如果你是刚刚接触DRL的同学,那么本文的内容就是引你入胜的第一个小实验。
DRL的学习离不开理论知识,但更不能缺少实践!废话不多说我们直接开始。
0、 实验环境和包版本
① PyCharm 2022 Pro
② gym 0.25.2
③ python 3.8.16
④ numpy 1.23.5
1、初步了解Gym
关于gym(以及其他的库/包),了解它的最好方法我认为是直接看官方文档,因为官方的文档和说明永远是最权威最前沿的,你看再多的类似于这篇文章的学习分享,也都是二手内容,要知道这些Python库是在不断更新升级的,但是这些文章可能不会更新得那么快。在此我强烈建议当你慢慢熟悉这些环境、知识、框架的时候,可以试着通过阅读、查看官方文档这样的方式学习(只是个人建议,可能每个人适合的方式也不一样)。
官方文档链接(建议收藏):
Gym官方文档——Gym Documentation
打开之后就是这样的界面啦:
上图的这一段代码其实就可以直接复制粘贴到你的PyCharm中运行,注意这里的gym版本对应的是0.26.2。
图1中左侧是他的文档目录,新手可以从ENVIRONMENTS下的Classic Control(经典控制环境)开始了解,之前进入炼丹炉的测试代码也是用的gym的经典控制环境(比如小车上山:MountainCar-v0等)。
2、 强化学习代码框架
注意这里仅仅是gym版本为0.25.2的RL框架!不是完整代码!先不要急着跑它。
import gym #导入gym库
env = gym.make("MountainCar-v0", render_mode = "human") #导入/构建实验环境MountainCar-v0,当然你也可以导入其他环境
observation = env.reset() #重置环境/重置一个回合,env.reset()函数返回一个初始观测
agent = load_agent() #load_agent()需要自己编写,是个类。可以理解为控制智能体的算法
for step in range(100): #开始让agent和环境交互
action = agent(observation) #给agent一个观测/状态,agent作出一个动作
observation, reward, done, info = env.step(action) #env.step()函数是环境在agent做出动作后的变化,返回4个值
以上代码仅仅是框架,直接粘贴在PyCharm里是跑不出东西的。
这几行代码展示了RL中智能体和环境之间的交互。具体来说,gym库为我们提供了很多环境,MountainCar-v0只是经典控制里的一个环境;我们导入环境后,利用env.reset()函数重置环境,并给予agent一个初始观测,也就是agent来到这个环境里看到的第一个画面;agent/load_agent()是需要我们自己创造的类,它应该包含我们我们设计的RL的算法,是智慧的结晶,agent类接收到一个观测后,应当依据你赋予的算法输出动作到环境中,与环境进行交互;那么环境在agent的输出动作的影响下,将新的状态/新的观测(observation)、agent刚刚做出的动作的奖励(reward)、游戏是否结束的标志(done)、以及环境的其他信息(info)返回给我们。
