基于jupyter notebook的python编程-----机器学习中的线性分类器目录
在进行人工智能机器学习的过程中,我们肯定会遇到对各种各种数据集的处理,然后进行分类;其中,分类是一个非常复杂而且十分难的一个过程,特别是需要对分类算法很好的了解掌握,我们才能进行精确的分类,看似处理的数据,实则我们处理的是未来人工智能深度学习的算法。
本次博客,林君学长将带大家通过举例鸢尾花数据集的分类可视化了解线性分类器,从而理解机器学习中的分类算法
一、机器学习中线性分类器的定义
在机器学习领域,分类的目标是指将具有相似特征的对象聚集。而一个线性分类器则透过特征的线性组合来做出分类决定,以达到此种目的。对象的特征通常被描述为特征值,而在向量中则描述为特征向量。
1、什么是线性分类器?

具体可参考右方链接的资料:线性分类器的定义
2、线性分类器的实现原理

3、设计线性分类器的主要步骤
1)、收集一组具有类别标志的样本X={x1,x2,…,xN}
2)、按需要确定一准则函数J,其值反映分类器的性能,其极值解对应于“最好”的决策
3)、用最优化技术求准则函数J的极值解w* 和w0* ,从而确定判别函数,完成分类器设计
这样就可以得到线性判别函数g(x)=wT+w0或g(x)=a*Ty
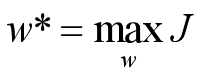
4)、对于未知样本x,计算g(x),判断其类别
4、Fisher线性判别
1)、Fisher线性判别函数是研究线性判别函数中最有影响的方法之一。对线性判别函数的研究就是从R.A.Fisher在1936年发表的论文开始的

由于篇幅原因,该博客就不注重介绍Fisher线性判别的定义及步骤,大家可以参考右边链接进行了解:Fisher线性判别
接下来,我们就通过例题来进行线性分类器的设计,了解到底如何通过代码,对线性规划问题进行合理的分类,以鸢尾花数据集的分类可视化为例
二、例题1–鸢尾花数据集的分类可视化及预测
鸢尾花数据集作为入门经典数据集。Iris数据集是常用的分类实验数据集,由Fisher,1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
在三个类别中,其中有一个类别和其他两个类别是线性可分的。并且,在sklearn中已内置了该数据集,小伙伴们可在文件中查找自己的python安装路径,然后在sklearn包中找到该数据集!
1、准备鸢尾花数据集
1)、查找iris.data数据集的位置
一般来说,首先查找自己的python路径,在python的安装路径中查找库,然后找到包,最后在sklearn目录下的data中查询,如下所示:
D:\xxx\Lib\site-packages\sklearn\datasets\data
xxx代表python的安装路径

