1 EventTime + WaterMarks(延迟机制)处理实时数据
接下来,我们从并行Source 和 非并行Source 两个方向,来使用 EventTime 处理实时数据。(接下来示例,设置延迟为0s,即不延迟)
1.1 非并行Source
非并行Source,以 socketTextStream为例来介绍 Flink使用 EventTime 处理实时数据。
1.1.1 代码实现
/**
* TODO 非并行Source EventTime
*
* @author 多易教育-行哥
* @Date 2020-06-18
*/
public class EventTimeDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置EventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//读取source,并指定(1581490623000,Mary,3)中哪个字段为EventTime时间
//WaterMarks:是Flink中窗口延迟触发的机制。Time.seconds(0)表示无延迟。
SingleOutputStreamOperator<String> source = env.socketTextStream("localhost", 8888).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(0)) {
@Override
public long extractTimestamp(String line) {
String[] split = line.split(",");
return Long.parseLong(split[0]);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> mapOperator = source.map(line -> {
String[] split = line.split(",");
return Tuple2.of(split[1], Integer.parseInt(split[2]));
}).returns(Types.TUPLE(Types.STRING,Types.INT));
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = mapOperator.keyBy(0);
//EventTime滚动窗口
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowedStream = keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(5)));
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = windowedStream.sum(1);
sum.print();
env.execute("EventTimeDemo");
}
}
1.1.2 结果演示
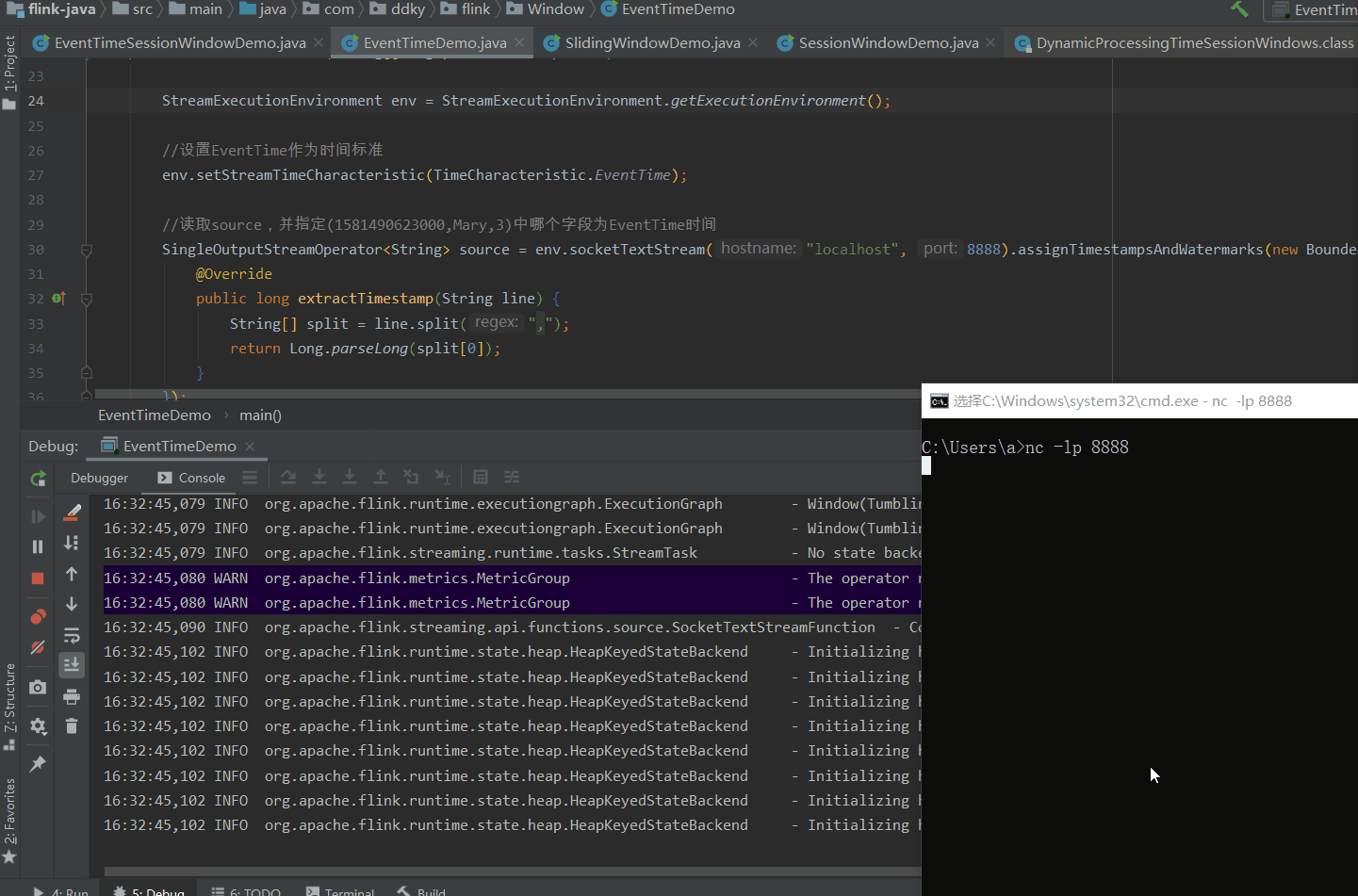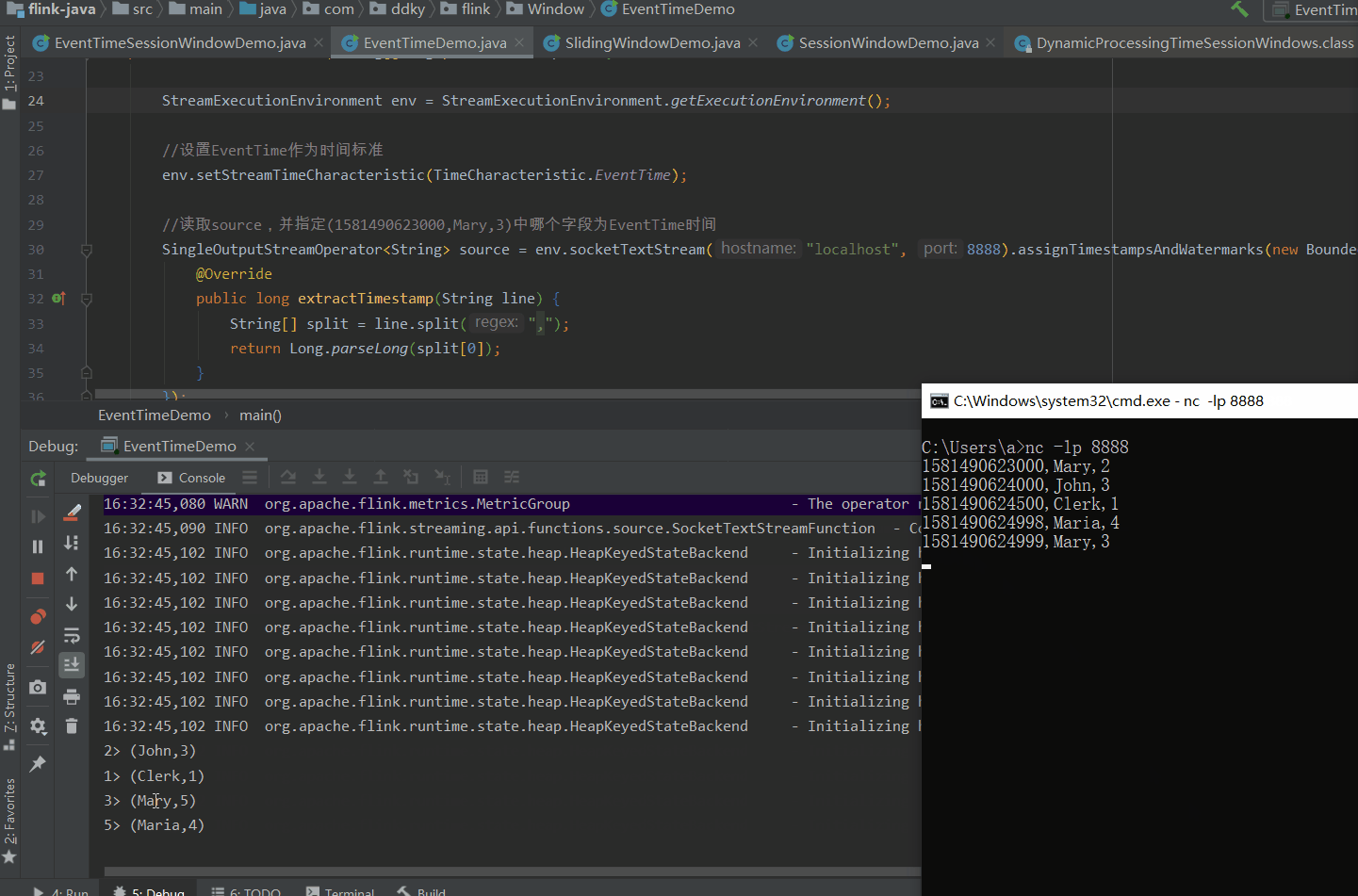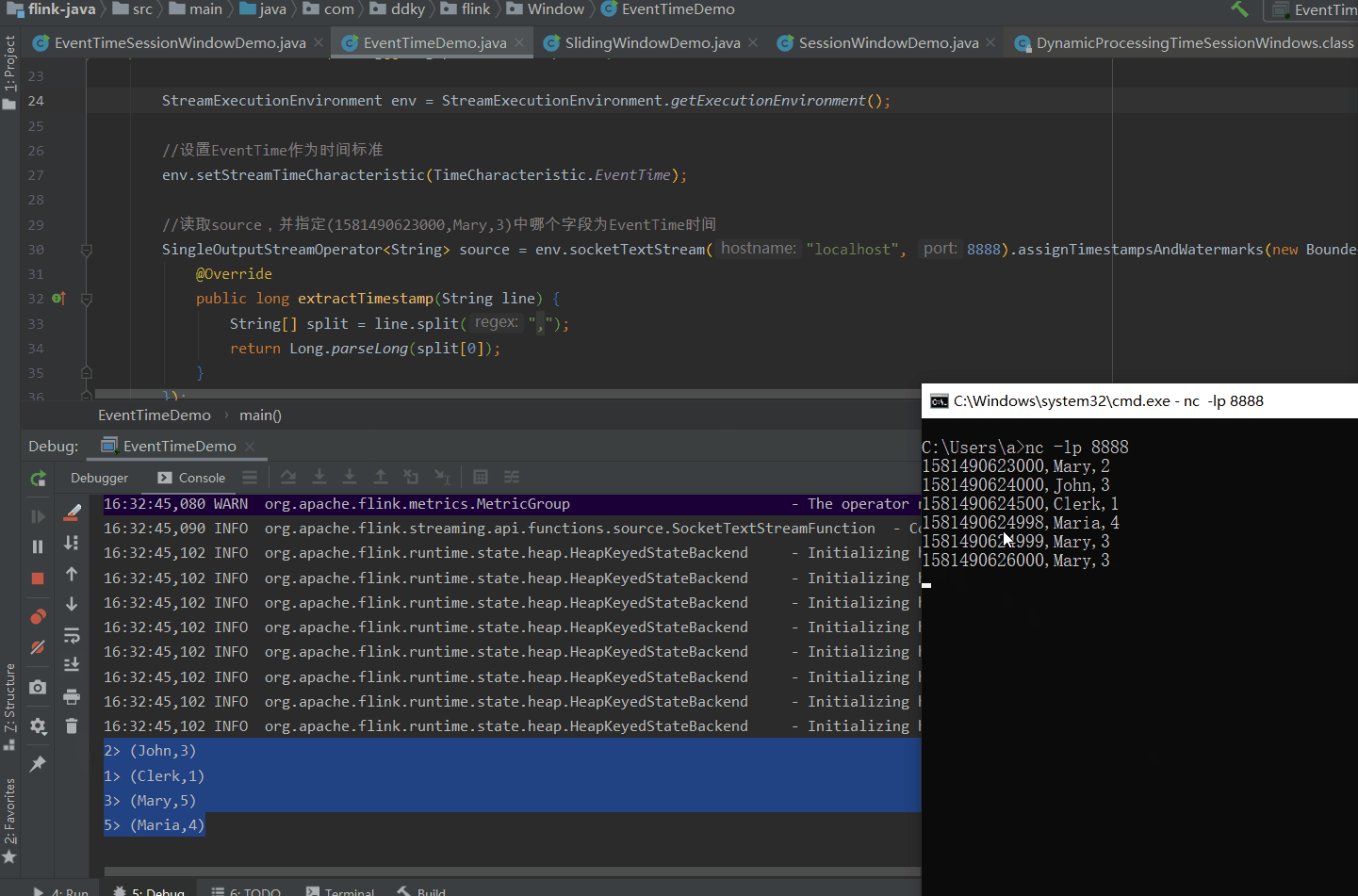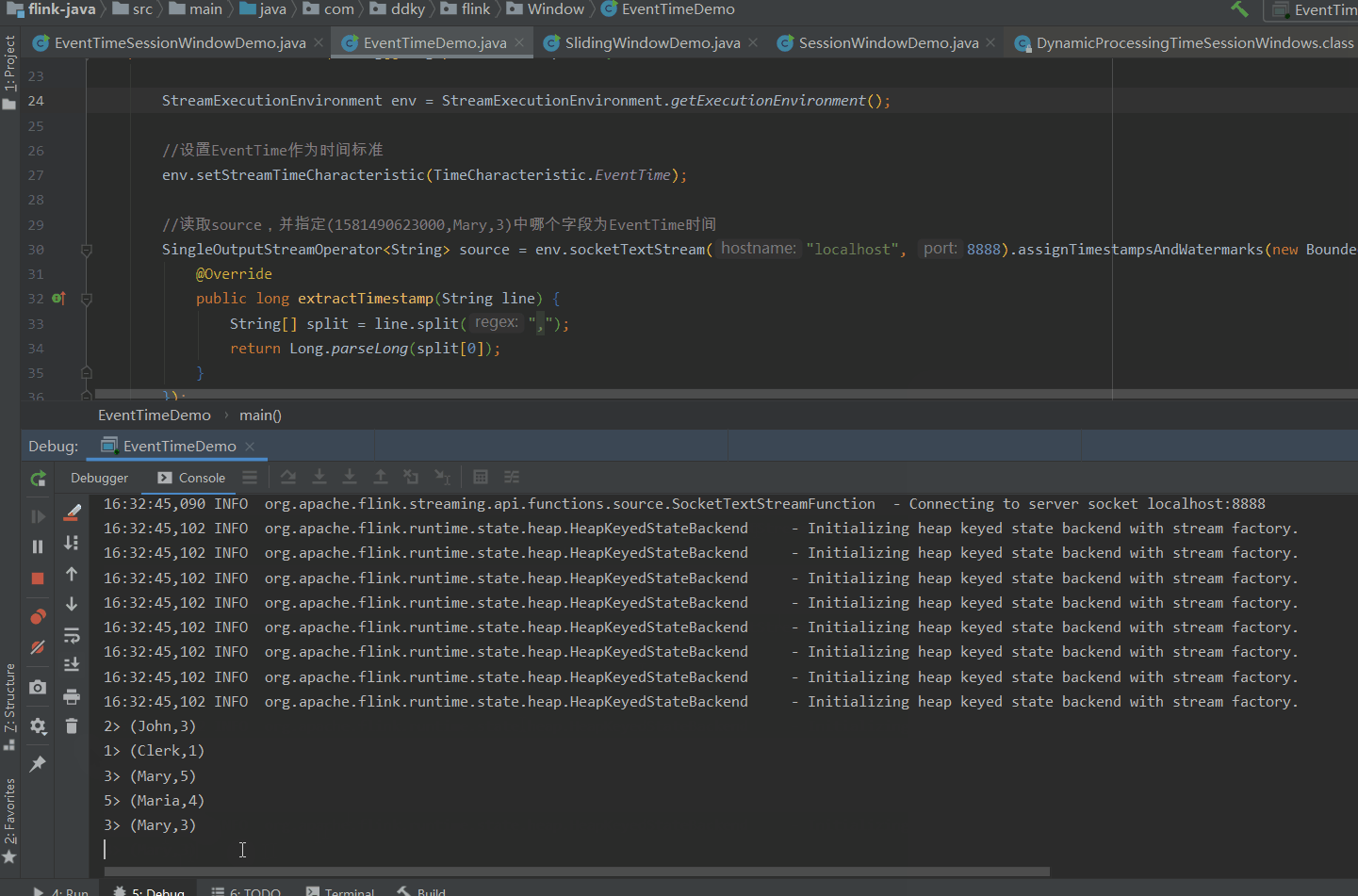
备注: (1581490623000转换后为:2020-02-12 14:57:03
1581490624000转换后为:2020-02-12 14:57:04)
当我们在Socket中输入如下数据:
1581490623000,Mary,2
1581490624000,John,3
1581490624500,Clerk,1
1581490624998,Maria,4
1581490624999,Mary,3
1581490626000,Mary,3
1581490630800,Steve,3 (2020-02-12 14:57:10.800)窗口定义的时间是:含头不含尾。即:[0,5),
