一、线性分类及准确率
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
path=r'F:/人工智能与机器学习/iris.csv'
df = pd.read_csv(path, header=0)
Iris1=df.values[0:50,0:4]
Iris2=df.values[50:100,0:4]
Iris3=df.values[100:150,0:4]
m1=np.mean(Iris1,axis=0)
m2=np.mean(Iris2,axis=0)
m3=np.mean(Iris3,axis=0)
s1=np.zeros((4,4))
s2=np.zeros((4,4))
s3=np.zeros((4,4))
for i in range(0,30,1):
a=Iris1[i,:]-m1
a=np.array([a])
b=a.T
s1=s1+np.dot(b,a)
for i in range(0,30,1):
c=Iris2[i,:]-m2
c=np.array([c])
d=c.T
s2=s2+np.dot(d,c)
#s2=s2+np.dot((Iris2[i,:]-m2).T,(Iris2[i,:]-m2))
for i in range(0,30,1):
a=Iris3[i,:]-m3
a=np.array([a])
b=a.T
s3=s3+np.dot(b,a)
sw12=s1+s2
sw13=s1+s3
sw23=s2+s3
#投影方向
a=np.array([m1-m2])
sw12=np.array(sw12,dtype='float')
sw13=np.array(sw13,dtype='float')
sw23=np.array(sw23,dtype='float')
#判别函数以及T
#需要先将m1-m2转化成矩阵才能进行求其转置矩阵
a=m1-m2
a=np.array([a])
a=a.T
b=m1-m3
b=np.array([b])
b=b.T
c=m2-m3
c=np.array([c])
c=c.T
w12=(np.dot(np.linalg.inv(sw12),a)).T
w13=(np.dot(np.linalg.inv(sw13),b)).T
w23=(np.dot(np.linalg.inv(sw23),c)).T
#print(m1+m2) #1x4维度 invsw12 4x4维度 m1-m2 4x1维度
T12=-0.5*(np.dot(np.dot((m1+m2),np.linalg.inv(sw12)),a))
T13=-0.5*(np.dot(np.dot((m1+m3),np.linalg.inv(sw13)),b))
T23=-0.5*(np.dot(np.dot((m2+m3),np.linalg.inv(sw23)),c))
kind1=0
kind2=0
kind3=0
newiris1=[]
newiris2=[]
newiris3=[]
for i in range(30,49):
x=Iris1[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
kind1=kind1+1
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
#print(newiris1)
for i in range(30,49):
x=Iris2[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
kind2=kind2+1
elif g13<0 and g23<0 :
newiris3.extend(x)
for i in range(30,50):
x=Iris3[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
kind3=kind3+1
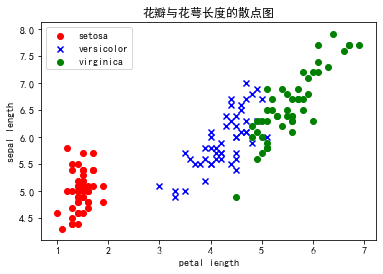
#花瓣与花萼的长度散点图
plt.scatter(df.values[:50, 3], df.values[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(df.values[50:100, 3], df.values[50: 100, 1], color='blue', marker='x', label='versicolor')
plt.scatter(df.values[100:150, 3], df.values[100: 150, 1], color='green', label='virginica')
plt.xlabel('petal length')
plt.ylabel('sepal length')
plt.title("花瓣与花萼长度的散点图")
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False
plt.legend(loc='upper left')
plt.show()
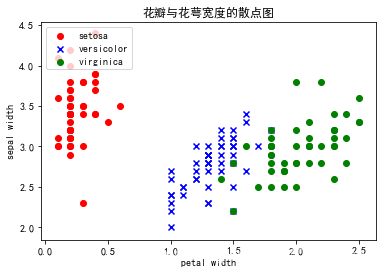
#花瓣与花萼的宽度度散点图
