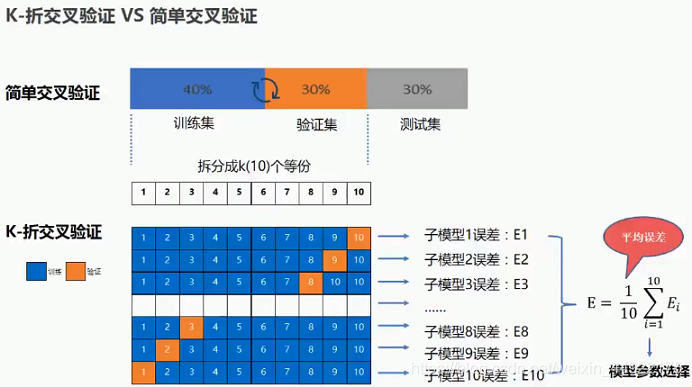
针对过拟合、欠拟合及其解决方案的认识
- 欠拟合(underfitting):模型无法得到较低的训练误差;
- 过拟合(overfitting):模型的训练误差远小于它在测试数据集上的误差。
给定训练数据集,模型复杂度和误差之间的关系:
当对该隐藏层使用丢弃法时,该层的隐藏单元将有一定概率被丢弃掉。设丢弃概率为
,那么有
的概率
会被清零,有
的概率
会除以
做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量
为0和1的概率分别为
和
。使用丢弃法时我们计算新的隐藏单元
由于 ,因此
针对梯度消失、梯度爆炸的认识
- 深度模型有关数值稳定性的典型问题是消失(vanishing)和爆炸(explosion)。
- 如果将每个隐藏单元的参数都初始化为相等的值,那么在正向传播时每个隐藏单元将根据相同的输入计算出相同的值,并传递至输出层。在反向传播中,每个隐藏单元的参数梯度值相等。通常将神经网络的模型参数,特别是权重参数,进行随机初始化。
- 考虑环境因素
协变量偏移:输入特征X改变;
标签偏移:输出标签y改变;
概念偏移:X到y之间出现新的映射关系。
针对循环神经网络进阶的认识
- RNN
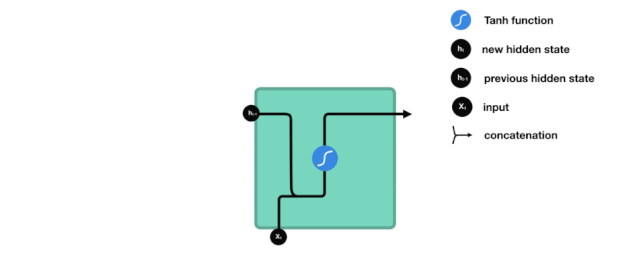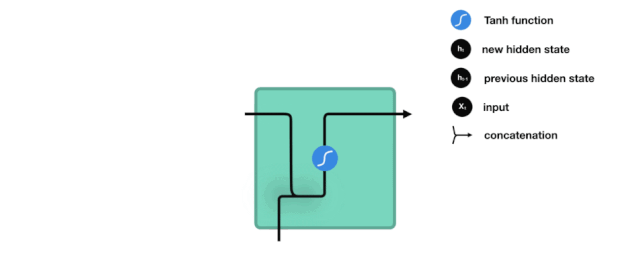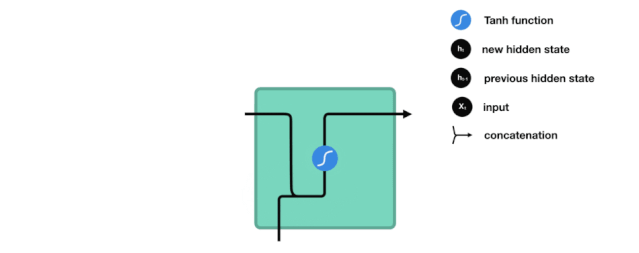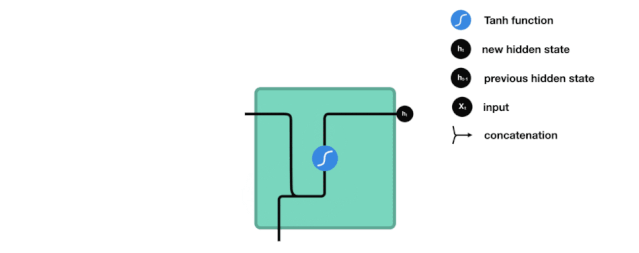
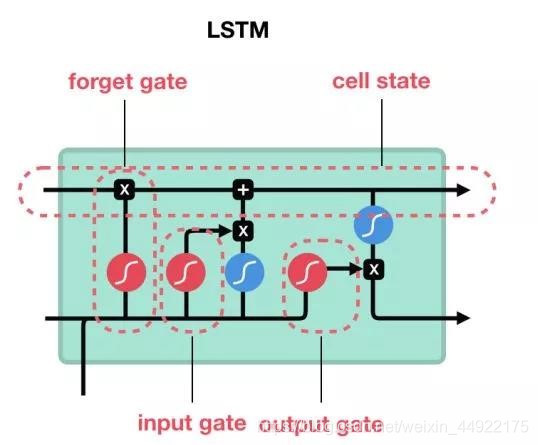
- LSTM
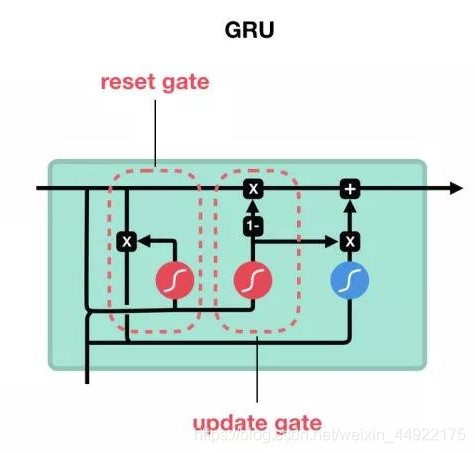
- GRU
- 深度循环神经网络
- 双向循环神经网络