2.1、 认识环境
(gym version = 0.25.2)以MountainCar-v0为例:
这个环境将为你提供如下信息(在Gym Documentation中MountainCar-v0的介绍里面写的很清楚):

上图说:
Action Space是一个离散的(Discrete)动作空间,并且有3个动作;Observation Shape (2,)说明观测是一个2维观测;Observation High和Observation Low分别说明了观测值的上下界;由于一个观测是2维的,因此上界的第1个数据0.6代表了第1个维度的上界float值,第2个数据0.07对应了第2个维度的上界float值,下界同理。- 调用该环境MountainCar-v0就用函数
gym.make("MountainCar-v0")即可。
注意:
- 不同环境的观测Observation的维度是不同的,上下界是不同的;
- 不同环境的动作空间Action Space也是不同的;
- 观测空间和动作空间可以是离散的(Discrete)也可以是连续的(Continuous);
- 在 Gym 库中,一般离散空间用
gym.spaces.Discrete类表示,连续空间用gym.spaces.Box类表示 - 环境会更新升级,也许过段时间gym会将MountainCar-v0升级为MountainCar-v1,因此调用环境报错时可以留意PyCharm给你的报错提示或去官网查看环境信息。
2.2、 观测空间

如上图图3所示:
- 第一个观测
0是小车在x轴方向的位置; - 第二个观测
1是小车的速度;
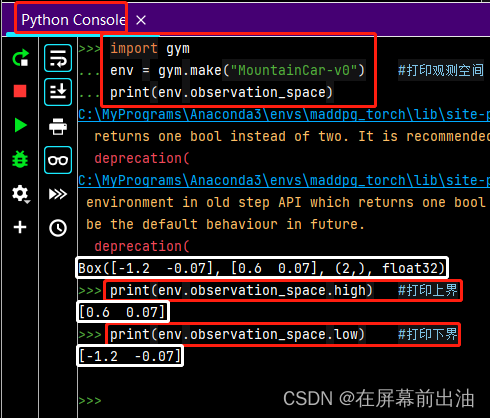
如果想查看一个环境的观测空间,可以在Python Console中用print()打印相关信息:
import gym
env = gym.make("MountainCar-v0") #打印观测空间
print(env.observation_space)
Box([-1.2 -0.07], [0.6 0.07], (2,), float32)
print(env.observation_space.high) #打印上界
[0.6 0.07]
print(env.observation_space.low) #打印下界
[-1.2 -0.07]
运行效果如下:
2.3、 动作空间
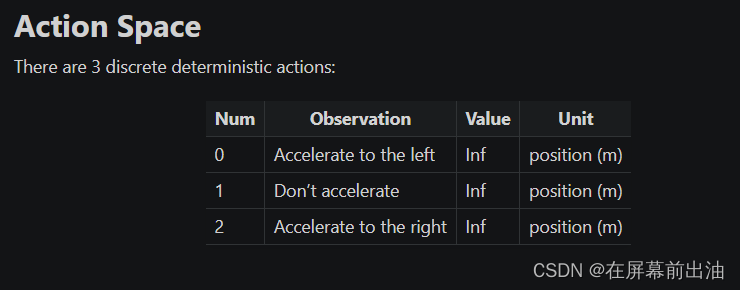
如上图(图5)所示:
- 第一个动作
0是向左加速; - 第二个动作
1是不加速; - 第三个动作
2是向右加速;
动作空间有离散动作空间(Discrete Action Space)和连续动作空间(Continuous Action Space)。
利用print()可以打印出相关信息,如:
import gym
env = gym.make("MountainCar-v0")
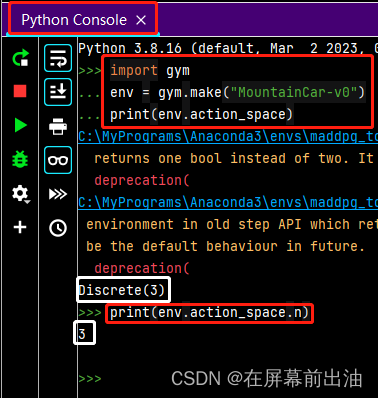
print(env.action_space) #查看MountainCar-v0的动作空间
