本节目录
- idea实例代码
- maven项目打包
- 将jar包提交到flink集群
1 idea实例代码
1.1 java版
package com._51doit.wc;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @Auther: 多易教育-行哥
* @Date: 2020/6/14
* @Description:
*/
public class WordCount {
public static void main(String[] args) throws Exception {
// 1 创建一个flink处理实时数据的环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2 创建datastream ,也就是我们所说的Source数据源
// 参数一 网络数据源的主机 参数二 端口号
DataStreamSource<String> sources = env.socketTextStream("lx01", 8888);
// 3处理接收的数据 组装成(单词,1)
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = sources.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = line.split("\\s+");
for (String word : words) {
Tuple2<String, Integer> tp = Tuple2.of(word, 1);
collector.collect(tp);
}
}
});
//4 安装单词分组 将分组后的单词的个数累加
SingleOutputStreamOperator<Tuple2<String, Integer>> res = wordAndOne.keyBy(0).sum(1);
//5 打印结果
res.print() ;
env.execute("java_flink-stream-word_count") ;
}
}
1.2 scala版
package com._51doit.wc
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
/**
* @Auther: 多易教育-行哥
* @Date: 2020/6/14
* @Description:
*/
object ScalaWordCount {
def main(args: Array[String]): Unit = {
// 使用scala的API开发flink代码需要导入scala
import org.apache.flink.api.scala._
// 创建实时处理对象
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 数据源设置为 网络流
val ds: DataStream[String] = env.socketTextStream("lx01", 8888, '\n', 200)
// 处理每行数据 切割 组装 累加
val ds2: DataStream[(String, Int)] = ds.flatMap(_.split("\\s+")).map((_, 1)).keyBy(0).sum(1)
// 打印结果
ds2.print()
// 执行
env.execute("scala-flink-word_count")
}
}
2 maven项目打包
使用 Maven 提供的 package 进行打包即可。

如下红色圈起来的是带依赖的jar包
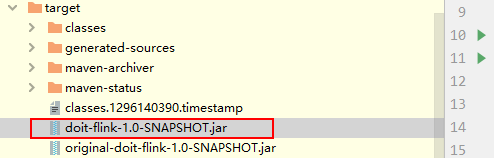
3 将jar包提交到flink集群
3.1 将jar包上传到linux集群中

3.2 执行命令提交程序
/opt/apps/flink-1.9.3/bin/flink run -m lx01:8081 -p 6 -c com._51doit.wc.ScalaWordCount /doit-flink-1.0-SNAPSHOT.jar --hostname lx01 --port 8888
Starting execution of program
查看页面中的任务