Lion:Adversarial Distillation of Closed-Source Large Language Model
Introduction
作者表明ChatGPT、GPT4在各行各业达到很好的效果,但是它们的模型与数据都是闭源的。现在的主流的方案是通过一个老师模型把知识蒸馏到学生模型。
但是在我们的现实教学中,老师把知识教给学生,学生还会给老师反馈哪道题不会,也就是hard样本。
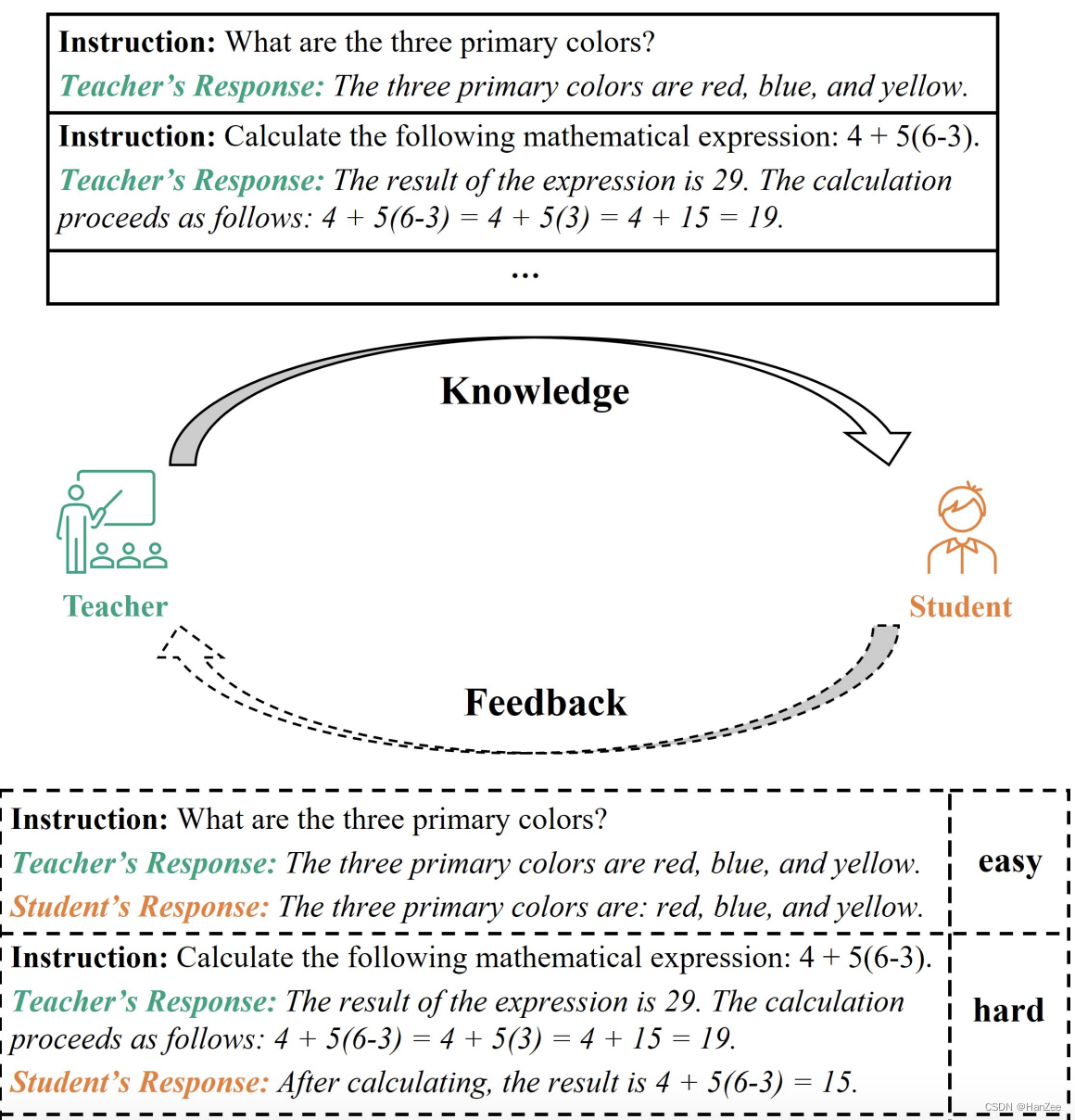
作者提出了对抗框架,包括以下步骤:
- 模型阶段:把学生的回复align到老师的回复。
- 区分阶段:区分阶段识别困难样本。
- 生成阶段:产生新的关于模型生成困难的指令。
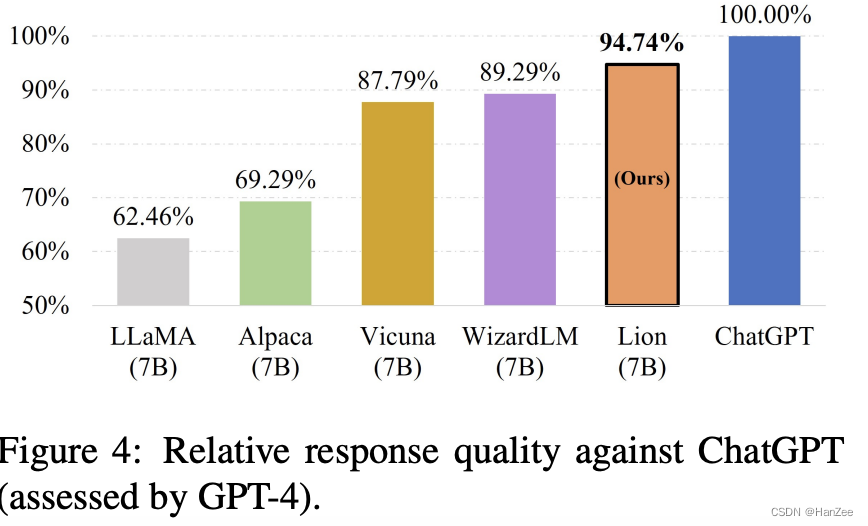
最后作者通过这个框架,以Alpaca 175条种子数据为基础,生成了70k数据,在LLaMA 7B上微调,达到了95%ChatGPT的水平,模型命名为Lion。
Methodology