图片解析:(我们定义滚动窗口为5s,我们分析图片发现到4998时,并没有输出内容。因为4998还没超过5s,窗口规定是>=临界值时触发,所以当我们输入4999临界时,我们发现输出内容了,说明一个窗口滚动完成,输出内容包含4999这个时间的值;当输入6000时,6000在[5,10)之间没有>10,所以不输出。输入30800【2020-02-12 14:57:10.800)】,已经超过10s,所以结果只输出1个 (Mary,3),因为Steve已经被分到另一个窗口了)还有一个问题,就是:当输入到 4999 时,只是Mary这个分组满足5s这个条件,但是其它分组John,Clerk 等也同步输出结果了。显然这不符合逻辑。为什么会出现这种情况呢?是因为SocketStream 是非并行数据流,所以才会出现这样子的结果。(接下来我们就是用并行数据流KafkaSource来分析)
1.2 并行Source
并行Source,以 KafkaSouce 为例来介绍 Flink使用 EventTime 处理实时数据。
1.2.1 代码
并行KafkaSource EventTime示例(读取 topic为 window_demo中的消息),代码如下所示:
/**
* TODO 并行KafkaSource EventTime示例(读取 topic为 window_demo中的消息)
*
* @author 多易教育-行哥
* @Date 2020-06-18
*/
public class EventTimeDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置EventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//Kafka props
Properties properties = new Properties();
//指定Kafka的Broker地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.204.210:9092,192.168.204.211:9092,192.168.204.212:9092");
//指定组ID
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "flinkDemoGroup");
//如果没有记录偏移量,第一次从最开始消费
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer("window_demo", new SimpleStringSchema(), properties);
