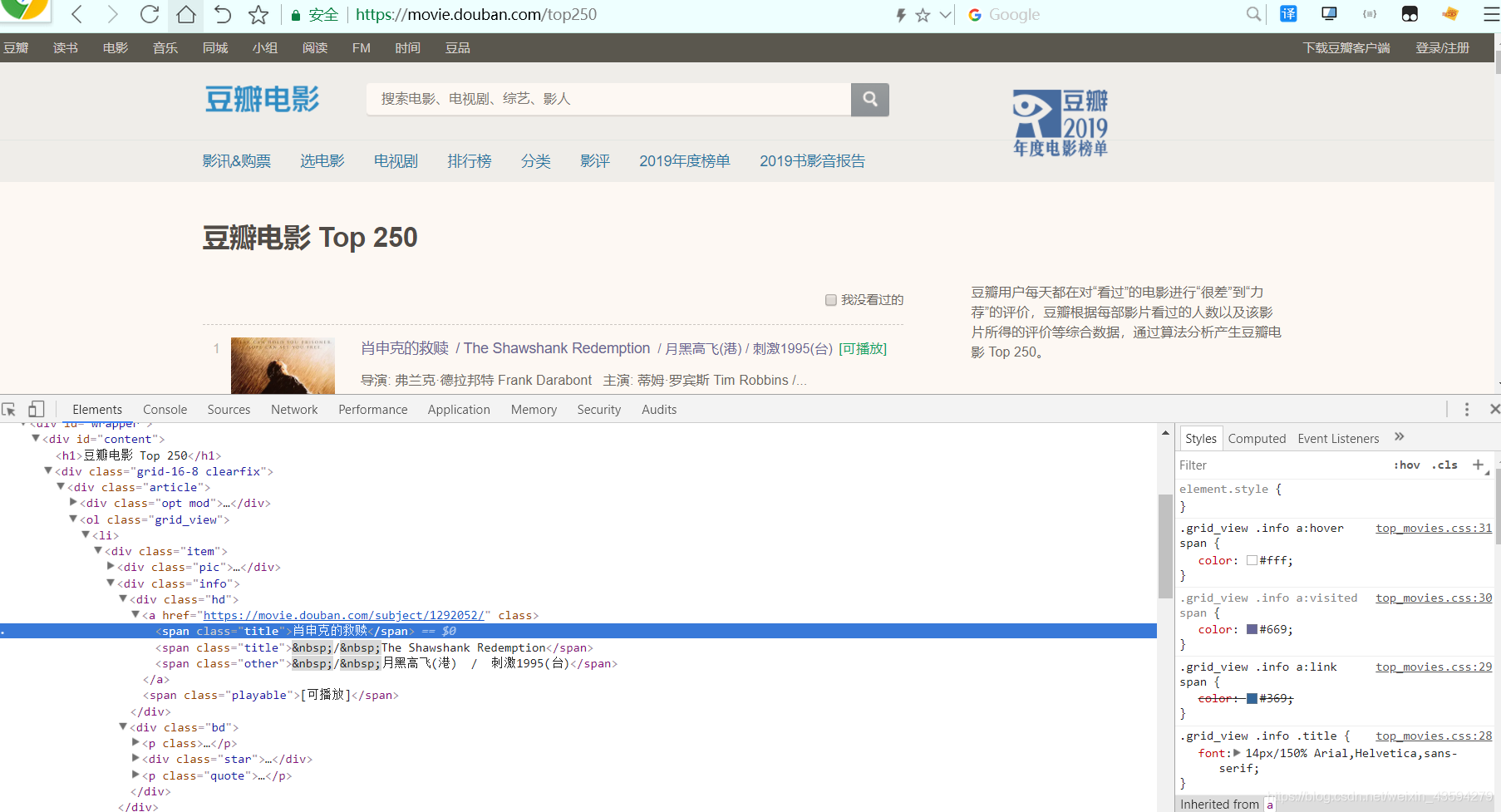
我们直接可以右键弹出菜单点“检查元素”,可以直接找到需要的信息,这次我们的目的是要获取每部电影的:
’电影排名’,‘电影名称’,‘导演’,‘上映年份’,‘制片国家’,‘电影类型’,‘电影评分’,‘评价人数’,'电影短评’
开始代码讲解了:
import requests #每次都是你,最频繁使用的库
from lxml import etree """内含xpath,本人极力推荐使用xpath,不要用bs了"""
import re #正则是为了一些文本的提取,等会你就知道了
如果你在 lxml 这里报错就要去安装它了,cmd窗口里输入 pip install lxml 。
有时候可能会安装失败,大概率是网络问题,多输入几次就好了。
我们先从程序开始的地方看起
if __name__ == '__main__':
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
"""movieInfo将作为csv文件的表头,我们将把数据逐行加入这个列表,否则在保存时就不是我们想要的样子了"""
movieInfo = [['电影排名','电影名称','导演','上映年份','制片国家','电影类型','电影评分','评价人数','电影短评']]
for i in range(0,250,25):
url='https://movie.douban.com/top250?start={}'.format(i)
try:
"""因为爬取静态网页没有难度就直接一个函数搞定"""
DoubanSpider(movieInfo,url,headers=headers)
except:
break
"""将movieInfo保存为csv格式"""
with open('movie.csv','w',encoding='utf-8')as f:
for info in movieInfo:
#逗号分隔每个列表元素然后写入,然后回车到下一行
f.write(','.join(info)+'\n')
print('爬取结束')
重头戏上场了,代码写的实在不敢恭维,因为赶时间,就没有什么优化,请见谅
def DoubanSpider(movieInfo,url,headers):
response = requests.get(url,headers=headers)
html_ele = etree.HTML(response.text)
"""前面几个都是可以直接xpath提取到的,后面就比较麻烦,
不了解的xpath的话可以学习一下,当真好用"""
rank = html_ele.xpath('//div[@class="item"]/div/em/text()')
film_name = html_ele.xpath('//div[@class="item"]/div/a/img/@alt')
quote = html_ele.xpath('//p[@class="quote"]/span/text()')
