DRL代码学习打卡-3
1. 什么是 Sarsa (Reinforcement Learning)
和 Q-Learning 几乎一样,唯一不同在上一节已经提过。
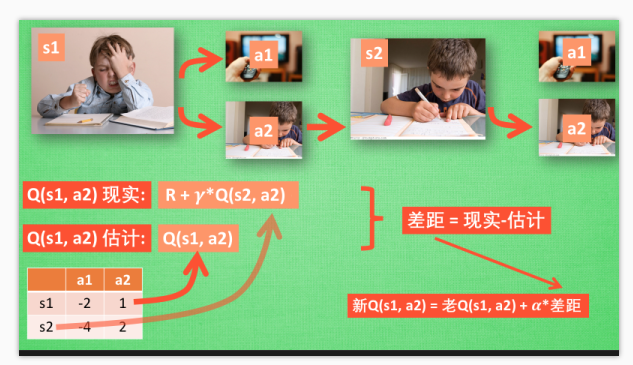
假如我们经历正在写作业的状态 s1, 然后再挑选一个带来最大潜在奖励的动作 a2, 这样我们就到达了继续写作业状态 s2,
而在这一步,
- 如果你用的是 Q learning, 你会观看一下在 s2 上选取哪一个动作会带来最大的奖励, 但是在真正要做决定时, 却不一定会选取到那个带来最大奖励的动作, Q-learning 在这一步只是估计了一下接下来的动作值.
- 而 Sarsa 是实践派, 他说到做到, 在 s2 这一步估算的动作也是接下来要做的动作. 所以 Q(s1, a2) 现实的计算值, 我们也会稍稍改动, 去掉maxQ, 取而代之的是在 s2 上我们实实在在选取的 a2 的 Q 值.
- 最后像 Q learning 一样, 求出现实和估计的差距 并更新 Q 表里的 Q(s1, a2).
特点
- Q learning 机器人永远都会选择最近的一条通往成功的道路(max), 不管这条路会有多危险.
- 而 Sarsa 则是相当保守, 他会选择离危险远远的, 拿到宝藏是次要的, 保住自己的小命才是王道. 这就是使用 Sarsa 方法的不同之处.
def update():
for episode in range(100):
# initial observation
observation = env.reset()
# RL choose action based on observation
action = RL.choose_action(str(observation))
while True:
# fresh env
env.render()
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL choose action based on next observation
action_ = RL.choose_action(str(observation_))
# RL learn from this transition (s, a, r, s, a) ==> Sarsa
RL.learn(str(observation), action, reward, str(observation_), action_)
# swap observation and action
observation = observation_
action = action_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
对比之前 Q-Learning的代码
def update():
for episode in range(100):
# initial observation
observation = env.reset()
while True:
# fresh env
env.render()
# RL choose action based on observation
action = RL.choose_action(str(observation))
# RL take action and get next observation and reward
observation_, reward, done = env.step(action)
# RL learn from this transition
RL.learn(str(observation), action, reward, str(observation_))
# swap observation
observation = observation_
# break while loop when end of this episode
if done:
break
# end of game
print('game over')
env.destroy()
# off-policy
class QLearningTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
super(QLearningTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max() # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
# on-policy
class SarsaTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
super(SarsaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, a_] # next state is not terminal
else:
q_target = r # next state is terminal
self.q_table.loc[s, a] += self.lr * (q_target - q_predict) # update
2. python的继承
class RL(object):
def __init__(self, action_space, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
self.actions = action_space # a list
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float64)
# off-policy
class QLearningTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
super(QLearningTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
# on-policy
class SarsaTable(RL):
def __init__(self, actions, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9):
super(SarsaTable, self).__init__(actions, learning_rate, reward_decay, e_greedy)
def learn(self, s, a, r, s_, a_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
补充知识:
import io
import sys
#改变标准输出的默认编码
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='utf8')
class Root(object):
def __init__(self):
self.x = '这是属性'
def fun(self):
print(self.x)
print('这是方法')
class A(Root):
def __init__(self):
super(A,self).__init__()
print('实例化时执行')
test = A() # 实例化类
test.fun() # 调用方法
print(test.x) # 调用属性
output:
实例化时执行
这是属性
这是方法
这是属性
此时A已经成功继承了父类的属性,所以super().init()的作用也就显而易见了,就是执行父类的构造函数,使得我们能够调用父类的属性。