1.准备工作
1.1 版本信息
Maven版本:3.0.4 及以上
JDK版本:JDK 8
1.2 使用 Maven 命令创建 Flink 项目模板:
如果 maven 本地没有所依赖的 jar 包,则需要网络支持。
在 cmd 命令行,执行如下命令:
mvn archetype:generate
-DarchetypeGroupId=org.apache.flink
-DarchetypeArtifactId=flink-quickstart-java
-DarchetypeVersion=1.9.1
-DgroupId=com.demo.flink(groupId: 此处可自定义)
-DartifactId=flink-java(项目名: 此处可自定义)
-Dversion=1.0(版本号: 此处可自定义)
-Dpackage=com.demo.flink(包名: 此处可自定义)
-DinteractiveMode=false
备注:
使用以上命令创建 Flink项目模板,主要是参考里面的 pom.xml 文件;你也可以自行创建 Maven 工程,然后将已有的 pom.xml 文件 copy 过去即可。
2.DataFlow 编程模型介绍
Flink基本概念:数据流编程模型(DataFlow Programming Model)
Dataflow计算模型:希望从编程模型的源头上,统一解决传统的流式和批量这两种计算语意所希望处理的问题。
Flink 提供了不同级别的编程抽象,通过调用抽象的数据集用算子构建 DataFlow 就可以实现对分布式的数据进行流式计算和离线计算。DataSet是批处理的抽象数据集,DataStream是流式计算的抽象数据集,他们的方法都分别是Source、Transformation、Sink
Source:主要负责数据的读取(即:数据的来源)
Transformation:主要负责对数据的转换操作
Sink:负责最终计算好的结果数据的输出
3.实时 WordCount编写
/**
* TODO 实时WorldCount计算
*
* @author liuzebiao
* @Date 2020-02-04 10:37
*/
public class StreamWordCount {