Discrete(3)
print(env.action_space.n) #查看离散动作空间的动作个数
3
上述代码运行结果:
3、 测试代码
(gym version = 0.25.2)
大致认识了MountainCar-v0环境后,我们可以跑一下测试代码了:
import gym #导入gym
env = gym.make("MountainCar-v0") #导入环境MountainCar-v0,你也可以试试其他环境,比如CartPole-v0等
env.reset() #初始化环境
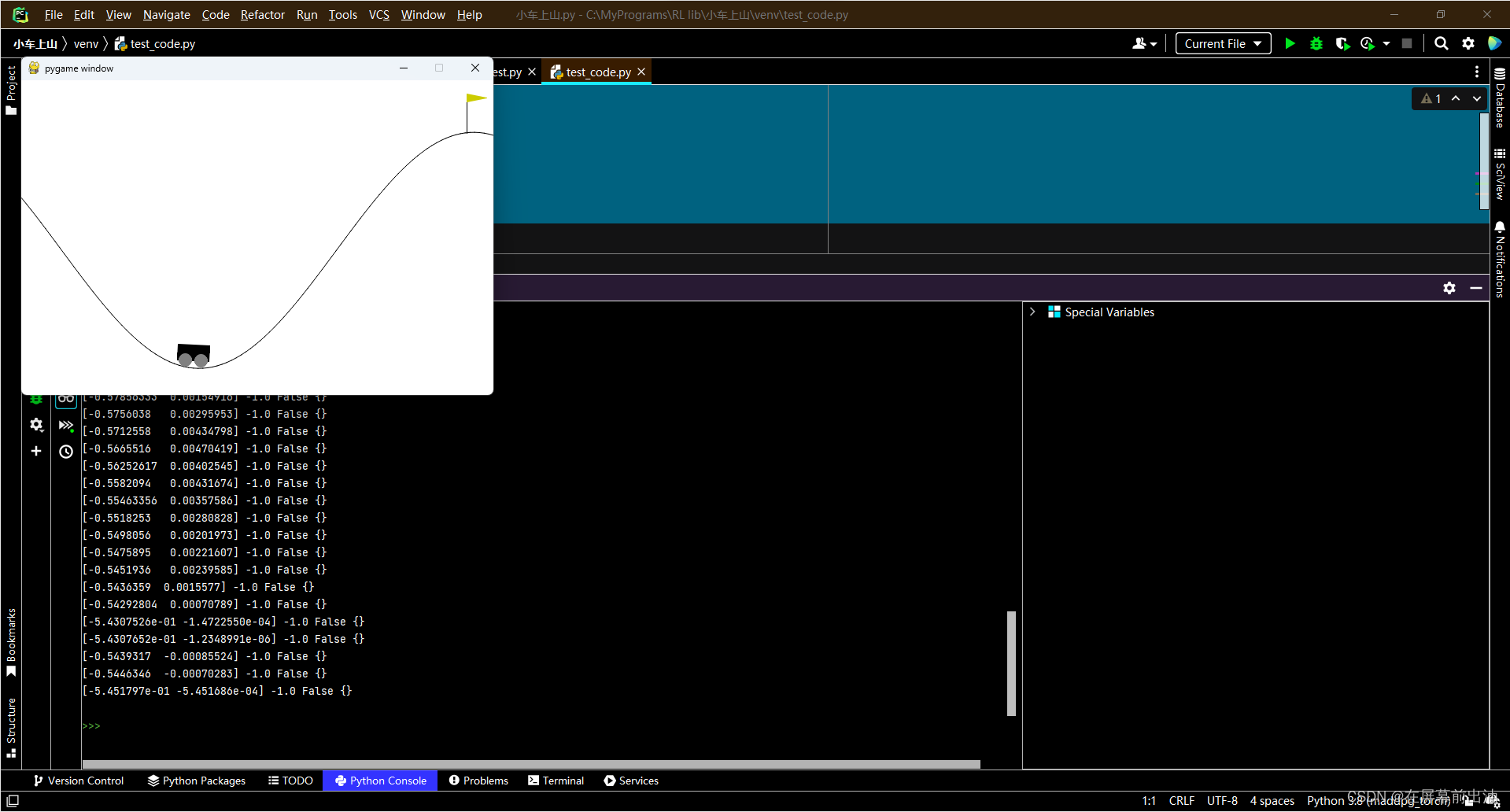
for step in range(1000): #开始交互
env.render() #env.render()方法用于显示环境状态,渲染画面
action = env.action_space.sample() #利用env.action_space.sample()方法在动作空间中随机抽取一个动作,并把这个动作赋给action
observation, reward, done, info = env.step(action) #把动作提交给环境,并存储环境反馈的信息
print(observation, reward, done, info) #打印环境反馈的信息
env.close() #env.close()用于关闭显示窗口,应和env.render()成对存在,确保程序正常结束并释 放资源
运行结果如下:
4、 第1个实验的完整代码
注意:下列代码请在gym 0.25.2下运行
目前而言,我们没有介绍任何RL算法,因此这个实验只是一张gym环境的体验卡。
下列代码中BespokeAgent类并不是一个真正意义的智能体,由代码可见,他里面只包含了一些给定的数学表达式,因此他做出的动作只是靠这些表达式进行的,并没有实现真正的学习。因此下列代码只是一个让我们体会agent-env交互的体验代码。不建议直接复制粘贴,动手敲一敲,仔细读一下,会有自己的体会。
完整代码:
import gym
import numpy as np
env = gym.make("MountainCar-v0") #构建实验环境
class BespokeAgent: #自定义的智能体类
def __init__(self, env):
pass
def decide(self, observation): #决策
position,velocity = observation
lb = min(-0.09 * (position + 0.25) ** 2 + 0.03, 0.3 * (position + 0.9) ** 4 -0.008)
ub = -0.07 * (position + 0.38) ** 2 +0.07
if lb < velocity <ub:
action = 2
else:
action = 0
return action
def learn(self, *args): #学习
pass
def play_montecarlo(env, agent, render=False, train=False):
episode_reward = 0.