"""分析代码的时候发现评分和评价人数是合在一起的"""
temp_content = html_ele.xpath('//div[@class="star"]/span/text()')
score=[]
people=[]
index=1
for i in temp_content:
if index%2==1: #奇数的是评分
score.append(i)
else: #偶数的是人数
people.append(i)
index+=1
"""全文最麻烦之处,剩余的信息都糊在一片文本里"""
film_content = html_ele.xpath('//div[@class="bd"]/p/text()')
#用re匹配到数字字符,可是发现出来好多不用的零字符
#上映年份
film_year_temp = re.findall('\d+',str(film_content))
film_year=[]
for i in film_year_temp:
if i!='0':#过滤掉'0'
film_year.append(i)
#获取导演名字
film_director = re.findall(r'导演:(.*?)主演',str(film_content))
director=[]
for i in film_director:
director.append(i.split(r' ')[1])#这里只是让信息输出规范化
#这里就是一连串的文本,然后被分成了好几个小列表
country=[]
index=1
for i in film_content:
if index%4==2:
country.append(i.split('\xa0')[2])
index+=1
film_type=[]
index=1
for i in film_content:
if index%4==2:
film_type.append(i.split('\xa0')[4].strip())
index+=1
"""是时候展现真正的技术啦,hh"""
"""这里的zip是把这些个列表都绑定在一起,为了后面的循环可以每次同时取出每个列表的顺序元素。"""
"""这么做的原因是我们每次函数执行对应数据的列表就被扩充成25,不可能一次性塞给movieInfo,否则存为csv结果就是事与愿违,不信你可以自己试试。"""
"""当然你也可以改代码,每次列表扩充一个,立即加入moiveInfo当中"""
nvs=zip(rank,film_name,director,film_year,country,film_type,score,people,quote)
for rank,film_name,film_director,film_year,country,film_type,score,people,quote in nvs:
movieInfo.append([rank,film_name,film_director,film_year,country,film_type,score,people,quote])
print(url,'爬取完毕')
大功告成,最后就是验收啦!
