Paper name
Grounding Language Models to Images for Multimodal Generation
Paper Reading Note
URL: https://arxiv.org/abs/2301.13823
Project URL:https://jykoh.com/fromage
TL;DR
- 2023 年文章,提出 Frozen Retrieval Over Multimodal Data for Autoregressive Generation (FROMAGe),基于冻结的预训练 LLM 和冻结的预训练视觉编码器,以多任务目标进行训练,以较小的训练开销实现大 LLM 模型在多模态任务上的应用
Introduction
背景
- 大型语言模型(LLM)在大型文本语料库上进行了大规模训练,能够展示令人信服的能力,如生成类似人类的对话和回答复杂问题。
- 但大多数最先进的LLM都是基于从互联网上获取的纯文本数据进行训练的,他们没有接触到丰富的视觉线索,通常无法学习现实世界中的概念。因此,大多数现有的语言模型在涉及视觉推理和基础的任务上表现出局限性,并且它们也不能产生图像
- 本文能够有效地利用冻结的 LLM 的能力进行多模态(图像和文本)输入和输出任务
本文方案
- 提出了一种方法来引导用于处理和输出任意交织的多模态数据的冻结语言模型,从冻结的预训练 LLM 和冻结的预训练视觉编码器开始,并以多任务目标进行训练
- image captioning:学习处理交织的多模态输入。
- 从视觉编码器中提取视觉嵌入,并通过最大似然目标学习线性映射,以将嵌入映射到语言模型的输入空间
- image-text retrieval:学习产生交错的多模态输出
- 训练语言模型学习表示图像的新 [RET] token,并通过 contrastive learning 学习线性映射,以将 caption 的 [RET] 嵌入映射为接近其配对图像的视觉嵌入