plt.scatter(df.values[:50, 4], df.values[:50, 2], color='red', marker='o', label='setosa')
plt.scatter(df.values[50:100, 4], df.values[50: 100, 2], color='blue', marker='x', label='versicolor')
plt.scatter(df.values[100:150, 4], df.values[100: 150, 2], color='green', label='virginica')
plt.xlabel('petal width')
plt.ylabel('sepal width')
plt.title("花瓣与花萼宽度的散点图")
plt.legend(loc='upper left')
plt.show()
correct=(kind1+kind2+kind3)/60
print("样本类内离散度矩阵S1:",s1,'\n')
print("样本类内离散度矩阵S2:",s2,'\n')
print("样本类内离散度矩阵S3:",s3,'\n')
print('-----------------------------------------------------------------------------------------------')
print("总体类内离散度矩阵Sw12:",sw12,'\n')
print("总体类内离散度矩阵Sw13:",sw13,'\n')
print("总体类内离散度矩阵Sw23:",sw23,'\n')
print('-----------------------------------------------------------------------------------------------')
print('判断出来的综合正确率:',correct*100,'%')

二、数据可视化
导入库
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
读取数据
data = pd.read_csv(r'F:/人工智能与机器学习/iris.csv')
1.前五行数据
data.head()
| Id | SepalLength | SepalWidth | PetalLength | PetalWidth | Species | |
|---|---|---|---|---|---|---|
| 0 | 1 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 2 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 3 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
2.后五行数据
data.tail()
| Id | SepalLength | SepalWidth | PetalLength | PetalWidth | Species | |
|---|---|---|---|---|---|---|
| 145 | 146 | 6.7 | 3.0 | 5.2 | 2.3 | virginica |
| 146 | 147 | 6.3 | 2.5 | 5.0 | 1.9 | virginica |
| 147 | 148 | 6.5 | 3.0 | 5.2 | 2.0 | virginica |
| 148 | 149 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 149 | 150 | 5.9 | 3.0 | 5.1 | 1.8 | virginica |
3.数据描述
data.describe()
| Id | SepalLength | SepalWidth | PetalLength | PetalWidth | |
|---|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 75.500000 | 5.843333 | 3.057333 | 3.758000 | 1.199333 |
| std | 43.445368 | 0.828066 | 0.435866 | 1.765298 | 0.762238 |
| min | 1.000000 | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 38.250000 | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 75.500000 | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 112.750000 | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 150.000000 | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
4.对每种特征计数
data.Species.value_counts()
virginica 50
setosa 50
versicolor 50
Name: Species, dtype: int64