observation = env.reset()
while True:
if render:
env.render()
action = agent.decide(observation)
next_observation, reward, done, _ = env.step(action)
episode_reward += reward
if train:
agent.learn(observation, action, reward, done)
if done:
break
observation = next_observation
return episode_reward
agent = BespokeAgent(env)
env.reset(seed=0) #重置一个回合,设置了一个随机数种子,只是为了方便复现实验结果,通常可以把seed=0删掉
episode_reward = play_montecarlo(env, agent, render=True)
print("回合奖励={}".format(episode_reward))
episode_rewards = [play_montecarlo(env, agent) for _ in range(100)] #为了评估智能体性能求出连续交互100回合的平均奖励
print("平均回合奖励={}".format(np.mean(episode_rewards)))
env.close() #关闭环境
注意:小车上山环境有一个参考的回合奖励值-110,如果连续 100 个回合的平均回合奖励大于-110,则认为这个任务被解决了。BespokeAgent 类对应的策略的平均回合奖励就在-110左右。测试智能体在 Gym 库中某个任务的性能时,习惯而言,一般最关心 100 个回合的平均回合奖励。当任务的连续 100 个回合的奖励大于一个指定值时,则认为这个任务被解决了。但实际上不是所有的任务都被指定了回合奖励值。对于没有指定值的任务,就无所谓了。
运行结果:
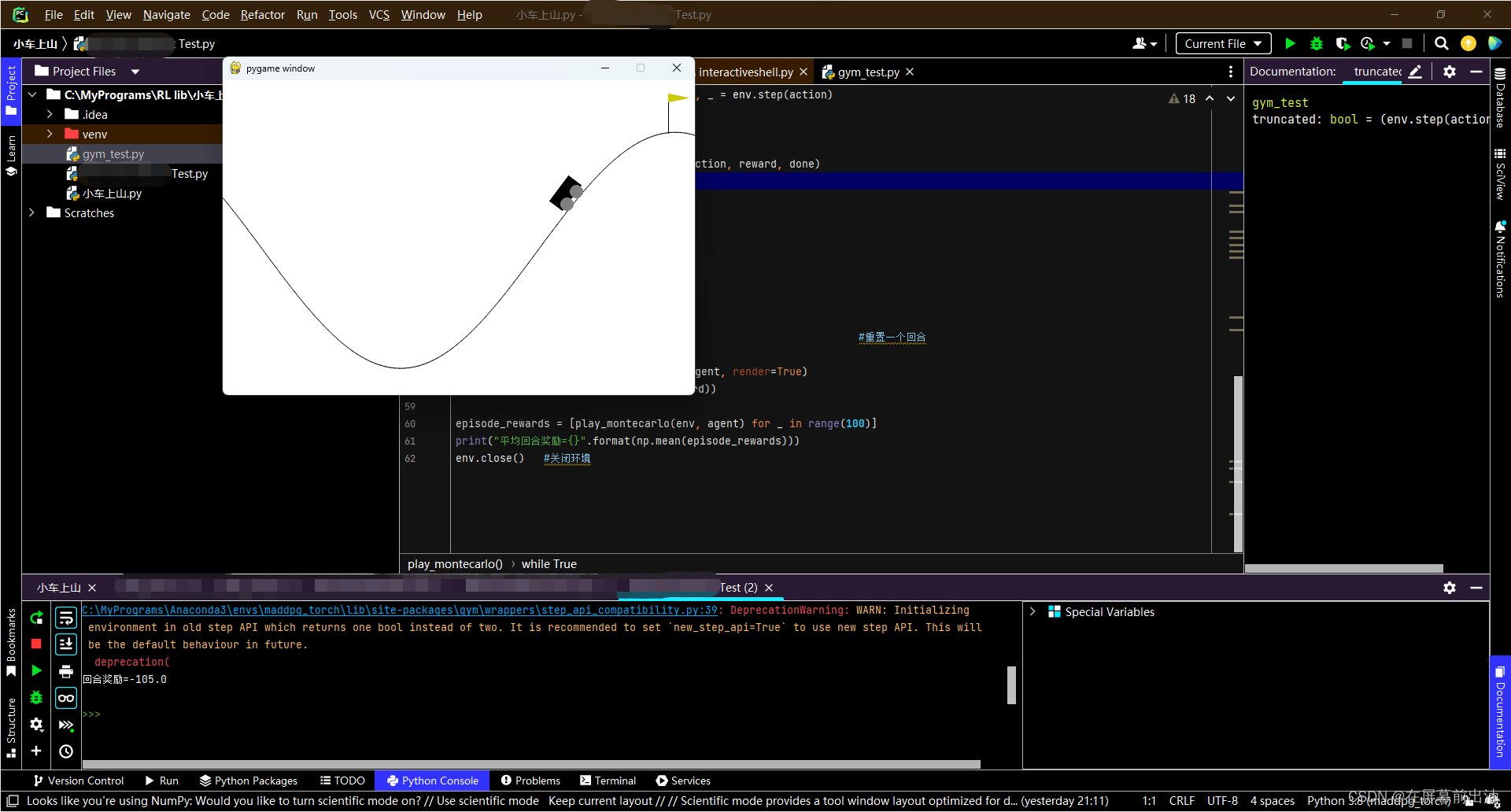
程序运行完后在Python Console里会打印出平均回合奖励: