DRL代码学习打卡-2
1. Q-learning 算法实现走迷宫小游戏
让探索者学会走迷宫
- 黄色的是天堂 (reward 1)
- 黑色的地狱 (reward -1)
- 大多数 RL 是由 reward 导向的,所以定义 reward 是 RL 中比较重要的一点
整个算法就是一直不断更新 Q table 里的值, 然后再根据新的值来判断要在某个 state 采取怎样的 action.
2. 关于环境怎么去写
OpenAI Gym
- RL 主循环
def update():
for episode in range(100):
# initial observation
observation = env.reset()
while True:
# fresh env
env.render()
# RL choose action based on observation
action = RL.choose_action(str(observation))
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL learn from this transition
RL.learn(str(observation), action, reward, str(observation_))
# swap observation
observation = observation_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
- 未知状态获取
class QLearningTable:
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = actions # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions)
# 添加未经历过的状态
def check_state_exist(self, state):
if state not in self.q_table.index:
# append new state to q table
self.q_table = self.q_table.append(
pd.Series(
[0]*len(self.actions),
index=self.q_table.columns,
name=state,
)
)
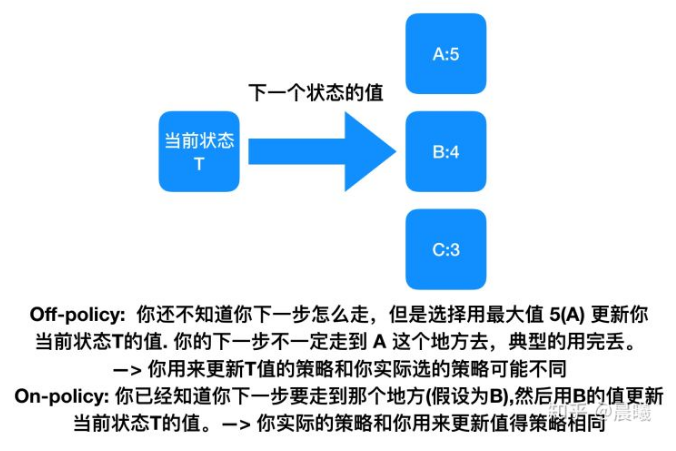
3. 一个疑问
Q-learning 是一个 off-policy 的算法, 因为里面的 max action 让 Q table 的更新可以不基于正在经历的经验(可以是现在学习着很久以前的经验,甚至是学习他人的经验). 不过这一次的例子, 我们没有运用到 off-policy, 而是把 Q-learning 用在了 on-policy 上, 也就是现学现卖, 将现在经历的直接当场学习并运用.
(我觉得这是 off-policy并不是on-policy)
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
On-policy 和 off-policy 的差别我们会在之后的 Deep Q network (off-policy) 学习中见识到. 而之后的教程也会讲到一个 on-policy (Sarsa) 的形式, 我们之后再对比.
on-policy 与 off-policy的本质区别:更新Q值时所使用的方法是沿用既定的策略(on-policy)还是使用新策略(off-policy)。