RNN
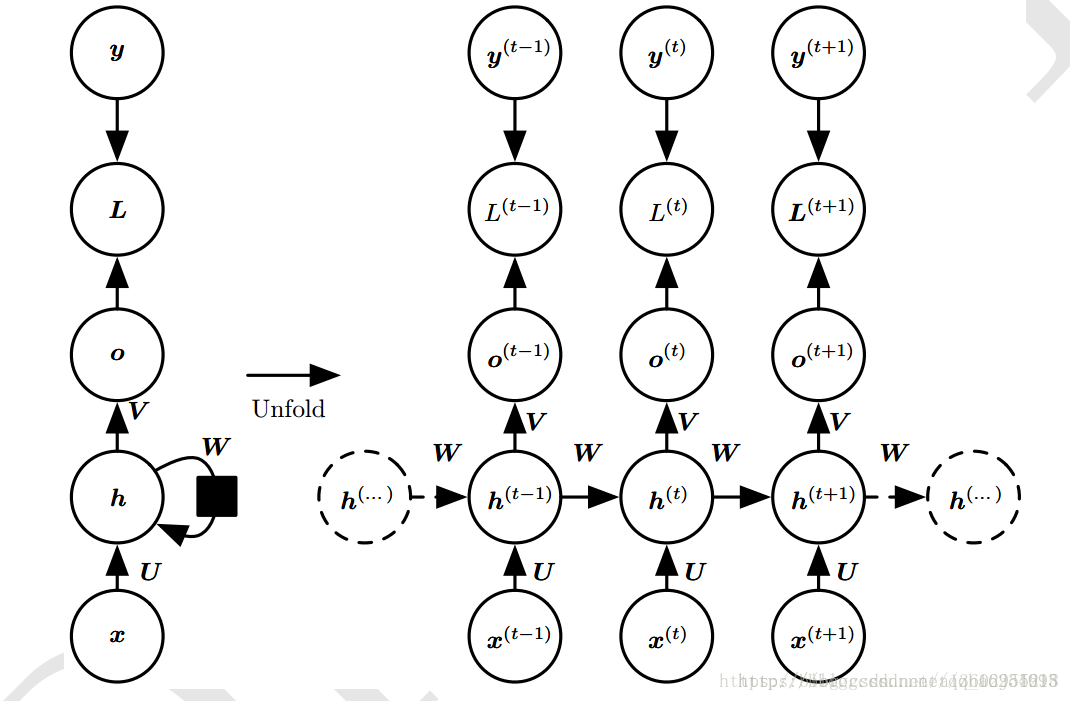
计算公式
由当前输入和前一状态得到当前状态
注意当前状态并不直接输出,而是再通过一个全连接层
代码实现
import numpy as np
X = [1,2]
state = [0.0,0.0]
#状态权重
w_state = np.asarray([0.1,0.2],[0.3,0.4])
#输入权重
w_input = nu.asarray([0.5,0.6])
b_input = np.asarray([0.1,-0.1])
#输出权重
w_output = np.asarray([[1.0],[2.0]])
b_ouput = np.asarray(0.1)
for i in len(X):
#计算新的状态
state = np.tanh(np.dot(state,w_state)+X[i]*w_input+b)
print(state)
#计算输出
out = np.dot(state,w_output)+b_output
print(out)LSTM
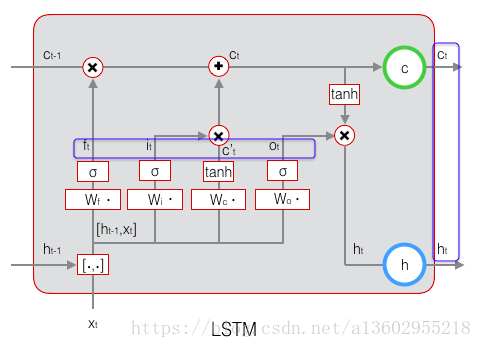
输入值
输入门
遗忘门
新状态
输出门
输出
可以见到,三个门的公式都是一样的
首先前一状态 通过遗忘门选择性遗忘旧的东西,然后输入 通过输入们选择性的输入,
遗忘旧东西的状态与选择性的输入相加,得到新的状态 ,最后这个新的状态除了转递给下一次输入外,
还将通过输出门选择性的输出。
lstm = tf.nn.rnn_cell.BasicLSTMCell(lstm_hidden_size)
代码
import tensorflow as tf
lstm = tf.nn.rnn_cell.BasicLSTMCell(lstm_hidden_size)
state = lstm.zero_state(batch_size,tf.float32)
loss = 0.0
for i in range(num_step):
if i > 0:tf.get_variable_scope().reuse_variables()
lstm_output,state = lstm(current_input,state)
final_output = fully_connected(lstm_output)
loss += calc_loss(final_output,expected_output)LSTM函数的用法
#input输入的格式[batch_size,time_step,embedding]
#hidden_size是指每个time_step输出的大小
#因此outputs的格式为[batch_size,time_step,output_size]
#一般我们取最后一次的输出,outputs[:,-1,:]
#states的格式是[batch_size,embedding]
#包含两个状态,states.c,state.h
lstm = tf.nn.rnn_cell.BasicLSTMCell(hidden_size)
outputs,states = tf.nn.dynamic_rnn(cell,X,dtype=tf.float32)实例
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt
hidden_size = 30
num_layers = 2
seq_size = 10
train_steps = 10000
batch_size = 32
train_examples = 10000
test_examples = 1000
sample_gap = 0.01
#输入一个序列,每10个点预测下一个点
def generate_data(data):
X = []
y = []
for i in range(len(data)-seq_size):
X.append([data[i:i+seq_size]])
y.append([data[i+seq_size]])
return np.array(X,dtype=np.float32),np.array(y,dtype=np.float32)
def lstm_model(X,y,train=False):
#将多个lstm层的列表传入,得到一个多层的RNN网络
cell = tf.nn.rnn_cell.MultiRNNCell([
tf.nn.rnn_cell.BasicLSTMCell(hidden_size) for _ in range(num_layers)
])
# init_state = cell.zero_state(batch_size,dtype=tf.float32)
#输出rnn网络的结果,维度是[batch_size,time,hidden_size]
#我们只关心最后一次输出的结果,因此取最后一次的结果