定义teacher model 为 : T ( x , θ T ) T(x, \theta^T) T(x,θT),student model 为 S ( x ; θ S ) S(x;\theta^S) S(x;θS)。
在以前的方法中,普遍做法就是把teacher model 生成的数据,让student model 微调,训练完成后,学生不会百分百达到teacher model的水准,它们之间存在一个gap,而作者认为 hard sample dominate 了这个gap,所以优化方向就是关注这些hard sample,以实现高效提升效率。
所以需要不断的生成对student model 来说的hard sample,供给student model training, 最后 student model 会把 hard sample convert into simple sample。
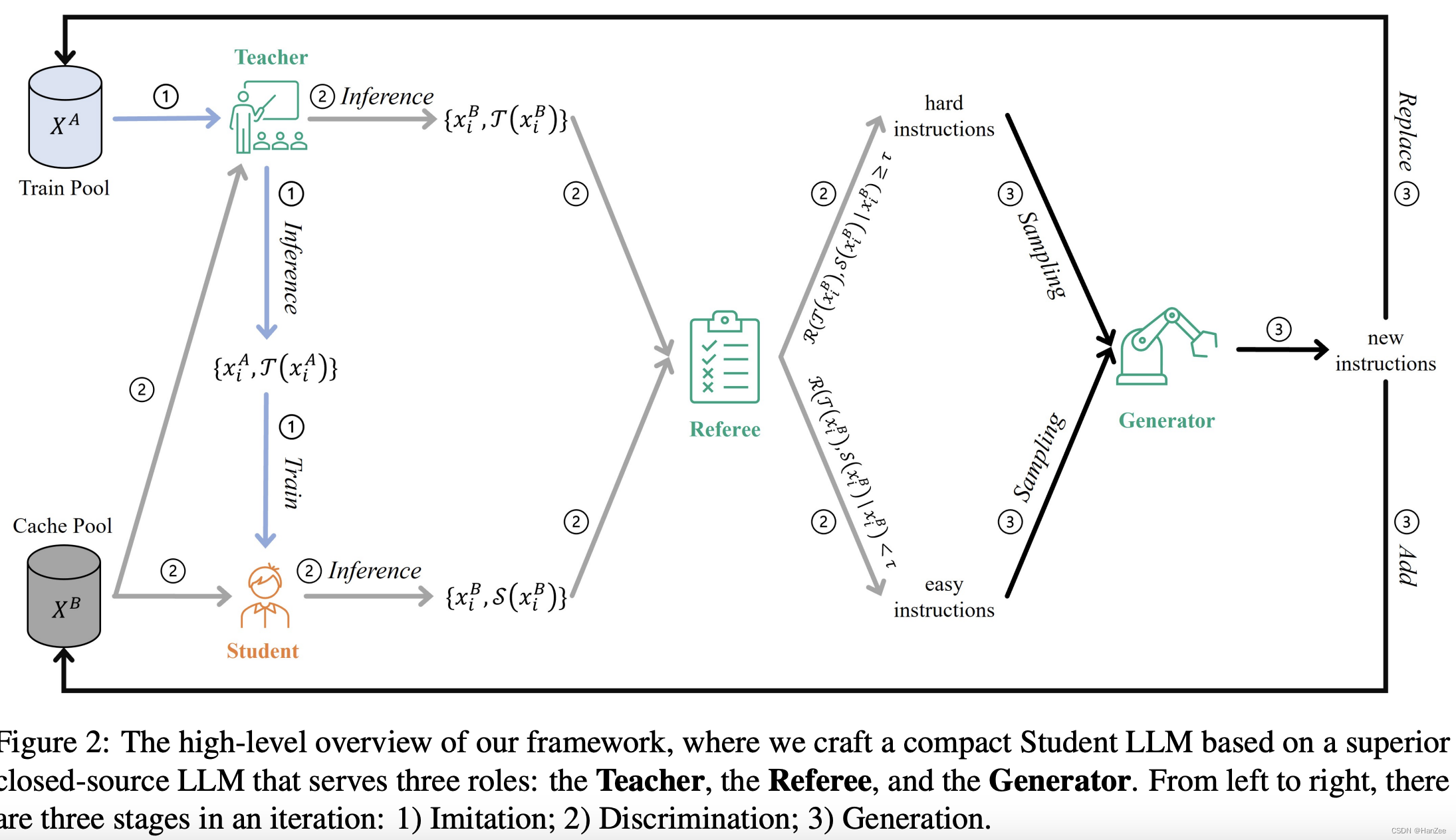