//2.通过addSource()方式,创建 Kafka DataStream
//读取source,并指定(1581490623000,Mary,3)中哪个字段为EventTime时间
SingleOutputStreamOperator<String> source = env.addSource(kafkaSource).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(0)) {
@Override
public long extractTimestamp(String line) {
String[] split = line.split(",");
return Long.parseLong(split[0]);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> mapOperator = source.map(line -> {
String[] split = line.split(",");
return Tuple2.of(split[1], Integer.parseInt(split[2]));
}).returns(Types.TUPLE(Types.STRING,Types.INT));
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = mapOperator.keyBy(0);
//EventTime滚动窗口
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowedStream = keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(5)));
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = windowedStream.sum(1);
sum.print();
env.execute("EventTimeDemo");
}
}
1.2.2 测试
创建 Topic 命令如下:
bin/kafka-topics.sh --create --zookeeper 192.168.204.210:2181,192.168.204.211:2181,192.168.204.212:2181 --replication-factor 1 --partitions 3 --topic window_demo
(特别注意一下:此处创建了3个分区)
创建 Topic 成功截图

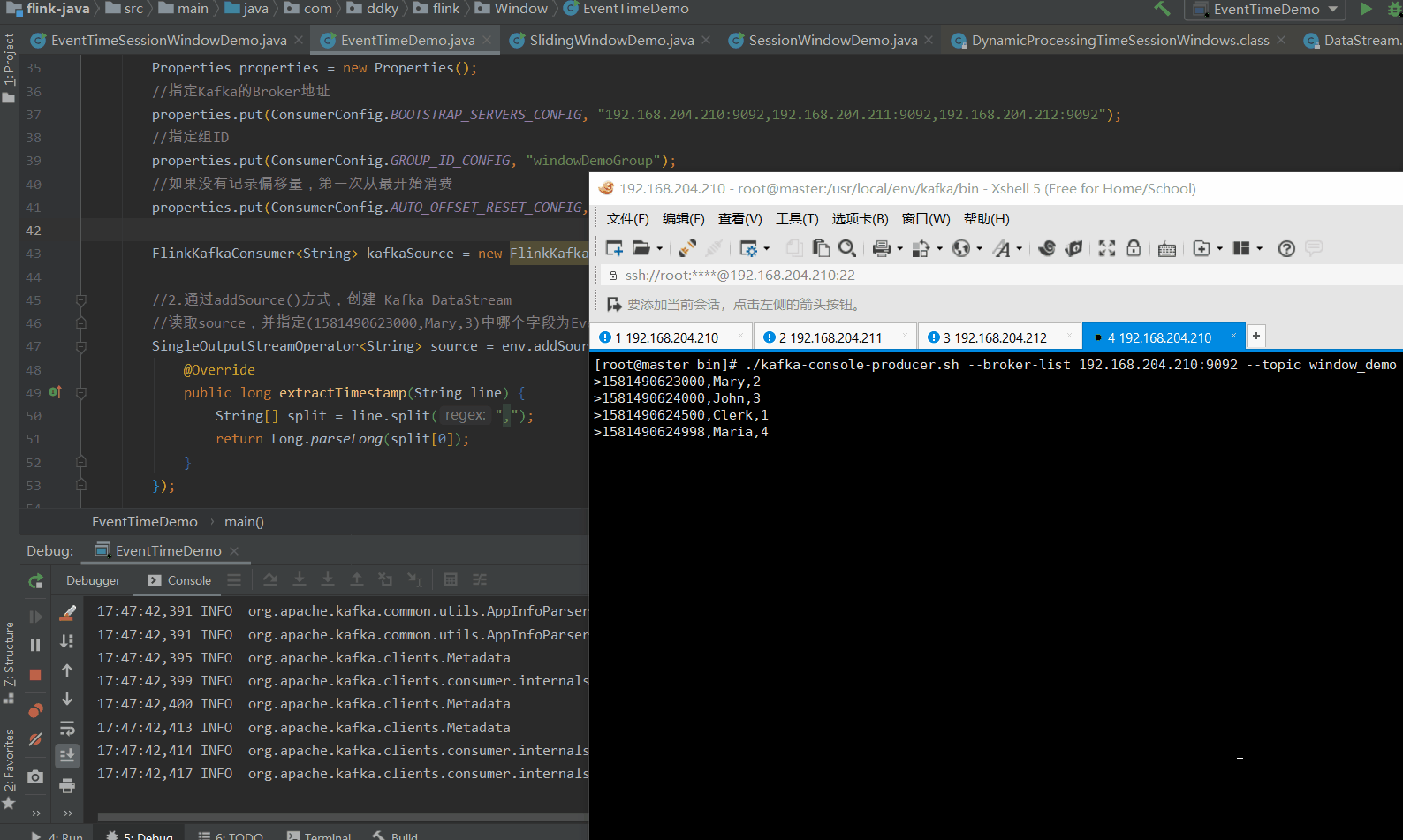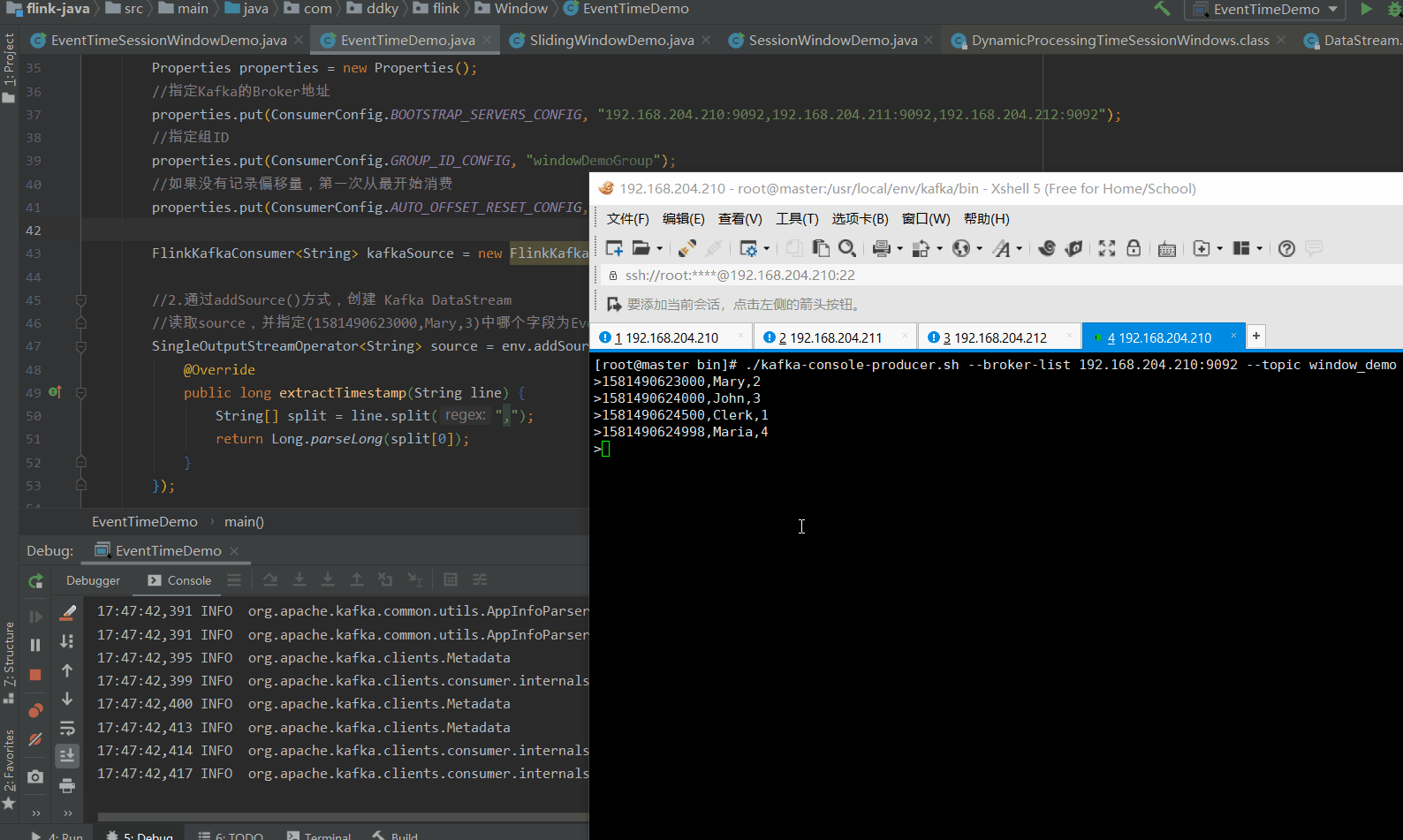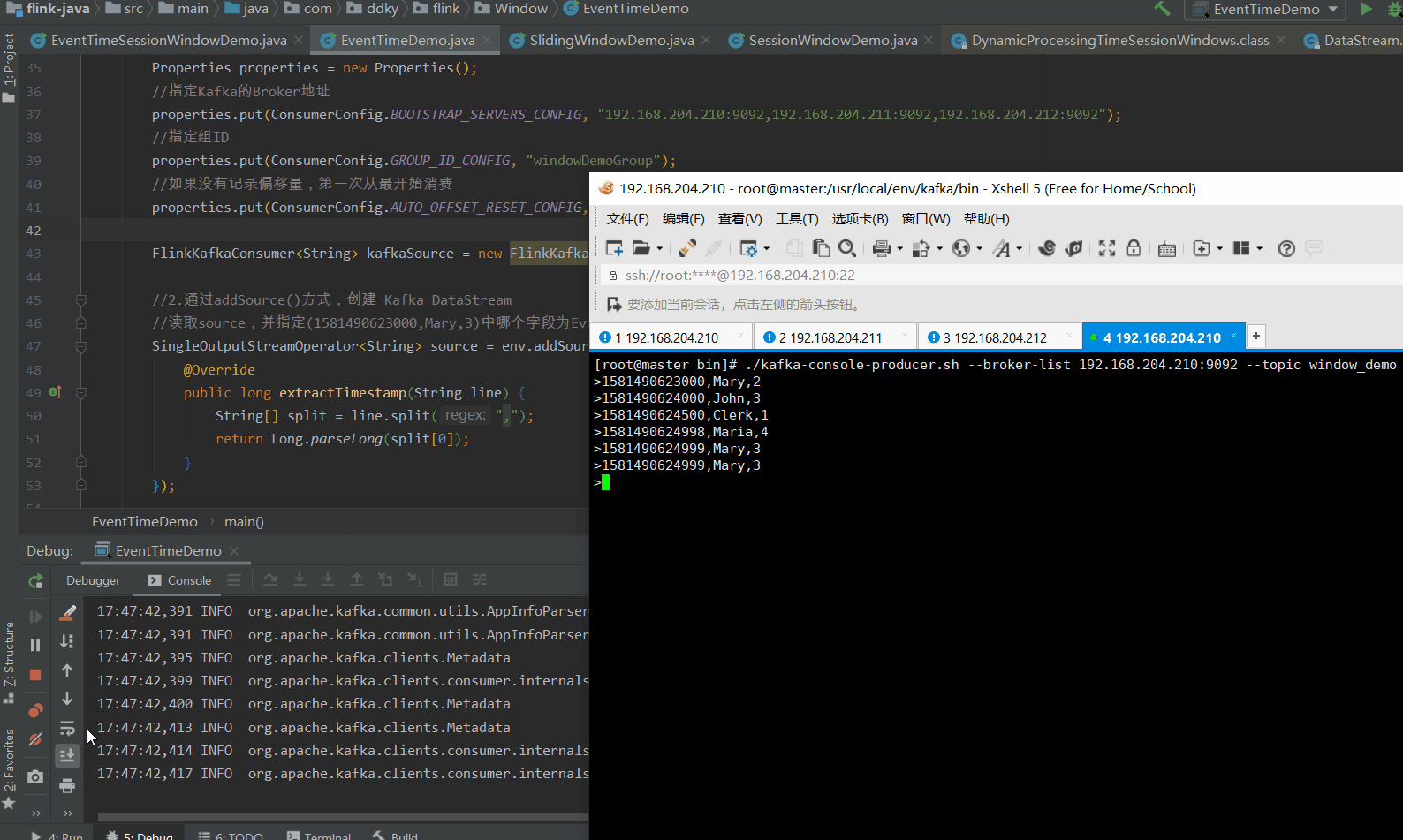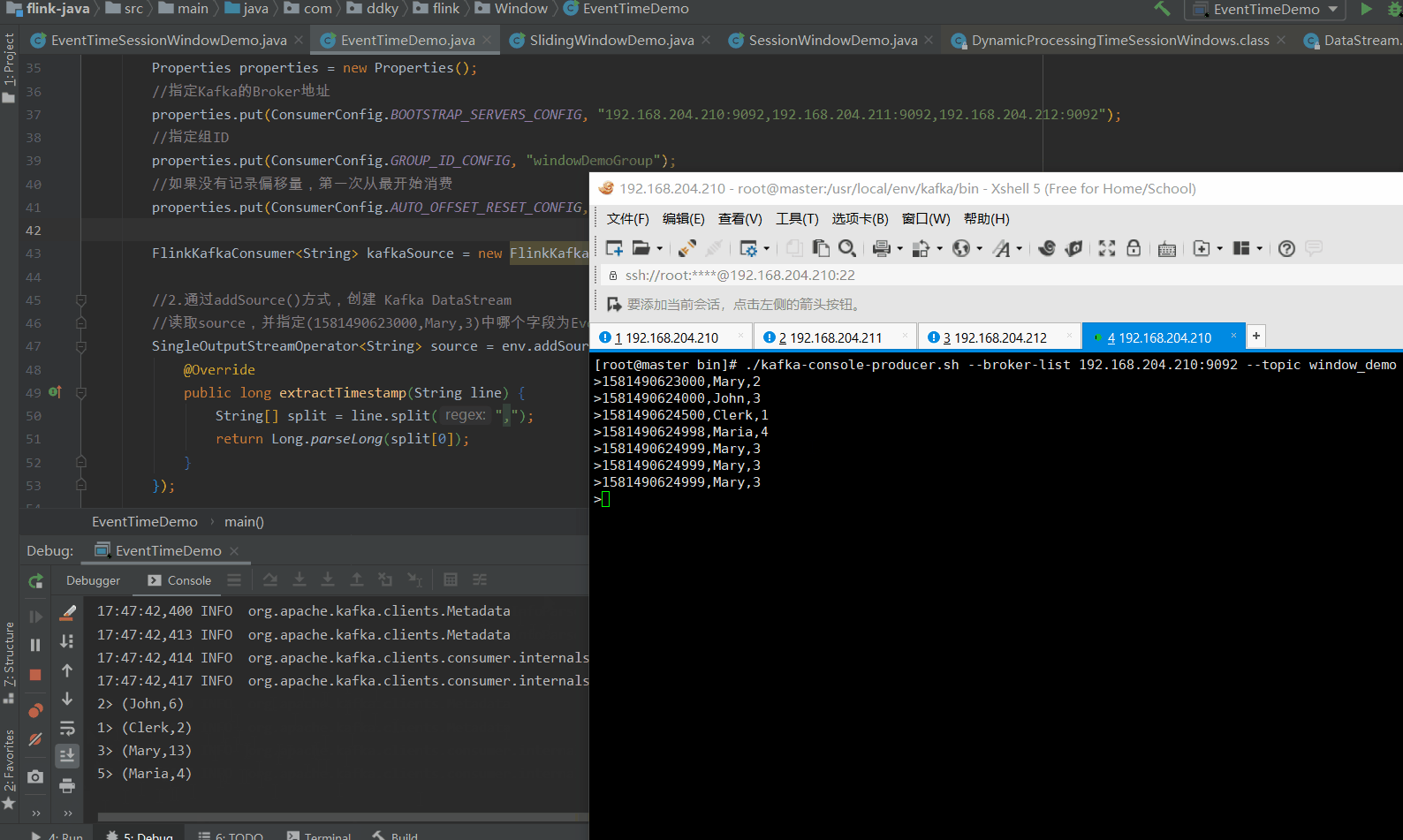
使用命令,写入数据到Kafka:
bin/kafka-console-producer.sh --broker-list 192.168.204.210:9092 --topic window_demo
使用命令写入以下数据:
1581490623000,Mary,2
1581490624000,John,3
1581490624500,Clerk,1
1581490624998,Maria,4
1581490624999,Mary,3
1.2.3 结果
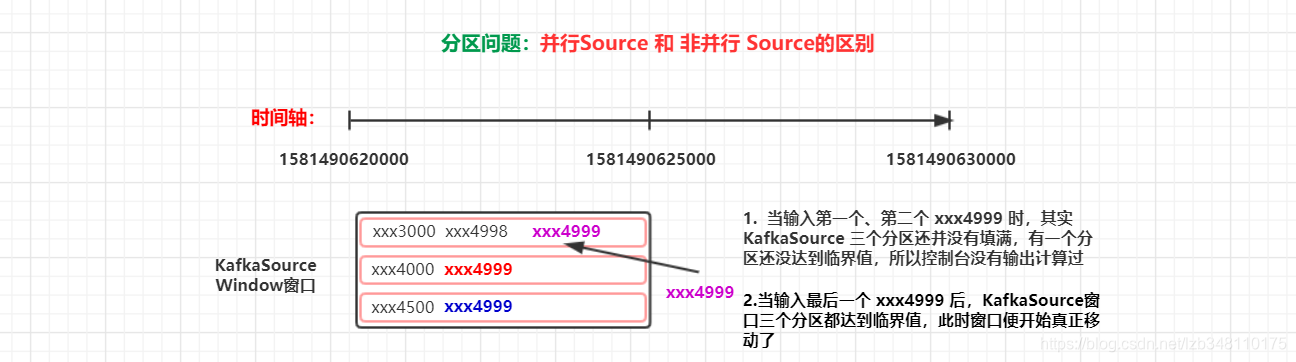
1.3 分析总结
在1.并行Source一例中,当我们输入1581490624999,Mary,3时,我们看到控制台会直接帮我们输出计算结果。
但是,在使用 KafkaSource 时,我们连续输入了 3次1581490624999,Mary,3,我们才看到控制台帮我们输出计算了结果。
那这是为什么呢?这是 并行Source 和 非并行Source 的原因导致的(这里涉及到 KafkaSource 创建的 topic,有 3 个分区的原因,如下图所示)