- 大多数模型保持冻结,只在训练期间更新线性层的权重和 [RET] token embedding
- 保留了纯文本LLM生成文本的原始能力,但也获得了新的多模态对话和推理能力

- image captioning:学习处理交织的多模态输入。
- 本文贡献
- 提出 Frozen Retrieval Over Multimodal Data for Autoregressive Generation (FROMAGe),通过图像 caption 和对比学习的视觉基础LLM 有效训练的模型。FROMAGe 仅从图像 caption 对学习到强大的 zero-shot 多模态能力,而其他模型需要 web-scale 的交错图像文本数据(比如 Flamingo,CM3)
- 证明了自回归 LLM 可以对输入文本进行更高灵敏度的文本到图像检索。本文方法对长而复杂的自由格式文本更准确
- 表明预训练的纯文本LLM的现有能力,如上下文学习、输入敏感度和对话生成,可用于视觉基础任务。比如展示了
- 给定交错图像和文本序列的上下文图像检索
- 视觉对话中的 zero-shot 表现
- 提高了图像检索对话语上下文的敏感性
Dataset/Algorithm/Model/Experiment Detail
实现方式
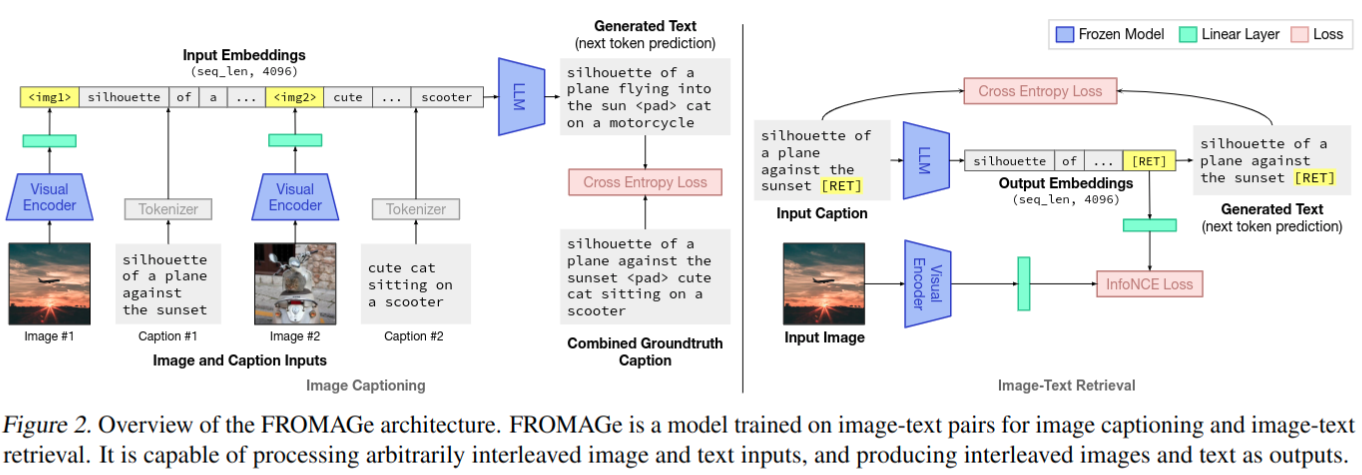
模型结构
- 语言模型:
- 采用自回归大语言模型 pθ,最初在纯文本数据上使用最大似然目标进行训练,并保持其参数 θ 冻结
- 给定文本x(例如,图像 caption),使用字节级 BPE tokenizer 提取一系列输入 token(s1,…,sT)
- 训练模型以最大化 token 序列的对数似然性,将其分解为条件对数概率之和
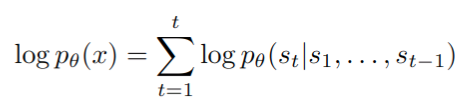
- 视觉模型
