DRL代码学习打卡-4
1. 什么是 Sarsa(lambda)
- 基于Sarsa的提速方法。
- Sarsa是单步更新的,也称作Sarsa(0);
- 一个回合走N步,称作Sarsa(N);
同理, 如果等待回合完毕我们一次性再更新呢, 比如这回合我们走了 n 步, 那我们就叫 Sarsa(n). 为了统一这样的流程, 我们就有了一个 lambda 值来代替我们想要选择的步数, 这也就是 Sarsa(lambda) 的由来. 我们看看最极端的两个例子, 对比单步更新和回合更新, 看看回合更新的优势在哪里.
虽然我们每一步都在更新, 但是在没有获取宝藏的时候, 我们现在站着的这一步也没有得到任何更新, 也就是直到获取宝藏时, 我们才为获取到宝藏的上一步更新为: 这一步很好, 和获取宝藏是有关联的,
而之前为了获取宝藏所走的所有步都被认为和获取宝藏没关系.
回合更新虽然我要等到这回合结束, 才开始对本回合所经历的所有步都添加更新, 但是这所有的步都是和宝藏有关系的, 都是为了得到宝藏需要学习的步, 所以每一个脚印在下回合被选则的几率又高了一些. 在这种角度来看, 回合更新似乎会有效率一些.
我们看看这种情况, 还是使用单步更新的方法在每一步都进行更新, 但是同时记下之前的寻宝之路. 你可以想像, 每走一步, 插上一个小旗子, 这样我们就能清楚的知道除了最近的一步, 找到宝物时还需要更新哪些步了. 不过, 有时候情况可能没有这么乐观. 开始的几次, 因为完全没有头绪, 我可能在原地打转了很久, 然后才找到宝藏, 那些重复的脚步真的对我拿到宝藏很有必要吗? 答案我们都知道. 所以Sarsa(lambda)就来拯救你啦.
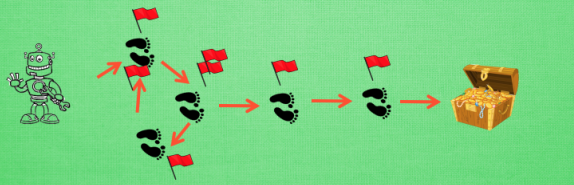
其实 lambda 就是一个衰变值, 他可以让你知道离奖励越远的步可能并不是让你最快拿到奖励的步, 所以我们想象我们站在宝藏的位置, 回头看看我们走过的寻宝之路, 离宝藏越近的脚印越看得清, 远处的脚印太渺小, 我们都很难看清, 那我们就索性记下离宝藏越近的脚印越重要, 越需要被好好的更新. 和之前我们提到过的 奖励衰减值 gamma 一样, lambda 是脚步衰减值, 都是一个在 0 和 1 之间的数.
- 当 lambda 取 0, 就变成了 Sarsa 的单步更新
- 当 lambda 取 1, 就变成了回合更新, 对所有步更新的力度都是一样
- 当 lambda 在 0 和 1 之间, 取值越大, 离宝藏越近的步更新力度越大. 这样我们就不用受限于单步更新的每次只能更新最近的一步, 我们可以更有效率的更新所有相关步了.
2. 代码

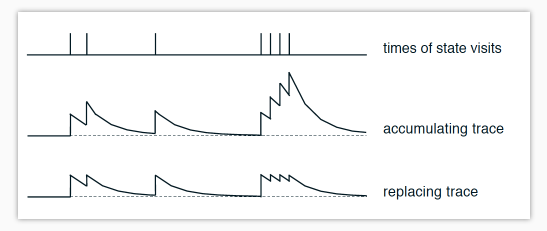
经历过某个state对其增加对目标的重要性(一种就是爆炸式增加,一种是设置增加上限防止大干扰),随着后面没有再经历,施加衰减,减弱他的重要性。
# backward eligibility traces
class SarsaLambdaTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9, trace_decay=0.9):
super(SarsaLambdaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
# backward view, eligibility trace.
self.lambda_ = trace_decay
self.eligibility_trace = self.q_table.copy()
这里 eligibility_trace 就是施加重要性的衰减表,他和 q_table 的大小是一样的。
因此更新状态表也要更新 eligibility_trace
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
to_be_append = pd.Series(
[0] * len(self.actions),
index=self.q_table.columns,
name=state,
)
self.q_table = self.q_table.append(to_be_append)
# also update eligibility trace
self.eligibility_trace = self.eligibility_trace.append(to_be_append)
这是针对于一个 state-action 值按经历次数的变化. 最上面是经历 state-action 的时间点, 第二张图是使用这种方式所带来的 “不可或缺性值”:
self.eligibility_trace.ix[s, a] += 1
下面图是使用这种方法带来的 “不可或缺性值”:
self.eligibility_trace.ix[s, :] *= 0; self.eligibility_trace.ix[s, a] = 1
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
else:
q_target = r # next state is terminal
error = q_target - q_predict
# increase trace amount for visited state-action pair
# Method 1: 重要性不设置上限
# self.eligibility_trace.loc[s, a] += 1
# Method 2:
self.eligibility_trace.loc[s, :] *= 0
self.eligibility_trace.loc[s, a] = 1
# Q update
self.q_table += self.lr * error * self.eligibility_trace
# decay eligibility trace after update
self.eligibility_trace *= self.gamma*self.lambda_
这里
# 随着时间衰减 eligibility trace 的值, 离获取 reward 越远的步, 他的"不可或缺性"越小
self.eligibility_trace *= self.gamma*self.lambda_