本节目录
1 DataFLow编程模型
2 创建Maven项目 搭建Flink开发环境
3 java版WordCount
4 Scala版WordCount
5 运行监控
6 windows和linux开启网络端口监听服务
1 DataFLow编程模型
Flink基本概念:数据流编程模型(DataFlow Programming Model)
Dataflow计算模型:希望从编程模型的源头上,统一解决传统的流式和批量这两种计算语意所希望处理的问题。
Flink 提供了不同级别的编程抽象,通过调用抽象的数据集用算子构建 DataFlow 就可以实现对分布式的数据进行流式计算和离线计算。DataSet是批处理的抽象数据集,DataStream是流式计算的抽象数据集,他们的方法都分别是Source、Transformation、Sink .
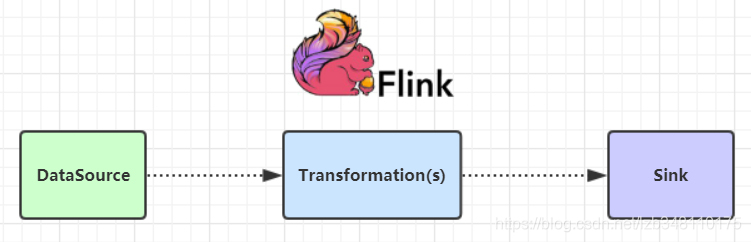
Source:主要负责数据的读取(即:数据的来源)Transformation:主要负责对数据的转换操作Sink:负责最终计算好的结果数据的输出

2 创建Maven项目 搭建Flink开发环境
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>doit-flink</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.9.1</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<scala.version>2.11.12</scala.version>
</properties>
<dependencies>
<!-- Apache Flink dependencies -->
<!-- These dependencies are provided, because they should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<!-- Scala Library, provided by Flink as well. -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.12</artifactId>
<version>1.7.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
<!-- Add connector dependencies here. They must be in the default scope (compile). -->
<!-- Example:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
-->
<!-- Add logging framework, to produce console output when running in the IDE. -->
<!-- These dependencies are excluded from the application JAR by default. -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com._51doit.StreamingJob</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<!-- Eclipse Scala Integration -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.8</version>
<configuration>
<downloadSources>true</downloadSources>
<projectnatures>
<projectnature>org.scala-ide.sdt.core.scalanature</projectnature>
<projectnature>org.eclipse.jdt.core.javanature</projectnature>
</projectnatures>
<buildcommands>
<buildcommand>org.scala-ide.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<classpathContainers>
<classpathContainer>org.scala-ide.sdt.launching.SCALA_CONTAINER</classpathContainer>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
</classpathContainers>
<excludes>
<exclude>org.scala-lang:scala-library</exclude>
<exclude>org.scala-lang:scala-compiler</exclude>
</excludes>
<sourceIncludes>
<sourceInclude>**/*.scala</sourceInclude>
<sourceInclude>**/*.java</sourceInclude>
</sourceIncludes>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>1.7</version>
<executions>
<!-- Add src/main/scala to eclipse build path -->
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>src/main/scala</source>
</sources>
</configuration>
</execution>
<!-- Add src/test/scala to eclipse build path -->
<execution>
<id>add-test-source</id>
<phase>generate-test-sources</phase>
<goals>
<goal>add-test-source</goal>
</goals>
<configuration>
<sources>
<source>src/test/scala</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<!-- This profile helps to make things run out of the box in IntelliJ -->
<!-- Its adds Flink's core classes to the runtime class path. -->
<!-- Otherwise they are missing in IntelliJ, because the dependency is 'provided' -->
<profiles>
<profile>
<id>add-dependencies-for-IDEA</id>
<activation>
<property>
<name>idea.version</name>
</property>
</activation>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>compile</scope>
</dependency>
</dependencies>
</profile>
</profiles>
</project>3 java版WordCount
/**
* @Auther: 多易教育-行哥
* @Date: 2020/6/14
* @Description:
*/
public class WordCount {
public static void main(String[] args) throws Exception {
// 1 创建一个flink处理实时数据的环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2 创建datastream ,也就是我们所说的Source数据源
// 参数一 网络数据源的主机 参数二 端口号
DataStreamSource<String> sources = env.socketTextStream("lx01", 8888);
// 3处理接收的数据 组装成(单词,1)
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = sources.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = line.split("\\s+");
for (String word : words) {
Tuple2<String, Integer> tp = Tuple2.of(word, 1);
collector.collect(tp);
}
}
});
//4 安装单词分组 将分组后的单词的个数累加
SingleOutputStreamOperator<Tuple2<String, Integer>> res = wordAndOne.keyBy(0).sum(1);
//5 打印结果
res.print() ;
env.execute("java_flink-stream-word_count") ;
}
}
4 Scala版WordCount
/**
* @Auther: 多易教育-行哥
* @Date: 2020/6/14
* @Description:
*/
object ScalaWordCount {
def main(args: Array[String]): Unit = {
// 使用scala的API开发flink代码需要导入scala
import org.apache.flink.api.scala._
// 创建实时处理对象
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 数据源设置为 网络流
val ds: DataStream[String] = env.socketTextStream("lx01", 8888, '\n', 200)
// 处理每行数据 切割 组装 累加
val ds2: DataStream[(String, Int)] = ds.flatMap(_.split("\\s+")).map((_, 1)).keyBy(0).sum(1)
// 打印结果
ds2.print()
// 执行
env.execute("scala-flink-word_count")
}
}5 运行监控
nc -lk 8888 启动网络客户端输入内容 [root@lx01 ~]# nc -lk 8888
运行程序 在idea中直接运行 控制台打印内容