public static void main(String[] args) throws Exception {
//1.创建一个 flink steam 程序的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.使用StreamExecutionEnvironment创建DataStream
//Source(可以有多个Source)
//Socket 监听本地端口8888(亦可监听linux环境下的某一台机器)
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
//Transformation(s)对数据进行处理操作
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
//切分
String[] words = line.split(" ");
//循环,
for (String word : words) {
//将每个单词与 1 组合,形成一个元组
Tuple2<String, Integer> tp = Tuple2.of(word, 1);
//将组成的Tuple放入到 Collector 集合,并输出
out.collect(tp);
}
}
});
//进行分组聚合(keyBy:将key相同的分到一个组中)
SingleOutputStreamOperator<Tuple2<String, Integer>> sumed = wordAndOne.keyBy(0).sum(1);
//Transformation 结束
//3.调用Sink (Sink必须调用)
sumed.print();
//启动(这个异常不建议try...catch... 捕获,因为它会抛给上层flink,flink根据异常来做相应的重启策略等处理)
env.execute("StreamWordCount");
}
}
4.开启端口监听
如果你了解如何开启端口监听,点击如下链接:Windows/Linux开启端口监听
5.执行代码
①开启 8888 端口监听;
②开始运行代码或 使用快捷键Shift + F10执行;
③然后再命令行,输入 单词,在控制台就可以看到实时计算的结果。