在这个py文件同目录下就会生成movie.csv文件,可以用记事本打开,不过excel打开才是我们想要的。
当你用excel打开时。。。
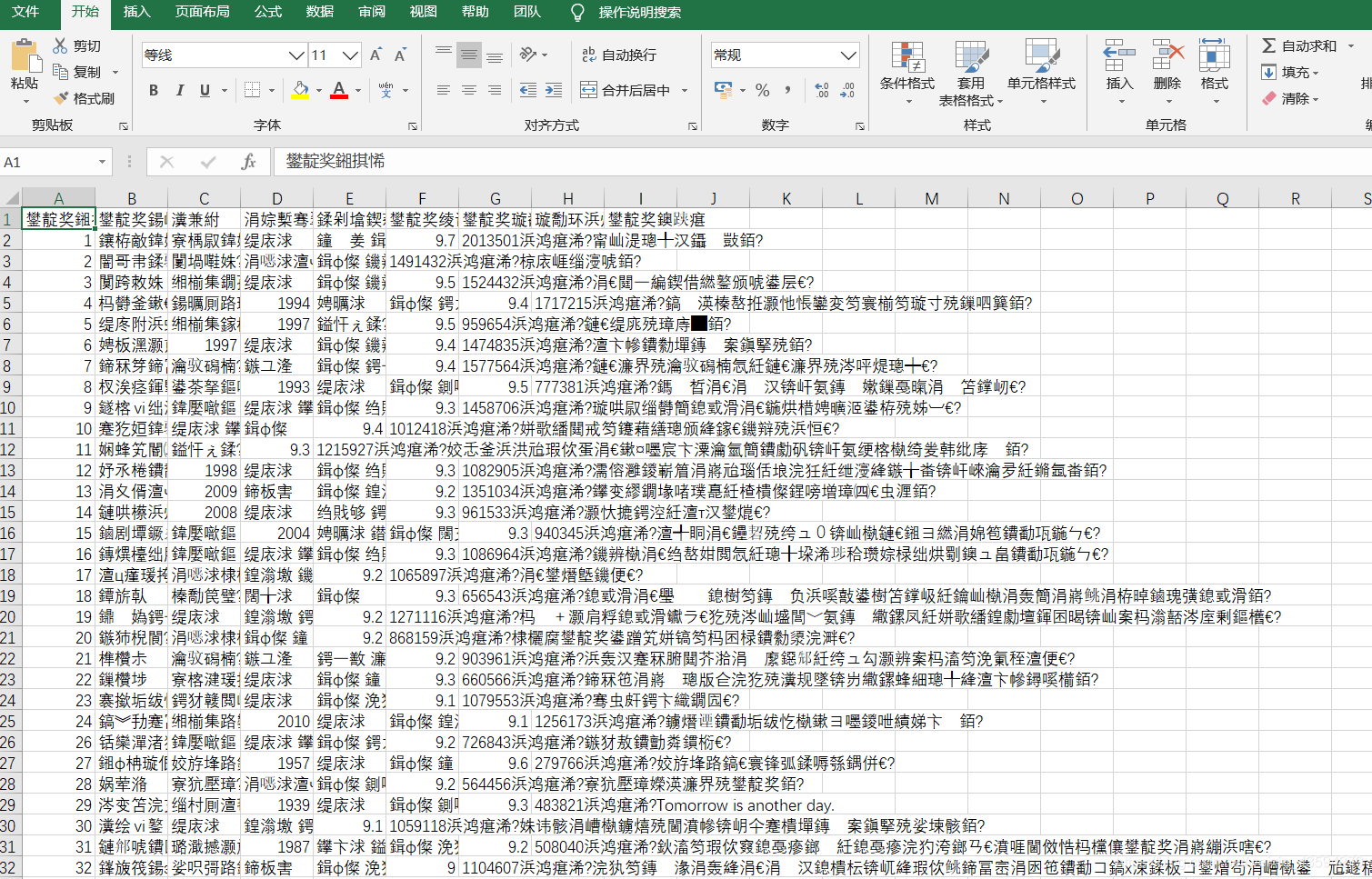
What这是啥?原来是excel打开csv时乱码问题,这里你可以参考解决方案:
csv打开时乱码解决方案
本人亲测方法2有用,效果极佳:
终于完功了!!!
觉得有帮助就点个赞吧!