机器学习
(1)监督学习:人类教计算机做某件事情
回归问题:设法预测连续值的属性
分类问题:设法预测一个离散值输出
(2)无监督学习:让计算机自己学习,最初给与计算机的是没有标签的数据集
分为聚类算法和鸡尾酒会算法
1. 线性回归模型(回归模型)
- 线性回归模型总体:
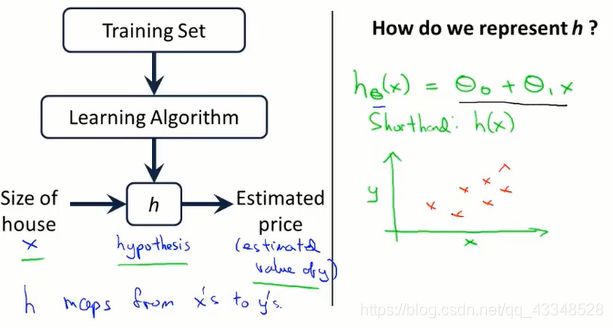
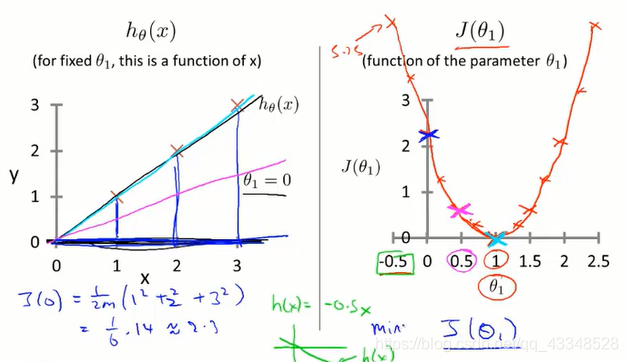
- 代价函数(cost function):
便于理解,等价于loss function

简单举一个例子(单一变量线性回归问题)如下:
梯度下降算法
-
batch梯度下降算法:

-
batch梯度下降法关注整个训练样本集
- 注意上图中的正确方法,一定要保证同步更新
- 同时考虑:学习率既不可以太小也不可以太大
- 如果一开始选择的θ已经是一个全局最优值(或者是局部最优值)之后该怎么做:
θ值将不会再更新,这也是我们所期望的到达一个局部最小值或者是全局最小值;
当我们接近最小值时,梯度下降法会自动采取更小的幅度(因此,学习率可以设定为固定值);
必须掌握一些关于矩阵的运算和基本用法
- 矩阵的加法、乘法、逆和转置
多变量(多特征量)线性回归问题
- 假设函数:
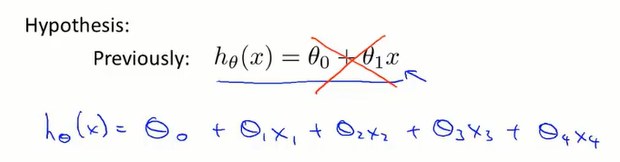
其中:x1、x2…分别代表不同特征量;
假设函数可以进一步简化为下式:

多变量(多特征量)梯度下降函数
-
梯度下降函数如下:

-
梯度下降运算中的实用技巧:
-
特征缩放(feature scaling)
确保特征值在同样的尺度(make sure features are on a similar scale)
进行特征缩放时,通常是希望将feature值缩放进-1到+1之间(只要接近-1到+1之间就可以,不一定要完全满足)。
例子:
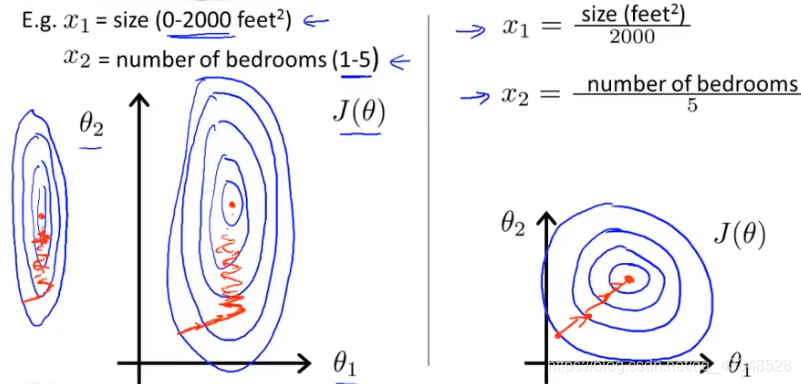
左边,未进行特征缩放,会导致梯度下降时来回摆动,不能快速下降,右边采用了特征缩放,使得梯度能够快速下降。
之后,通常会进行均值归一化,让特征值具有为0的平均值。 -
学习率
如果得到的关系图如下两种:
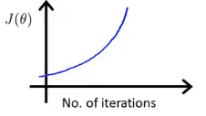
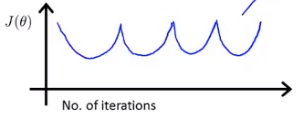
说明学习率设置的过大,需要用一个更小的学习率
正规方程
- 直接通过分析法计算损失函数最小处的θ值。
- 例如在一元二次情况下通过求导数的方式,缺点在于不适用于复杂的分类算法,例如logistics回归算法等。
- 计算θ的公式如下:
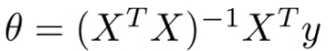
对于可能导致矩阵不可逆问题:
- 特征:存在多余的特征
- 特征过多:删除一些不重要的特征或者考虑使用正规化的方法
2. 逻辑回归(是一种分类算法)
分类
分类问题就是有明确规定是某一类或者不是某一类,从分类问题开始,有二分类问题和多分类问题:
-
二元分类问题:
逻辑回归是一种用来解决二元分类问题的算法

-
多分类问题
逻辑回归算法
- 逻辑回归算法如下:

-
假设表示(Hypothesis representation)
就是hθ(x) -
决策边界(decision boundary)
因为sigmoid function的特殊形式,使得θx>=0,就代表着y=1类;因为θx>=0,代表g(θx)>=0.5,也就是hθ(x)>=0.5,那么就是预测为y=1类。

-
cost function(代价函数、优化目标):
如何拟合logistic回归模型的参数θ;
其实就可以理解成损失函数;
不能再考虑和线性分类的损失函数一样,因为这样会使损失函数成为非凸函数,使用梯度下降法就较难找到全局最优点。

-
简化代价函数与梯度下降:
 形式看起来跟线性回归模型的梯度下降一样,但其实是不同的函数,因为当中的hθ(x)的值是完全不同的。
形式看起来跟线性回归模型的梯度下降一样,但其实是不同的函数,因为当中的hθ(x)的值是完全不同的。
高级优化方法

用逻辑回归算法解决多分类问题

3.正则化
-
为了解决过拟合问题;
欠拟合和过拟合问题:


-
为了解决过拟合问题:
(1)降低特征的数量
(2)正则化 -
拥有正则化的代价函数
 由此可知,一般性来讲在一个代价函数中,我们不知道要去缩小哪一个θ,因此我们会加入一项正则项来缩小所有的θ;
由此可知,一般性来讲在一个代价函数中,我们不知道要去缩小哪一个θ,因此我们会加入一项正则项来缩小所有的θ;

-
线性回归的正则化


-
逻辑回归的正则化

4. 非线性分类器(神经网络)
-
怎么用神经网络解决多类别分类问题:
就像逻辑回归解决多分类问题一样,其实来讲神经网络就是在套娃,把一个一次线性函数一直套娃,而逻辑回归就是对一个多元函数做了一次非线性处理。 -
反向传播是用来让损失函数(代价函数)最小化的算法;