2)、加入该项文件夹中没有该数据集,那么我们可以通过以下链接进行下载:
http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
下载后是iris.data文件,然后放在上面路径中遍可以,当然也可以不放,放进去是方便数据集的保管!
2、打开jupyter进行python环境创建
1)、打开Windows终端命令行,输入jupyter notebook,打开我们的jupyter工具,如下所示:
2)、在jupyter的web网页中创建python文件,如下所示:
3)、现在就可以在jupyter的代码行里面输入我们的代码啦!
3、编写鸢尾花数据集的分类可视化代码
1)、导入本次实验需要的库
import numpy as np
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import preprocessing
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
2)、对各个变量进行赋值,取出数据集
import numpy as np
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import preprocessing
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
df = pd.read_csv('D:xxx\Lib\site-packages\sklearn\datasets\data\iris.data', header=0)
x = df.values[:, :-1]
y = df.values[:, -1]
le = preprocessing.LabelEncoder()
le.fit(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
y = le.transform(y)
- xxx代表python的安装路径,当然了,如果下载到别的地方的路径填写对应的路径就好了
- pd.read_csv(path, header=0),header :指定行数用来作为列名,数据开始行数。如果文件中没有列名,则默认为0【第一行数据】,否则设置为None。
- sklearn.preprocessing.LabelEncoder():标准化标签,将标签值统一转换成range(标签值个数-1)范围内,例如[“paris”, “paris”, “tokyo”, “amsterdam”]
- le.fit([‘Iris-setosa’, ‘Iris-versicolor’, ‘Iris-virginica’])含义为将标签集喂给le标签处理器,y = le.transform(y)对y进行转化
3)、构建线性模型
用两个特征构建logistic回归模型
x = x[:, :2]
x = StandardScaler().fit_transform(x)
lr = LogisticRegression() # Logistic回归模型
lr.fit(x, y.ravel()) # 根据数据[x,y],计算回归参数
StandardScaler----计算训练集的平均值和标准差,以便测试数据集使用相同的变换。即fit_transform()的作用就是先拟合数据,然后转化它将其转化为标准形式。调用fit_transform(),其实找到了均值μ和方差σ^2,即已经找到了转换规则,把这个规则利用在训练集上,同样,可以直接将其运用到测试集上(甚至交叉验证集)。
4)、鸢尾花数据集的分类可视化
我们可以在所选特征的范围内,从最大值到最小值构建一系列的数据,使得它能覆盖整个的特征数据范围,然后预测这些值所属的分类,并给它们所在的区域上色,这样我们就能够清楚的看到模型每个分类的区域了
N, M = 500, 500 # 横纵各采样多少个值
x1_min, x1_max = x[:, 0].min(), x[:, 0].max() # 第0列的范围
x2_min, x2_max = x[:, 1].min(), x[:, 1].max() # 第1列的范围
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_hat = lr.predict(x_test) # 预测值
y_hat = y_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) # 预测值的显示
plt.scatter(x[:, 0], x[:, 1], c=y.ravel(), edgecolors='k', s=50, cmap=cm_dark)
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
plt.savefig('2.png')
plt.show()
- np.meshgrid()函数常用于生成网格数据,多用于绘制三维图形
- mpl.colors.ListedColormap([’#77E0A0’, ‘#FF8080’, ‘#A0A0FF’])生成一个颜色的列表
- plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) 根据颜色列表中的值,给传入的坐标进行绘图
5)、计算该线性分类器模型的准确率
y_hat = lr.predict(x)
y = y.reshape(-1)
result = y_hat == y
acc = np.mean(result)
print('准确度: %.2f%%' % (100 * acc))
6)、运行结果

可以看到,鸢尾花数据集共分为三类,并且不同的数据分布在不同的类别之中,从而达到线性分类器的效果;由于我们使用的是两个特征进行数据集的分类,所以分类的准确率并不是高,只有百分之81.21
4、鸢尾花数据集的分类可视化的整体python代码
import numpy as np
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn import preprocessing
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
df = pd.read_csv('D:\\Python\python1\Lib\site-packages\sklearn\datasets\data\iris.data', header=0)
x = df.values[:, :-1]
y = df.values[:, -1]
le = preprocessing.LabelEncoder()
le.fit(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'])
y = le.transform(y)
x = x[:, :2]
x = StandardScaler().fit_transform(x)
lr = LogisticRegression() # Logistic回归模型
lr.fit(x, y.ravel())
N, M = 500, 500 # 横纵各采样多少个值
x1_min, x1_max = x[:, 0].min(), x[:, 0].max() # 第0列的范围
x2_min, x2_max = x[:, 1].min(), x[:, 1].max() # 第1列的范围
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点
x_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_hat = lr.predict(x_test) # 预测值
y_hat = y_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.pcolormesh(x1, x2, y_hat, cmap=cm_light) # 预测值的显示
plt.scatter(x[:, 0], x[:, 1], c=y.ravel(), edgecolors='k', s=50, cmap=cm_dark)
plt.xlabel('petal length')
plt.ylabel('petal width')
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid()
plt.savefig('2.png')
plt.show()
y_hat = lr.predict(x)
y = y.reshape(-1)
result = y_hat == y
acc = np.mean(result)
print('准确度: %.2f%%' % (100 * acc))
以上就是鸢尾花数据集的分类可视化及预测的整个例题的讲解过程,过程较为简单,难的是理解相关代码的意思,其实主要就是线性分类器的含义而来!
接下来,我们将通过如下例题2进行模式的判定,分类,一起看如下步骤吧!
三、例题2–判定一下模式属于哪类?
例2:假如有一个三类问题,其判别式为:
现有一模式为
,该判定应属于哪类?
1、将 代入上述判别函数
1)、将
分别代入上述判别函数中,得:
2、该题三类问题判别原理
1)该题三类问题判别原理如下:
对任意
2)、上述结果判定
因为
3、通过python代码的判定如下所示
1)、python代码如下所示:
#三类问题的判别
def determine(x1,x2):#x1,x2表示模式x=[7,5]^t
d1x=d1[0]*x1+d1[1]*x2+d1[1]
d2x=d2[0]*x1+d2[1]*x2+d2[1]
d3x=d3[0]*x1+d1[1]*x2+d3[1]
if d1x>0:
print("该判定结果:X∈ω1")
elif d2x>0:
print("该判定结果:X∈ω2")
elif d3x>0:
print("该判定结果:X∈ω3")
else:
print("分类失败")
d1=[-1,1,1]#表示d1的系数和截距
d2=[1,1,-4]#表示d2的系数和截距
d3=[-1,1,0]#表示d3的系数和截距
determine(7,5)
2)、运行结果如下所示:

3)、假设模式为
则分类失败,如下所示:

四、Iris数据集的 Fisher分类判别
1、导入需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
2、构建训练集
path=r'D:\\Python\python1\Lib\site-packages\sklearn\datasets\data\iris.data'
df = pd.read_csv(path, header=0)
Iris1=df.values[0:50,0:4]
Iris2=df.values[50:100,0:4]
Iris3=df.values[100:150,0:4]
3、构建样本类内离散度矩阵
#构建样本类内离散度矩阵
m1=np.mean(Iris1,axis=0)
m2=np.mean(Iris2,axis=0)
m3=np.mean(Iris3,axis=0)
s1=np.zeros((4,4))
s2=np.zeros((4,4))
s3=np.zeros((4,4))
for i in range(0,30,1):
a=Iris1[i,:]-m1
a=np.array([a])
b=a.T
s1=s1+np.dot(b,a)
for i in range(0,30,1):
c=Iris2[i,:]-m2
c=np.array([c])
d=c.T
s2=s2+np.dot(d,c)
for i in range(0,30,1):
a=Iris3[i,:]-m3
a=np.array([a])
b=a.T
s3=s3+np.dot(b,a)
4、构建总体类内离散度矩阵
#总体类内离散度矩阵
sw12=s1+s2
sw13=s1+s3
sw23=s2+s3
5、规定投影方向、判别函数以及阈值T
#投影方向
a=np.array([m1-m2])
sw12=np.array(sw12,dtype='float')
sw13=np.array(sw13,dtype='float')
sw23=np.array(sw23,dtype='float')
a=m1-m2
a=np.array([a])
a=a.T
b=m1-m3
b=np.array([b])
b=b.T
c=m2-m3
c=np.array([c])
c=c.T
w12=(np.dot(np.linalg.inv(sw12),a)).T
w13=(np.dot(np.linalg.inv(sw13),b)).T
w23=(np.dot(np.linalg.inv(sw23),c)).T
#判别函数以及阈值T
T12=-0.5*(np.dot(np.dot((m1+m2),np.linalg.inv(sw12)),a))
T13=-0.5*(np.dot(np.dot((m1+m3),np.linalg.inv(sw13)),b))
T23=-0.5*(np.dot(np.dot((m2+m3),np.linalg.inv(sw23)),c))
6、通过判别函数进行判别,求解正确率
#通过判别函数进行判别,求解正确率
kind1=0
kind2=0
kind3=0
newiris1=[]
newiris2=[]
newiris3=[]
for i in range(30,49):
x=Iris1[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
kind1=kind1+1
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
for i in range(30,49):
x=Iris2[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
kind2=kind2+1
elif g13<0 and g23<0 :
newiris3.extend(x)
for i in range(30,49):
x=Iris3[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
kind3=kind3+1
correct=(kind1+kind2+kind3)/60
7、打印输出及结果测试
1、打印输出
print("样本类内离散度矩阵S1:",s1,'\n')
print("样本类内离散度矩阵S2:",s2,'\n')
print("样本类内离散度矩阵S3:",s3,'\n')
print("总体类内离散度矩阵Sw12:",sw12,'\n')
print("总体类内离散度矩阵Sw13:",sw13,'\n')
print("总体类内离散度矩阵Sw23:",sw23,'\n')
print('判断出来的综合正确率:',correct*100,'%')
2、结构测试

