百度架构师手把手带你零基础实践深度学习——21日学习打卡(第一周第一日)
首先声明,不详细讲解代码部分,主要是针对课程的理解及对作业的分析。(要是有代码相关问题可以私信)

今天开始正式的开始课程的学习,毕然老师今天的讲课视频是从最基础开始说起,很大程度上照顾了还没有了解过深度学习以及Python的同学,对于像我这样有一定基础的同学也是一种对底层记忆的打磨,大家可以通过对波士顿房价这个经典案例的建模预测来进入深度学习的大门,进而增强对人工智能领域深度学习的兴趣。
今天这节课首先从人工智能-机器学习-深度学习三者的关系入手,介绍了深度学习的古往今来;紧接着讲解了“建模八股”的构建模型的一般常用方法;随之而来讲解的就是评价一个模型好坏的损失函数以及毕然老师自创的“盲人下坡法”;最后重点讲解了使用随机梯度下降法实现模型训练(文章最后给出完整代码)。
作业
第一日作业小结:

解析
- 人工智能、机器学习、深度学习三者覆盖的技术范畴是逐层递减的,其中人工智能是最宽泛的概念,机器学习是当前比较有效的一种实现人工智能的方式,深度学习是机器学习算法中最热门的一个分支,其代替了大多数传统的机器学习算法。
- 衡量一个模型预测值和真实值的差距(一个模型好坏)的函数,称为评价函数,亦叫做损失函数。
- 深度学习成功所以来的先决条件是大数据涌现、硬件发展和算法优化,深度学习经历了半个多世纪的发展,从不成熟到成熟,直至2010年后,深度学习的条件成熟。
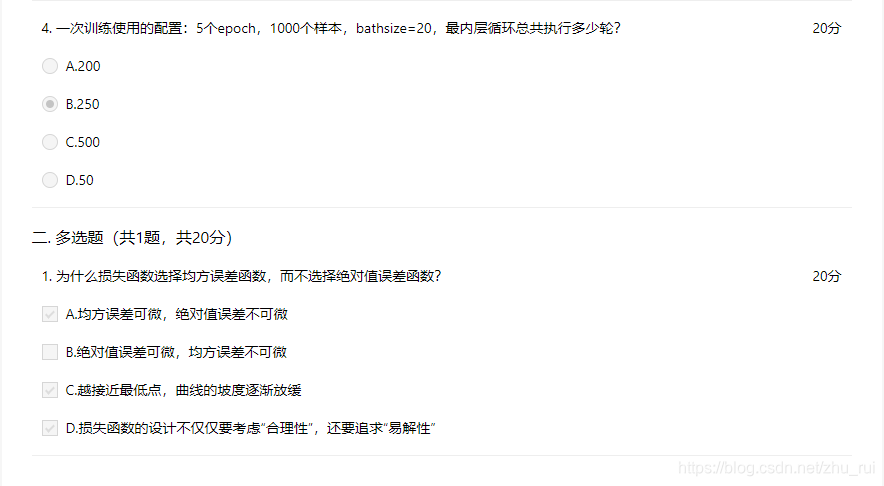
4. batch_size是一个mini-batch的所包含的样本数目,按照batch_size数目逐次从总样本中取出样本,遍历完整个样本算完成一轮训练,称为1epoch。该题目求得是最内层循环,所以先用1000/20算出一轮内层循环50次,在用50*5算出最内层总共循环250次。
5. 关于损失函数选择均方误差函数(MSE),而不选择绝对值误差函数()。一是MSE所有情况下都可微,而绝对误差则不行;二是越接近最低点,曲线斜率越小;三是损失函数的设计不仅仅要考虑“合理性”,还要追求“易解性”。(这里了解就行)
最后的模型代码
import numpy as np
import matplotlib.pyplot as plt
def load_data():
# 从文件导入数据
datafile = './work/housing.data'
data = np.fromfile(datafile, sep=' ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
#np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def gradient(self, x, y):
z = self.forward(x)
N = x.shape[0]
gradient_w = 1. / N * np.sum((z-y) * x, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = 1. / N * np.sum(z-y)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b
def train(self, training_data, num_epoches, batch_size=10, eta=0.01):
n = len(training_data)
losses = []
for epoch_id in range(num_epoches):
# 在每轮迭代开始之前,将训练数据的顺序随机打乱
# 然后再按每次取batch_size条数据的方式取出
np.random.shuffle(training_data)
# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据
mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)]
for iter_id, mini_batch in enumerate(mini_batches):
#print(self.w.shape)
#print(self.b)
x = mini_batch[:, :-1]
y = mini_batch[:, -1:]
a = self.forward(x)
loss = self.loss(a, y)
gradient_w, gradient_b = self.gradient(x, y)
self.update(gradient_w, gradient_b, eta)
losses.append(loss)
print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.
format(epoch_id, iter_id, loss))
return losses
# 获取数据
train_data, test_data = load_data()
# 创建网络
net = Network(13)
# 启动训练
losses = net.train(train_data, num_epoches=50, batch_size=100, eta=0.1)
# 画出损失函数的变化趋势
plot_x = np.arange(len(losses))
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