# print(X.shape)
outputs,_ = tf.nn.dynamic_rnn(cell,X,dtype=tf.float32)
output = outputs[:,-1,:]
#添加一个全连接层
pred = tf.contrib.layers.fully_connected(output,1,activation_fn=None)
#若不是训练,则直接输出结果
if not train:
return pred,None,None
#使用mes损失函数
loss = tf.losses.mean_squared_error(labels=y,predictions=pred)
train_op = tf.contrib.layers.optimize_loss(
loss,tf.train.get_global_step(),
optimizer='Adagrad',learning_rate=0.1
)
return pred,loss,train_op
def train(sess,train_x,train_y):
#使用Dataset读取数据
dataset = tf.data.Dataset.from_tensor_slices((train_x,train_y))
dataset = dataset.repeat().shuffle(1000).batch(batch_size)
X,y = dataset.make_one_shot_iterator().get_next()
# print(X.shape)
with tf.variable_scope('model'):
pred,loss,train_op = lstm_model(X,y,True)
sess.run(tf.global_variables_initializer())
for i in range(train_steps):
_,loss_val = sess.run([train_op,loss])
if i % 100 == 0:
print('step:{},loss:{}'.format(i,loss_val))
def eval(sess,test_x,test_y):
dataset = tf.data.Dataset.from_tensor_slices((test_x,test_y))
dataset = dataset.batch(1)
X,y = dataset.make_one_shot_iterator().get_next()
#重用已存在的变量
with tf.variable_scope('model',reuse=True):
pred,_,_= lstm_model(X,[0.0],False)
predictions = []
labels = []
for i in range(test_examples):
p,l = sess.run([pred,y])
predictions.append(p)
labels.append(l)
#squeeze函数的作用是除去维度为1的维度
#如[[1],[2],[3]]是一个维度为[3,1]的数组,除去维度为1的维度后
#变成一个维度为[3]数组[1,2,3]
predictions = np.asarray(predictions).squeeze()
labels = np.asarray(labels).squeeze()
#由于这里使用的不是tf,因此只能自己算
loss = np.sqrt(((predictions-labels)**2).mean(axis=0))
print('loss:{}'.format(loss))
plt.figure()
plt.plot(predictions,label='predictions')
plt.plot(labels,label='labels')
plt.legend()
plt.show()
if __name__ == '__main__':
test_start = (train_examples+seq_size)*sample_gap
test_end = test_start+(test_examples+seq_size)*sample_gap
train_x,train_y = generate_data(np.sin(np.linspace(0,test_start,train_examples+seq_size,dtype=np.float32)))
test_x,test_y = generate_data(np.sin(np.linspace(test_start,test_end,test_examples+seq_size,dtype=np.float32)))
with tf.Session() as sess:
train(sess,train_x,train_y)
eval(sess,test_x,test_y)