8、Iris数据集的 Fisher分类判别整体python代码
#导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#构建训练集
path=r'D:\\Python\python1\Lib\site-packages\sklearn\datasets\data\iris.data'
df = pd.read_csv(path, header=0)
Iris1=df.values[0:50,0:4]
Iris2=df.values[50:100,0:4]
Iris3=df.values[100:150,0:4]
#构建样本类内离散度矩阵
m1=np.mean(Iris1,axis=0)
m2=np.mean(Iris2,axis=0)
m3=np.mean(Iris3,axis=0)
s1=np.zeros((4,4))
s2=np.zeros((4,4))
s3=np.zeros((4,4))
for i in range(0,30,1):
a=Iris1[i,:]-m1
a=np.array([a])
b=a.T
s1=s1+np.dot(b,a)
for i in range(0,30,1):
c=Iris2[i,:]-m2
c=np.array([c])
d=c.T
s2=s2+np.dot(d,c)
for i in range(0,30,1):
a=Iris3[i,:]-m3
a=np.array([a])
b=a.T
s3=s3+np.dot(b,a)
sw12=s1+s2
sw13=s1+s3
sw23=s2+s3
#投影方向
a=np.array([m1-m2])
sw12=np.array(sw12,dtype='float')
sw13=np.array(sw13,dtype='float')
sw23=np.array(sw23,dtype='float')
#判别函数以及T
a=m1-m2
a=np.array([a])
a=a.T
b=m1-m3
b=np.array([b])
b=b.T
c=m2-m3
c=np.array([c])
c=c.T
w12=(np.dot(np.linalg.inv(sw12),a)).T
w13=(np.dot(np.linalg.inv(sw13),b)).T
w23=(np.dot(np.linalg.inv(sw23),c)).T
T12=-0.5*(np.dot(np.dot((m1+m2),np.linalg.inv(sw12)),a))
T13=-0.5*(np.dot(np.dot((m1+m3),np.linalg.inv(sw13)),b))
T23=-0.5*(np.dot(np.dot((m2+m3),np.linalg.inv(sw23)),c))
#通过判别函数进行判别,求解正确率
kind1=0
kind2=0
kind3=0
newiris1=[]
newiris2=[]
newiris3=[]
for i in range(30,49):
x=Iris1[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
kind1=kind1+1
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
for i in range(30,49):
x=Iris2[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
kind2=kind2+1
elif g13<0 and g23<0 :
newiris3.extend(x)
for i in range(30,49):
x=Iris3[i,:]
x=np.array([x])
g12=np.dot(w12,x.T)+T12
g13=np.dot(w13,x.T)+T13
g23=np.dot(w23,x.T)+T23
if g12>0 and g13>0:
newiris1.extend(x)
elif g12<0 and g23>0:
newiris2.extend(x)
elif g13<0 and g23<0 :
newiris3.extend(x)
kind3=kind3+1
correct=(kind1+kind2+kind3)/60
print("样本类内离散度矩阵S1:",s1,'\n')
print("样本类内离散度矩阵S2:",s2,'\n')
print("样本类内离散度矩阵S3:",s3,'\n')
print("总体类内离散度矩阵Sw12:",sw12,'\n')
print("总体类内离散度矩阵Sw13:",sw13,'\n')
print("总体类内离散度矩阵Sw23:",sw23,'\n')
print('判断出来的综合正确率:',correct*100,'%')
以上就是本次博客的全部内容啦,希望通过对本次博客的阅读,可以帮助小伙伴理解如何对不同类的问题进行对应的判断哦,同时,希望大家掌握判定的方法,这样才是解决几类问题判定的关键因素!
遇到问题的小伙伴记得留言评论哦,林君学长看到会为大家进行解答的,这个学长不太冷!
陈一月的又一天编程岁月^ _ ^