6 windows和linux开启网络端口监听服务
6.1 windows
Windows本身是不支持 nc 端口监听的。但是我们可以通过下载 netcat 来是解决这个问题。下载地址:netcat
下载后,进行解压,并将解压后目录下的所有文(.txt 文件除外),复制到 C:\Windows\System32 目录下,我们便可以在 cmd 命令行使用 nc 命令了。

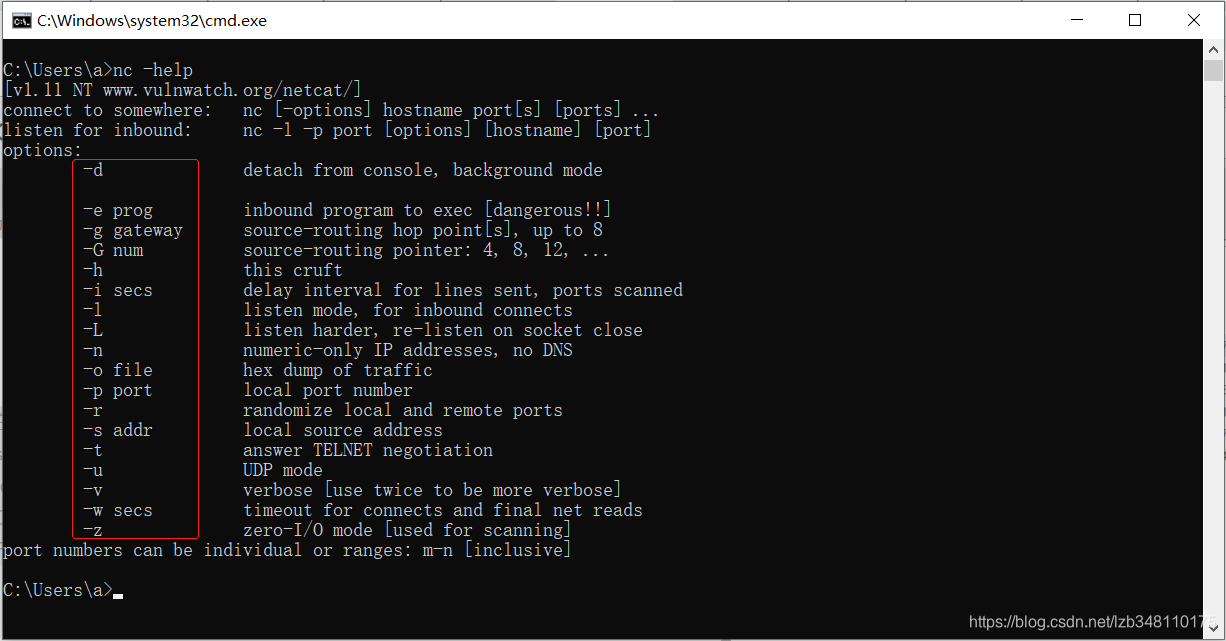
我们通过命令:nc -help可以查看该命令的使用描述。
使用命令:nc -lp 8888即可开启监听 8888 端口号

6.2 linux
Linux 开启端口监听,也是使用nc命令,如果出现-bash: nc: command not found,我们通过命令:yum install nc 安装 nc 即可。
通过命令:nc -help,可以来查看 nc 命令的使用描述。
使用命令:nc -lk 8888即可开启监听 8888 端口号