- 使用冻结参数的视觉模型来提取特征 v ϕ ( y ) ∈ R m v_{\phi}(y) \in \mathbb{R}^{m} vϕ(y)∈Rm
图像与文本转换
- 为了整合视觉和语言,学习转换网络参数以在图像和文本嵌入空间之间进行映射。这扩展了多模态输入和输出的 LLM
- Mapping image-to-text:
- 基于 linear 映射 ( W c ∈ R m × k d W_{c} \in \mathbb{R}^{m \times kd} Wc∈Rm×kd ),将图像特征 v ϕ ( y ) ∈ R m v_{\phi}(y) \in \mathbb{R}^{m} vϕ(y)∈Rm 处理为 v ϕ ( y ) T W c ∈ R k × d v_{\phi}(y)^TW_{c} \in \mathbb{R}^{k \times d} vϕ(y)TWc∈Rk×d ,这表示与 LLM 输入 token 生成的文本嵌入具有相同隐藏维度 d 的 k 个向量序列
- Mapping text-to-image:
- 旨在使用自回归语言模型的输出检索图像,这方面的一个挑战是,文本上的自回归因果注意比先前模型中通常使用的双向注意表现力差得多
- 这里向模型词汇表中添加一个特殊的 [RET] token 并学习其嵌入 (冻结所有其他 token 嵌入)。在训练期间,在输入 caption 的末尾添加 [RET]。这允许模型对文本中的所有标记执行额外的关注步骤,从而为 caption 生成更强的文本表示。这也使得后续可以利用 inference 阶段生成的 [RET] 来检索图片
- 这里同样使用一个 linear mapping 来将 LLM 最后一层输出的 [RET] 转换到一个向量空间中,同样图像特征也会经过一个 linear mapping 映射到同样的 retrieval space 中
训练设置
- 对 Image captioning 和 Image-text retrieval 进行多任务联合训练