测试图如下: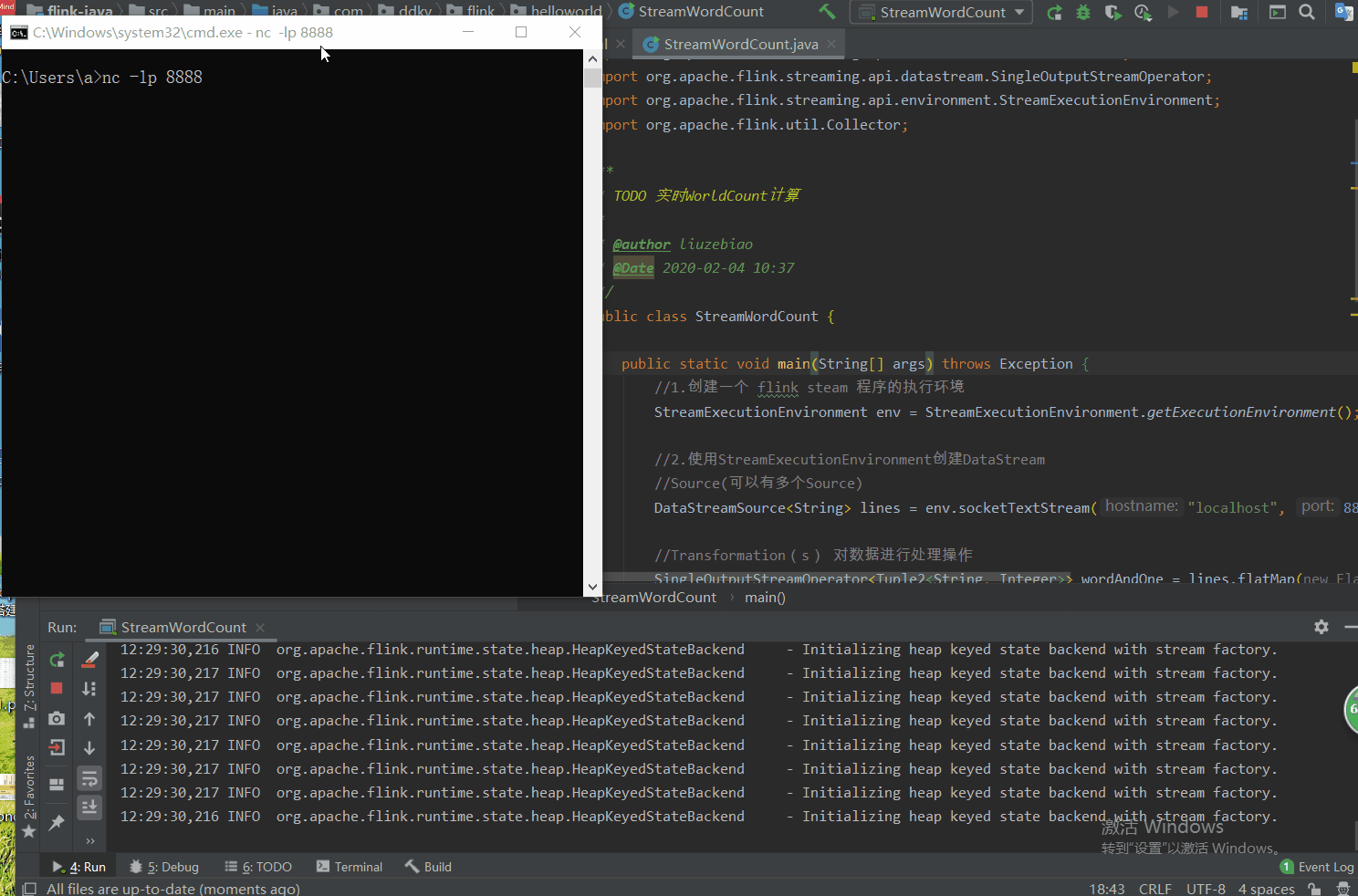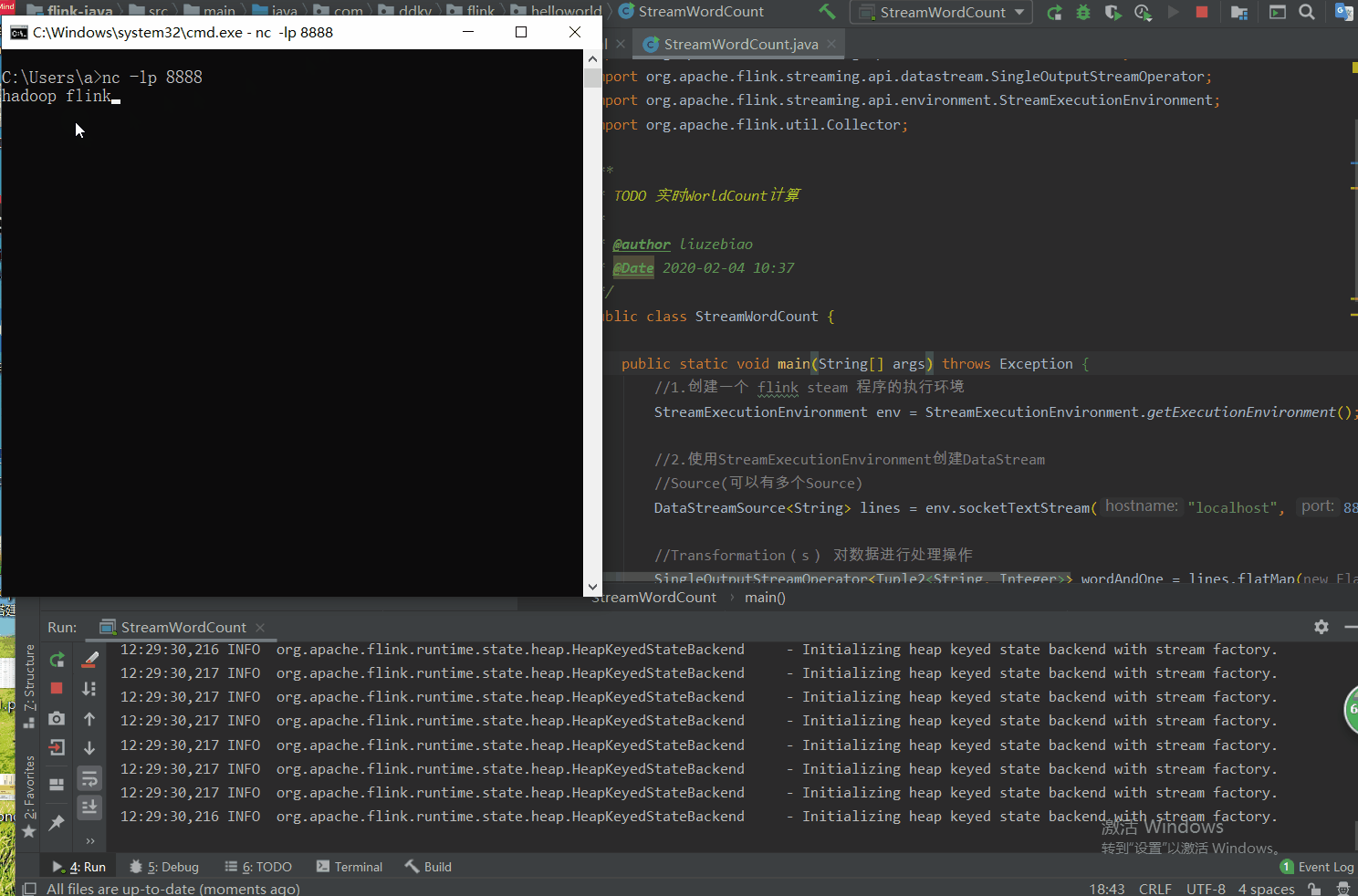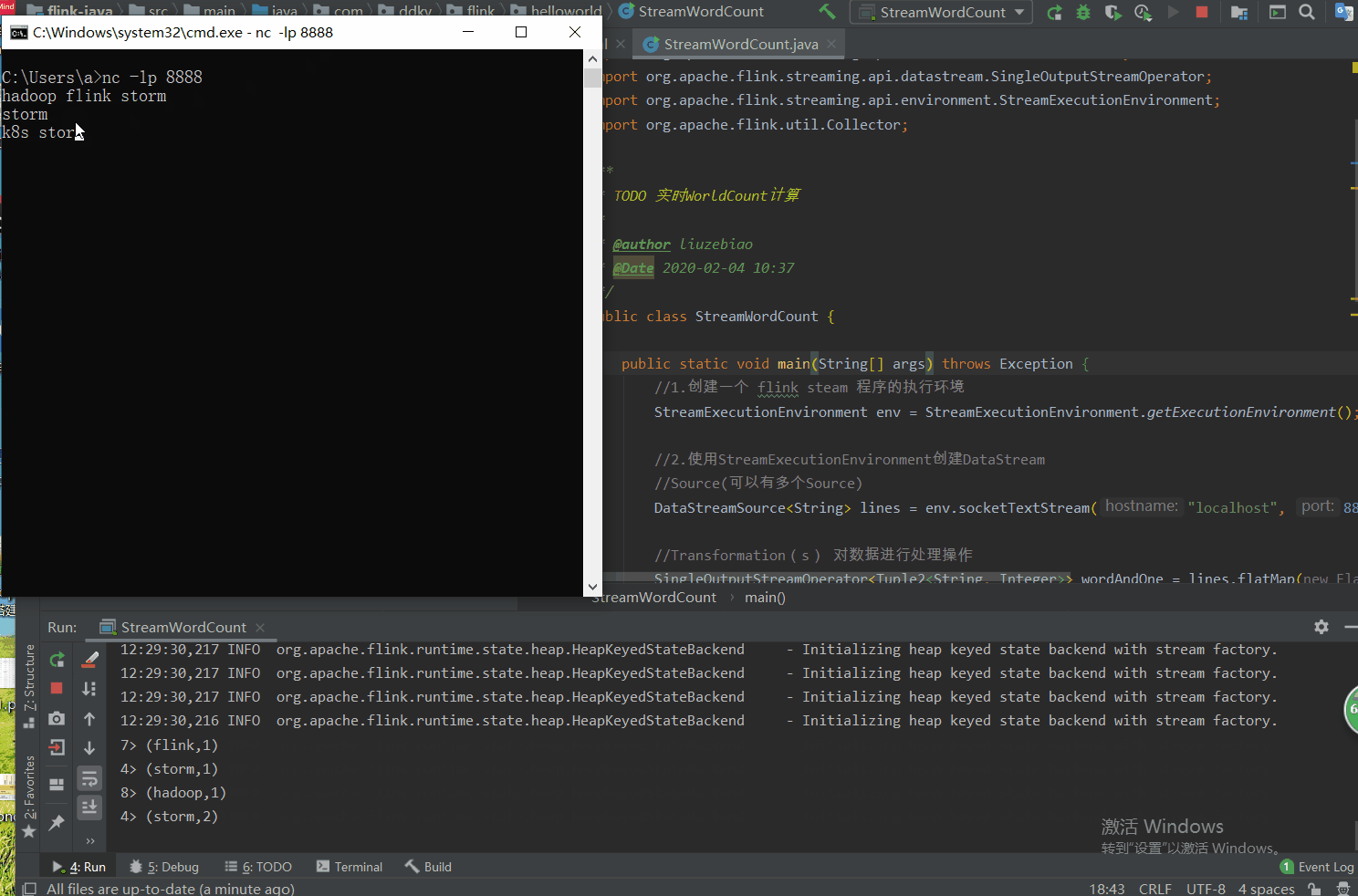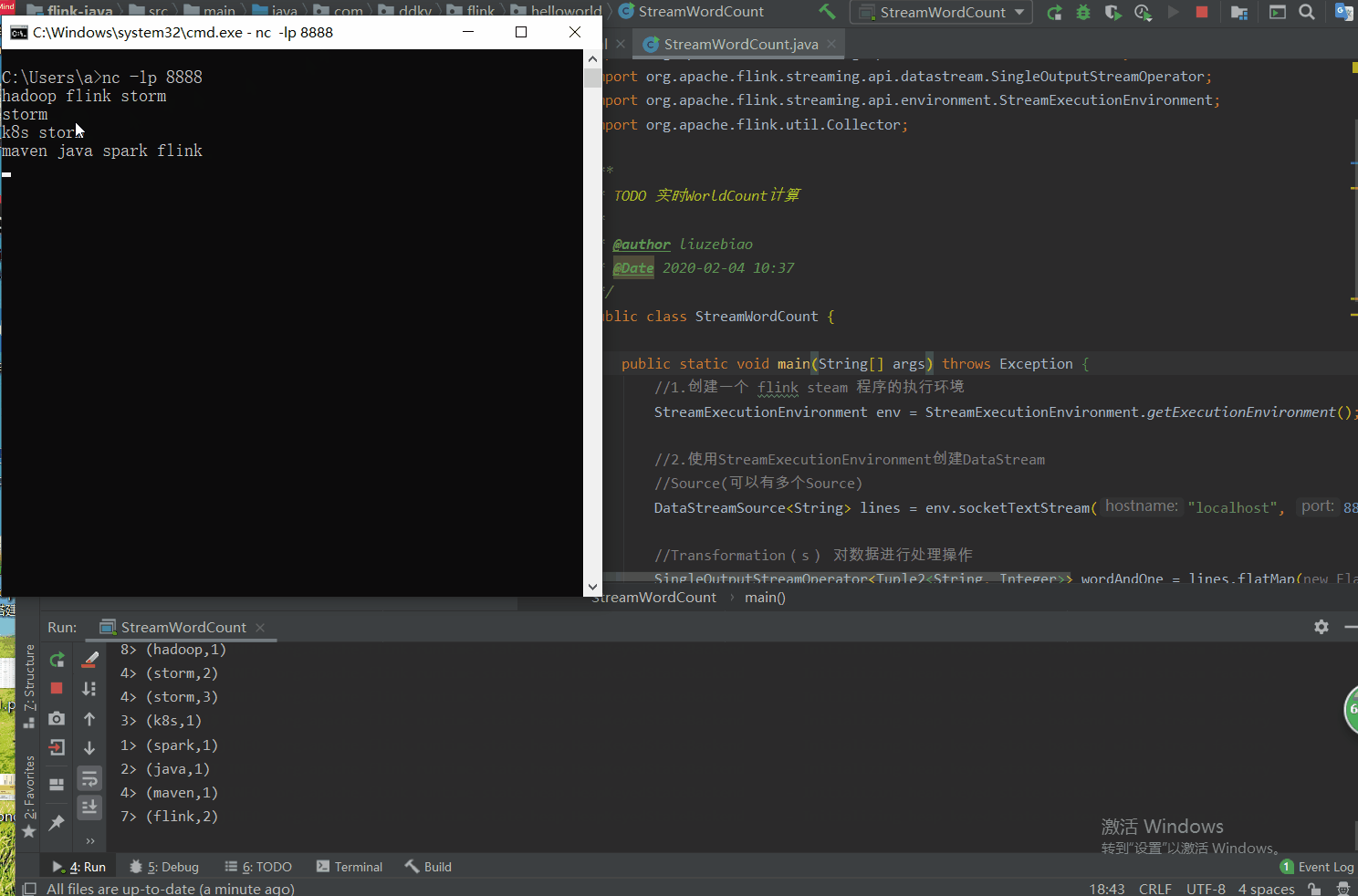
上图解析:
8> (hadoop,1)
4> (storm,2)
4> (storm,3)
3> (k8s,1)
1> (spark,1) —>前面数字 8 4 3 1 为 task 所在槽 slots 的编号
①相同的单词,一定会进入到相同的 task,因为它会根据 key 进行分组;
②task所在槽slots的编号,和当前使用的机器有关系。如下图所示:我们可以使用命令查询 CPU核数、线程数(下图以 windows 为例,linux自行百度)

我们发现:本机CPU为 8核8线程,所以 slots 槽的编号为 1~8;
③我们会发现不同的单词,分在的相同的 task 中。请记住:它可以分在相同 task 的不同组中哦。
Flink 编写实时 WordCount,介绍到此为止
如果本文对你有所帮助,那就给我点个赞呗 O(∩_∩)O
End
