策略学习的意思是通过求解一个优化问题,学出最优策略函数 π ( a ∣ s ) \pi(a|s) π(a∣s)或它的近似函数(比如策略网络)。
一、策略网络
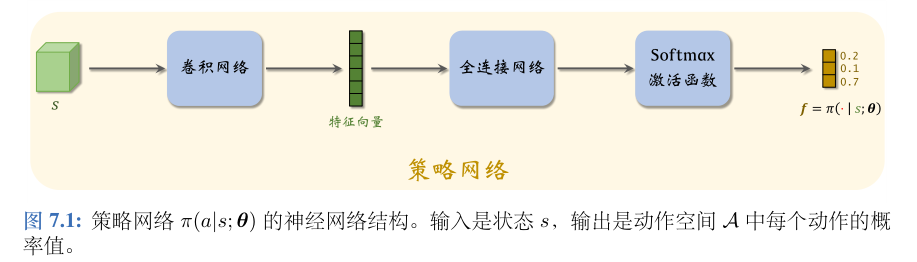
在 Atari 游戏、围棋等应用中,状态是张量(比如图片),那么应该如图 7.1 所示用卷积网络处理输入。在机器人控制等应用中,状态 s 是向量,它的元素是多个传感器的数值,那么应该把卷积网络换成全连接网络。
二、 策略学习的目标函数
- 状态价值既依赖于当前状态 s t ,也依赖于策略网络 π 的参数 θ。
- 策略学习的目标函数

三、策略梯度定理
四、Actor-Critic

1.价值网络
Actor-critic 方法用一个神经网络近似动作价值函数 Q π ( s , a ) Q _π (s,a) Qπ(s,a),这个神经网络叫做“价值网络”,记为 q ( s , a ; w ) q(s,a;\bf{w}) q(s,a;w)
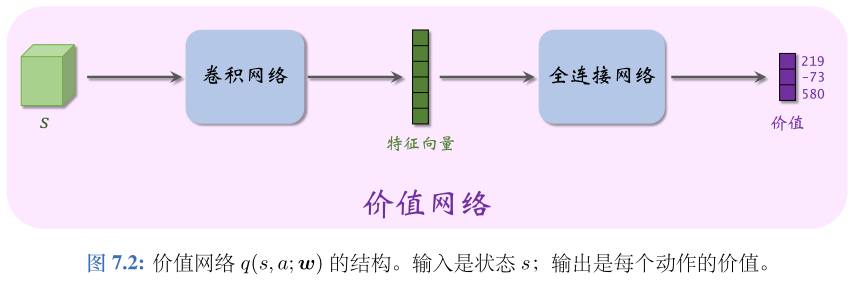
注:区别DQN网络的区别:

2.Actor-critic
策略网络 π ( a ∣ s ; θ ) π(a|s;θ) π(a∣s;θ) 相当于演员,它基于状态 s做出动作 a。价值网络 q ( s , a ; w ) q(s,a;w) q(s,a;w) 相当于评委,它给演员的表现打分,评价在状态 s 的情况下做出动作 a 的好坏程度。
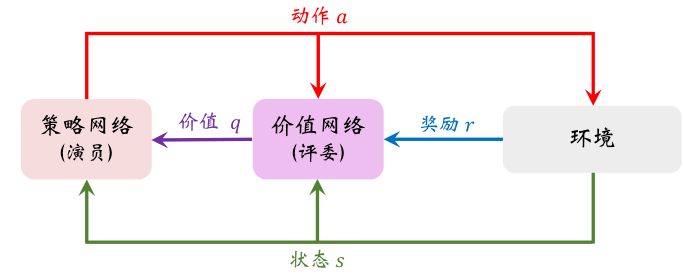
注:
- 训练策略网络(演员)需要的是回报 U,而不是奖励 R。价值网络(评委)能够估算出回报 U 的期望,因此能帮助训练策略网络(演员)。
(1)训练策略网络(演员)
然后做算法的更新:

(2)训练价值网络
用 SARSA算法更新 w w w,提高评委的水平。每次从环境中观测到一个奖励 r r r,把 r r r 看做是真相,用 r r r来校准评委的打分。

----------------------------------------------------------整体的训练步骤:----------------------------------------------------------
