批量归一化和残差网络
批量归一化(BatchNormalization)
批量归一化(深度模型)
利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层的中间输出的数值更稳定。
1.对全连接层做批量归一化
位置:全连接层中的仿射变换和激活函数之间。

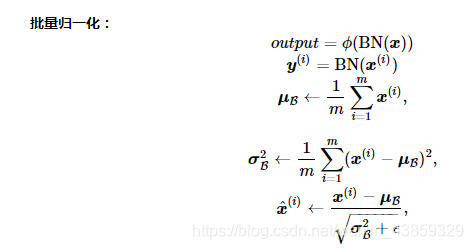

2.对卷积层做批量归⼀化
位置:卷积计算之后、应⽤激活函数之前。
如果卷积计算输出多个通道,我们需要对这些通道的输出分别做批量归一化,且每个通道都拥有独立的拉伸和偏移参数。 计算:对单通道,batchsize=m,卷积计算输出=pxq 对该通道中m×p×q个元素同时做批量归一化,使用相同的均值和方差。
3.预测时的批量归⼀化
训练:以batch为单位,对每个batch计算均值和方差。
预测:用移动平均估算整个训练数据集的样本均值和方差。
nn.BatchNorm2d(out_channel), #BatchNorm2d最常用于卷积网络中(防止梯度消失或爆炸),设置的参数就是卷积的输出通道数
可mark
http://www.mamicode.com/info-detail-2378483.html
【卷积神经网络】对BN层的解释
可看https://www.cnblogs.com/kk17/p/9693462.html
ResNet描述
https://www.cnblogs.com/bonelee/p/8977095.html
卷积(64,7x7,3)
批量一体化
最大池化(3x3,2)
残差块x4 (通过步幅为2的残差块在每个模块之间减小高和宽)
全局平均池化
全连接
稠密连接网络(DenseNet)
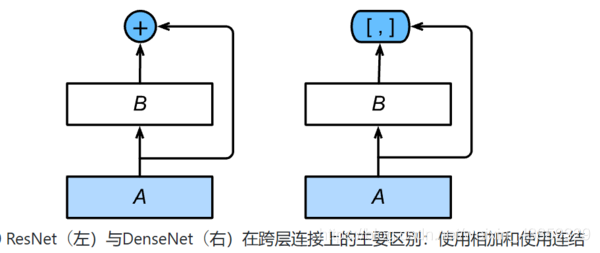
主要构建模块:¶
稠密块(dense block): 定义了输入和输出是如何连结的。
过渡层(transition layer):用来控制通道数,使之不过大。
扩展:
https://blog.csdn.net/baidu_27643275/article/details/79250537
神经网络优化问题中的鞍点即一个维度向上倾斜且另一维度向下倾斜的点。
鞍点:梯度等于零,在其附近Hessian矩阵有正的和负的特征值,行列式小于0,即是不定的。
鞍点和局部极值的区别:
鞍点和局部极小值相同的是,在该点处的梯度都等于零,不同在于在鞍点附近Hessian矩阵是不定的(行列式小于0),而在局部极值附近的Hessian矩阵是正定的。
在鞍点附近,基于梯度的优化算法(几乎目前所有的实际使用的优化算法都是基于梯度的)会遇到较为严重的问题:
鞍点处的梯度为零,鞍点通常被相同误差值的平面所包围(这个平面又叫Plateaus,Plateaus是梯度接近于零的平缓区域,会降低神经网络学习速度),在高维的情形,这个鞍点附近的平坦区域范围可能非常大,这使得SGD算法很难脱离区域,即可能会长时间卡在该点附近(因为梯度在所有维度上接近于零)。
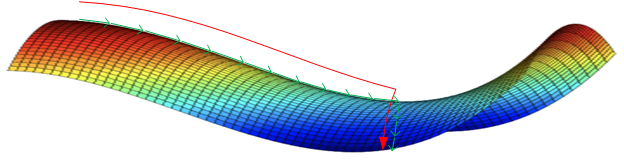
在鞍点数目极大的时候,这个问题会变得非常严重。
高维非凸优化问题之所以困难,是因为高维参数空间存在大量的鞍点。
补充:
Hessian矩阵是一个多元函数的二阶偏导数构成的方阵,描述了函数的局部曲率。可用于判定多元函数的极值。

如何理解随机梯度下降(stochastic gradient descent,SGD)
https://www.zhihu.com/question/264189719
https://blog.csdn.net/qq_30911665/article/details/79531733
学习率
https://www.csdn.net/gather_28/MtTaggysMDk1Ny1ibG9n.html
https://blog.csdn.net/qq_30911665/article/details/79531733