如上图,首先初始化两个 Dataset Pool,首先采用Teacher model 以类似于Self- Instruct 的方法生成数据,template如下:

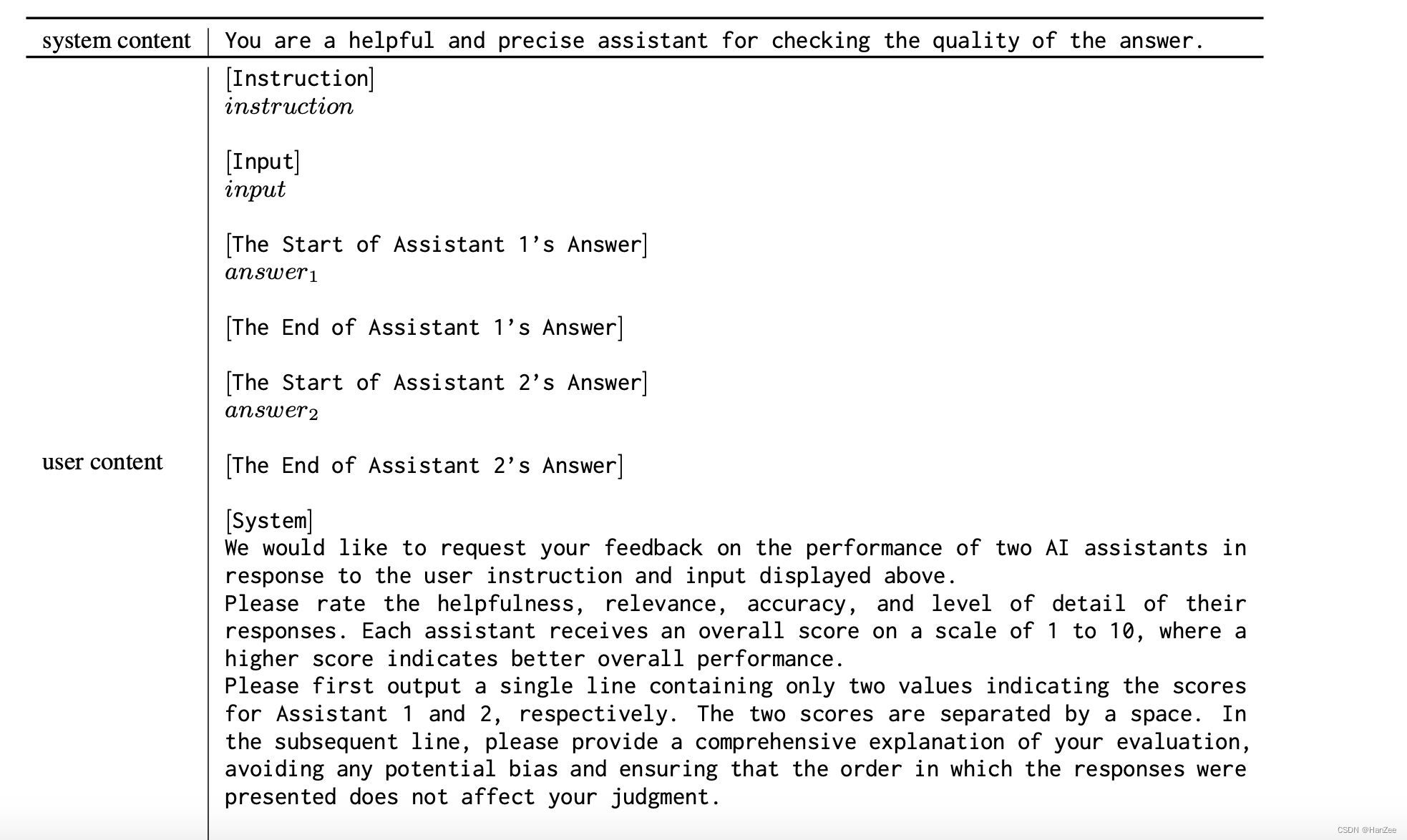
然后把生成的数据分别放入 Train Pool 与 Cache Pool,然后 Student Model 从 Train Pool 里面那数据微调。 微调完成后,Teacher model 与Student model 分别拿 Cache Pool 里面的数据进行推理,拿到他们的推理结果后,以类似Vicuna的方式进行结果质量比较,也就是找出hard sample,template如下:
根据得分,区分出hard sample 与 easy sample,继续使用ChatGPT以few shot的形式产生新的数据,为了确保数据的多样性以及hard sample的数量,比例采用1:1的形式。template如下:

然后 新的数据替换掉Train Pool 已有的数据并且插入到Cache Pool。
继续往复之前描绘的操作。
experiment