1、批量归一化和残差网络
1.1 批量归一化(BatchNormalization)
对输入的标准化(浅层模型)
- 处理后的任意一个特征在数据集中所有样本上的均值为0、标准差为1。
- 标准化处理输入数据使各个特征的分布相近
批量归一化(深度模型)
利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使整个神经网络在各层的中间输出的数值更稳定。

预测时的批量归⼀化
训练:以batch为单位,对每个batch计算均值和方差。
预测:用移动平均估算整个训练数据集的样本均值和方差。
1.2 残差网络(ResNet)
深度学习的问题:深度CNN网络达到一定深度后再一味地增加层数并不能带来进一步地分类性能提高,反而会招致网络收敛变得更慢,准确率也变得更差。
残差块(Residual Block)

1.3 稠密连接网络(DenseNet)

主要构建模块:
稠密块(dense block): 定义了输入和输出是如何连结的,具体就是输出通道的计算方式。
过渡层(transition layer):运用1×1的卷积操作来控制通道数,使之不过大。同时还会采用平均池化的方式来减小尺寸。
#稠密块的代码如下:
def conv_block(in_channels, out_channels):
blk = nn.Sequential(nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
return blk
class DenseBlock(nn.Module):
def __init__(self, num_convs, in_channels, out_channels):
super(DenseBlock, self).__init__()
net = []
for i in range(num_convs):
in_c = in_channels + i * out_channels
net.append(conv_block(in_c, out_channels))
self.net = nn.ModuleList(net)
self.out_channels = in_channels + num_convs * out_channels ### 计算输出通道数
def forward(self, X):
for blk in self.net:
Y = blk(X)
X = torch.cat((X, Y), dim=1) # 在通道维上将输入和输出连结
return X
#过渡块的代码如下:
def transition_block(in_channels, out_channels):
blk = nn.Sequential(
nn.BatchNorm2d(in_channels), #归一化
nn.ReLU(), #非线性激活函数
nn.Conv2d(in_channels, out_channels, kernel_size=1), #1×1的卷积操作减小通道数
nn.AvgPool2d(kernel_size=2, stride=2)) #平均池化减小输出尺寸
return blk
2、凸优化
2.1 优化与深度学习
优化与估计
尽管优化方法可以最小化深度学习中的损失函数值,但本质上优化方法达到的目标与深度学习的目标并不相同。
- 优化方法目标:训练集损失函数值
- 深度学习目标:测试集损失函数值(泛化性)
优化在深度学习中的挑战
- 局部最小值

- 鞍点

- 梯度消失

2.2 凸性 (Convexity)
凸函数集合:如果对于一个集合内的任意两个点的连线的说有点都在集合内,称之为凸集合。

性质
- 无局部极小值
- 与凸集的关系
- 二阶条件
证明:略
3、梯度下降
3.1 一维梯度下降

3.2 多维梯度下降
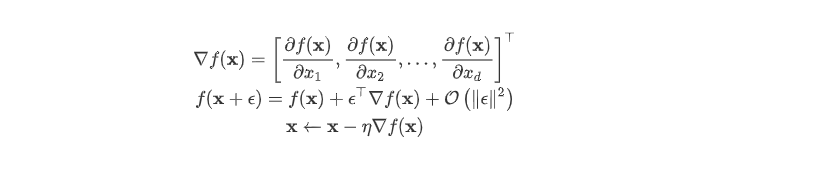
3.3 简洁实现
# 本函数与原书不同的是这里第一个参数优化器函数而不是优化器的名字
# 例如: optimizer_fn=torch.optim.SGD, optimizer_hyperparams={"lr": 0.05}
def train_pytorch_ch7(optimizer_fn, optimizer_hyperparams, features, labels,
batch_size=10, num_epochs=2):
# 初始化模型
net = nn.Sequential(
nn.Linear(features.shape[-1], 1)
)
loss = nn.MSELoss()
optimizer = optimizer_fn(net.parameters(), **optimizer_hyperparams)
def eval_loss():
return loss(net(features).view(-1), labels).item() / 2
ls = [eval_loss()]
data_iter = torch.utils.data.DataLoader(
torch.utils.data.TensorDataset(features, labels), batch_size, shuffle=True)
for _ in range(num_epochs):
start = time.time()
for batch_i, (X, y) in enumerate(data_iter):
# 除以2是为了和train_ch7保持一致, 因为squared_loss中除了2
l = loss(net(X).view(-1), y) / 2
optimizer.zero_grad()
l.backward()
optimizer.step()
if (batch_i + 1) * batch_size % 100 == 0:
ls.append(eval_loss())
# 打印结果和作图
print('loss: %f, %f sec per epoch' % (ls[-1], time.time() - start))
d2l.set_figsize()
d2l.plt.plot(np.linspace(0, num_epochs, len(ls)), ls)
d2l.plt.xlabel('epoch')
d2l.plt.ylabel('loss')
train_pytorch_ch7(optim.SGD, {"lr": 0.05}, features, labels, 10)

内容内容来源于伯禹学院的课件,仅作为自己的学习记录