可视化操作
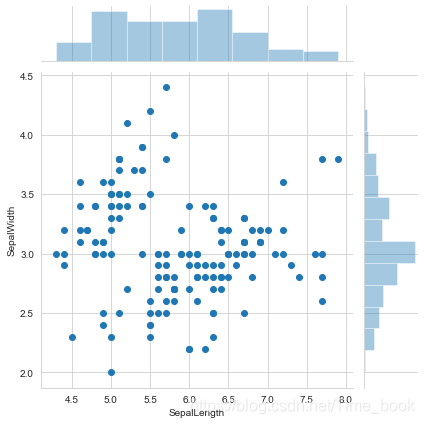
1.绘制花萼的长度与宽度的散点图与直方图
sns.jointplot(x="SepalLength",y="SepalWidth",data=data,kind='scatter');
plt.show()
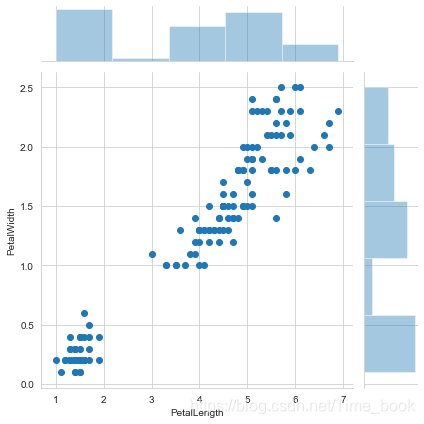
2.绘制花瓣的长度与宽度的散点图与直方图
sns.jointplot(x="PetalLength",y="PetalWidth",data=data,kind='scatter');
plt.show()
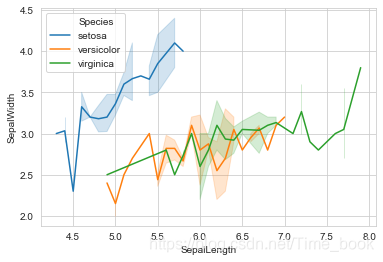
3.绘制花萼的长度与宽度的折线图
sns.lineplot(x="SepalLength",y="SepalWidth",hue='Species',data=data)
plt.show()
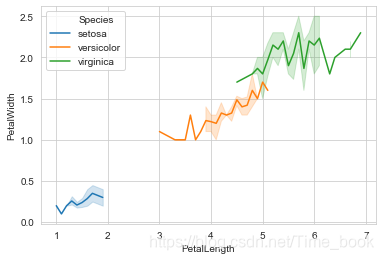
4.绘制花瓣的长度与宽度的折线图
sns.lineplot(x="PetalLength",y="PetalWidth",hue='Species',data=data)
plt.show()
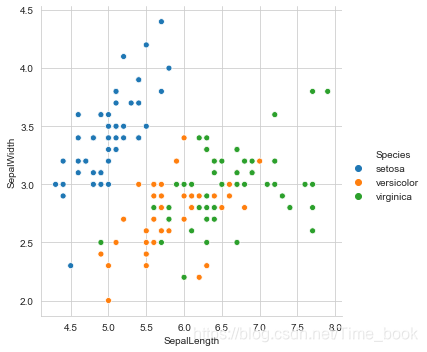
5.绘制花萼的长度与宽度的散点图
sns.relplot(x="SepalLength",y="SepalWidth",hue='Species',data=data)
plt.show()
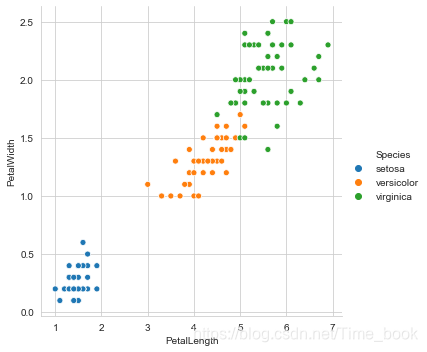
6.绘制花瓣的长度与宽度的散点图
sns.relplot(x="PetalLength",y="PetalWidth",hue='Species',data=data)
plt.show()
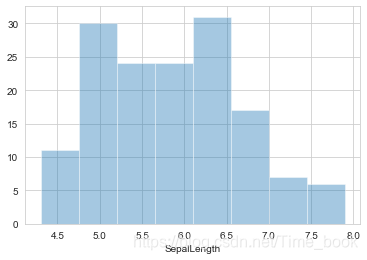
7.绘制花萼长度的直方图
sns.distplot(data.SepalLength,bins=8,hist=True,kde=False)
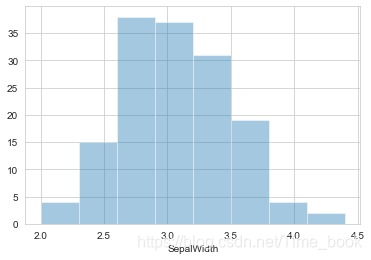
8.绘制花萼宽度的直方图
sns.distplot(data.SepalWidth,bins=8,hist=True,kde=False)
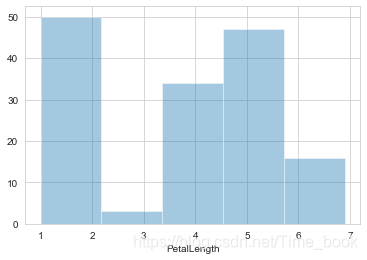
9.绘制花瓣长度的直方图
sns.distplot(data.PetalLength,bins=5,hist=True,kde=False)
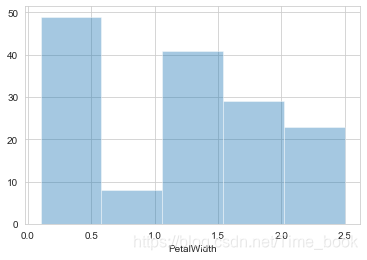
10.绘制花瓣宽度的直方图
sns.distplot(data.PetalWidth,bins=5,hist=True,kde=False)
11.绘制箱线图
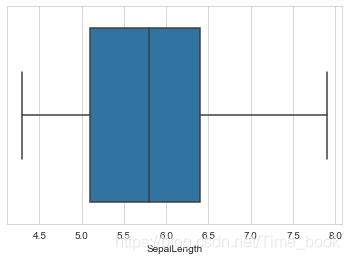
sns.boxplot(x='SepalLength',data=data)
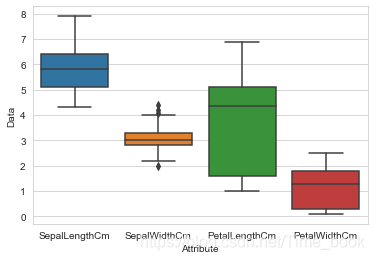
为了更加直观的观察四个属性的关系,将其放入一个图中
#对于每个属性的data创建一个新的DataFrame
Iris1 = pd.DataFrame({"Id": np.arange(1,151), 'Attribute': 'SepalLengthCm', 'Data':data.SepalLength, 'Species':data.Species})
Iris2 = pd.DataFrame({"Id": np.arange(151,301), 'Attribute': 'SepalWidthCm', 'Data':data.SepalWidth, 'Species':data.Species})
Iris3 = pd.DataFrame({"Id": np.arange(301,451), 'Attribute': 'PetalLengthCm', 'Data':data.PetalLength, 'Species':data.Species})
Iris4 = pd.DataFrame({"Id": np.arange(451,601), 'Attribute': 'PetalWidthCm', 'Data':data.PetalWidth, 'Species':data.Species})
#将四个DataFrame合并为一个.
Iris = pd.concat([Iris1, Iris2, Iris3, Iris4])
#绘制箱线图
sns.boxplot(x='Attribute', y='Data', data=Iris)
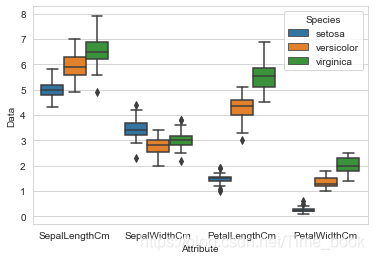
将三种鸢尾花进行对比
sns.boxplot(x='Attribute', y='Data',hue='Species', data=Iris)
12.绘制分布图
sns.pairplot(data.drop('Id',axis=1),hue='Species')
plt.show()

参考文章
http://bob0118.club/?p=268