- image captioning:将图像 captioning 表述为生成基于视觉前缀的文本 tokens 的任务。视觉前缀即之前所述的 image-to-text mapping 的输出,在 caption 前面加上。以图像 y 为条件的 caption x(标记为(s1,…,sT))的对数似然性为
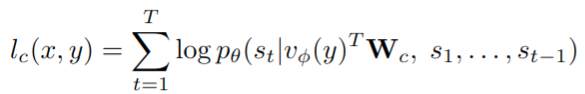
captioning 损失 Lc 是一批 N 个图像文本对中所有样本的负对数似然性
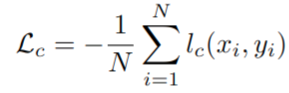
- Image-text retrieval:除了图像 caption,训练模型以检索基于文本的图像。给定 caption x 及其配对图像 y,我们提取 [RET] token 的 LLM 的最后一个隐藏层的输出 hθ(x)和图像的视觉编码器的输出 vφ(y),计算图像与文本的相似性
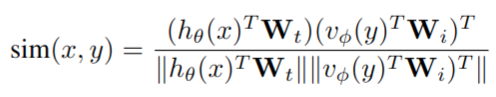
最小化 text-to-image 与 image-to-text 的 InfoNCE loss
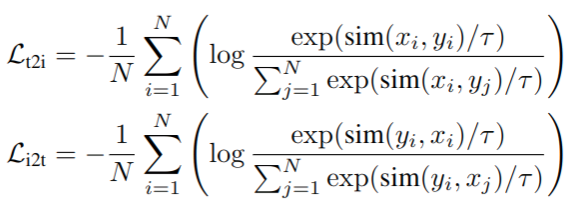
- image captioning:将图像 captioning 表述为生成基于视觉前缀的文本 tokens 的任务。视觉前缀即之前所述的 image-to-text mapping 的输出,在 caption 前面加上。以图像 y 为条件的 caption x(标记为(s1,…,sT))的对数似然性为
- 最终训练损失为上述损失的加权和
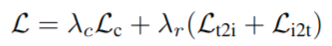
- 最终训练的参数只有三个 linear mapping 层和 [RET] embedding vector
数据和实施细节
- 数据:Conceptual Captions (CC3M),包含 3.3 million 图片文本对
- 为了鼓励模型更明确地关注图像,我们将图像 caption 任务的不同示例随机连接在一起(连接概率为0.5)。这有助于训练模型在序列中注意正确的图像
- 模型结构
- 使用的 LLM 模型:OPT 6.7B。过去的研究表明,6.7B 规模的研究结果可能会推广到更大的模型尺寸,并且足够大,能够展现出本文感兴趣的 zero-shot 和情境学习能力
- 视觉模型:CLIP ViT-L/14
实验结果
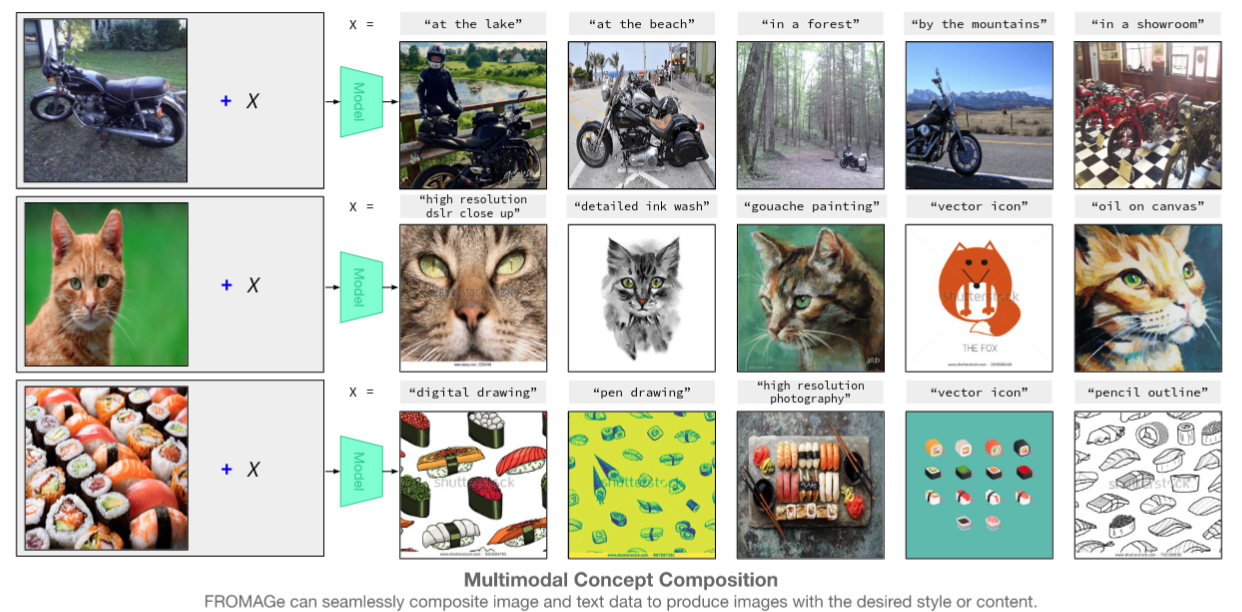
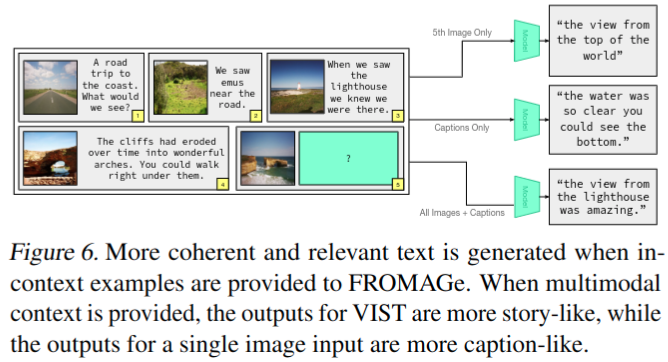
多模态输入的上下文检索
-
支持 multimodal dialogue or image-and-text,对上下文敏感

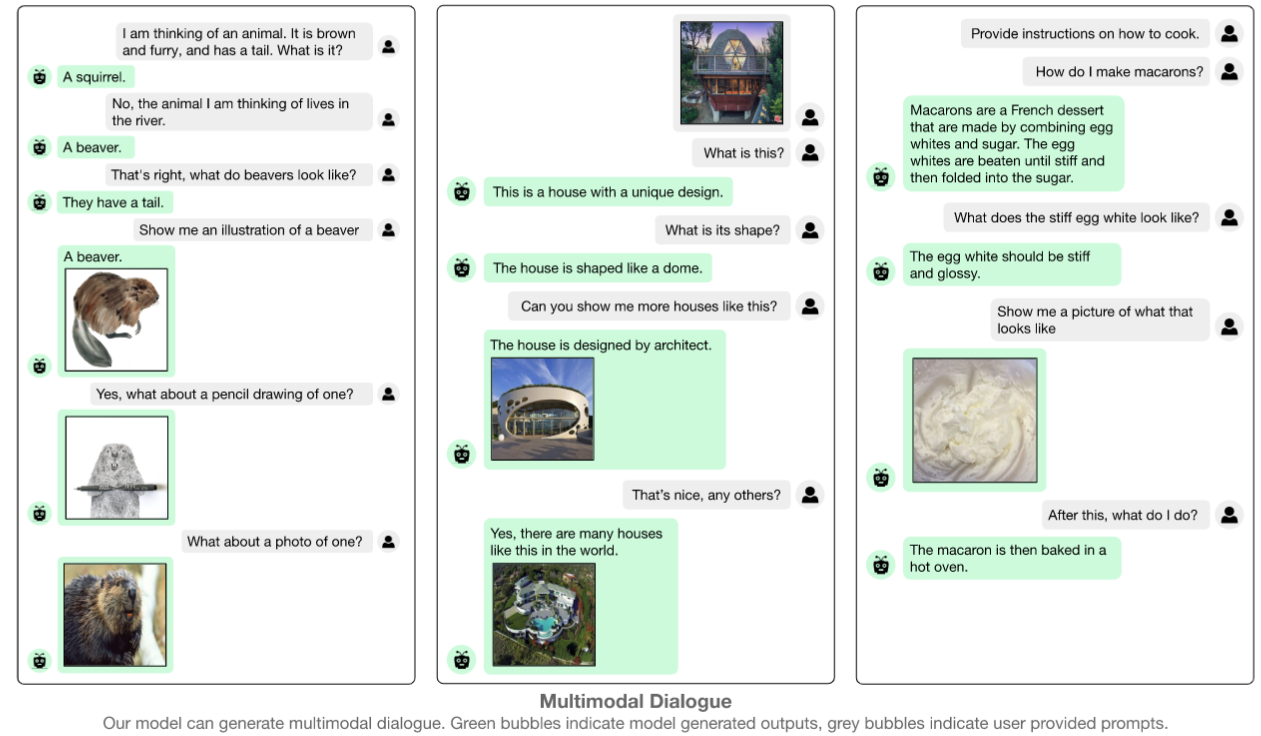
-
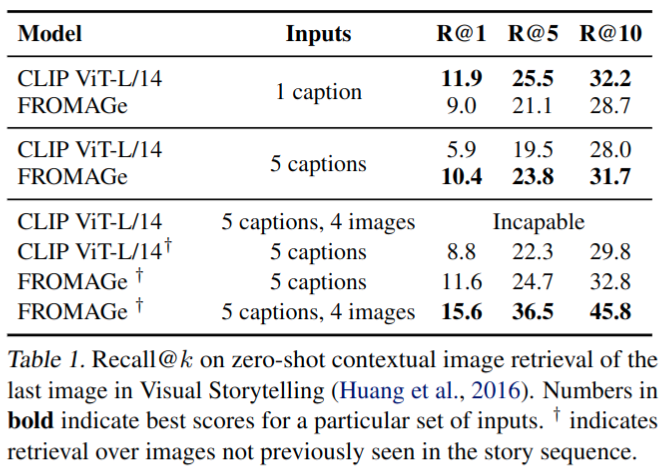
为了评估 FROMAGe 处理多模态上下文信息的能力,评估了其在检索基于视觉故事讲述(VIST)数据集的一系列交织图像文本输入的适当图像方面的性能。给多个 caption 时本文工作能超过 CLIP 精度(CLIP 无法正确处理较长的、时间相关的句子)

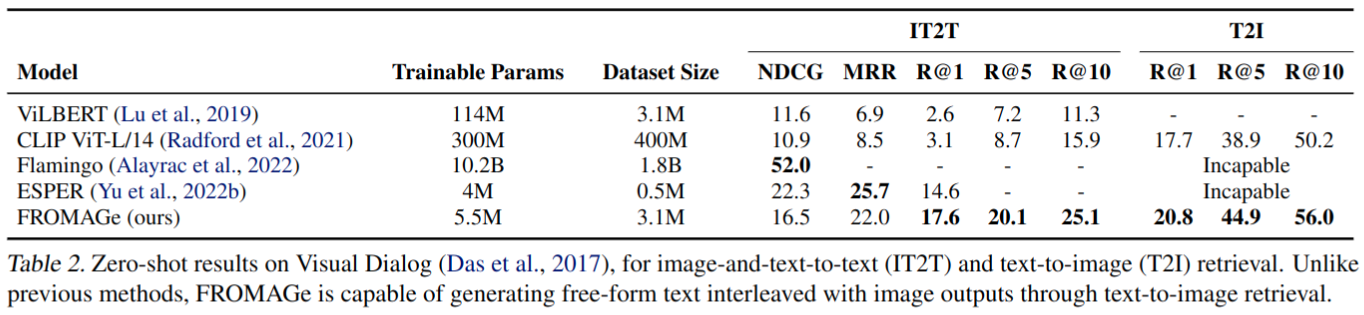
Visual Dialogue
- 测试 zero-shot Visual Dialog
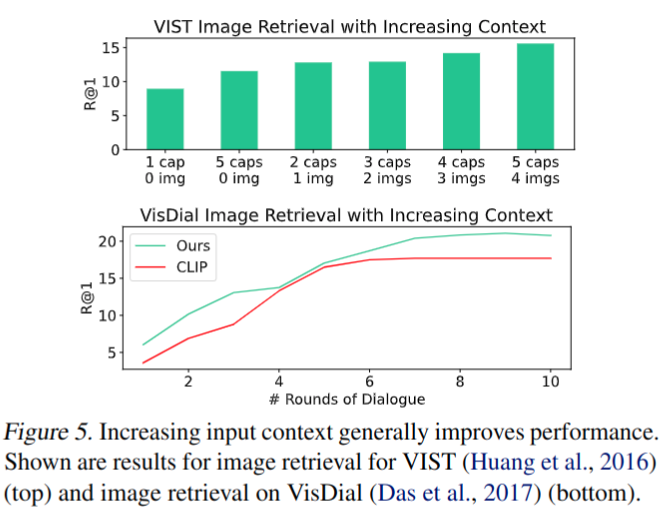
消融实验
- 增加上下文信息能有效提升精度
Thoughts
- 只用 linear 在其他任务上的精度是否够用比较怀疑,整体思路上其实和 BLIP2 很像,但是 BLIP2 使用的连接两个模态的参数明显更多