Seaborn可视化
Seaborn 是一个基于 matplotlib 且数据结构与 pandas 统一的统计图制作库,很多使用跟matplotlib的使用方法相同,颜色配置等,之前matplotlib绘图时传入的数据都是列表,也可以直接传入Series和DataFrame对象,索引作为x轴,值作为y轴;图表的绘制会涉及统计学的相关内容。Seaborn提前已经定义好了一套自己的风格,也封装了一系列的方便的绘图函数(要是调整线条颜色、粗细的话会比较麻烦),之前通过matplotlib需要很多代码才能完成的绘图,使用seaborn可能就是一行代码的事情。
学习文档
官网:http://seaborn.pydata.org/
中文学习文档:https://www.cntofu.com/book/172/docs/1.md
1.风格管理
seaborn绘图的过程,底层是matplotlib的内容,封装了高级别的函数,通过调用函数来实现图表的绘制,seaborn里方法的调用,其实是调用函数实现的过程。
绘图风格
默认是白颜色的背景,可以用sns.set(),是seaborn的主题应用,使用默认的主题来绘制图表,与上图相比没有了刻度线,多了灰色的网格布局。
主题背景的更改:style must be one of white, dark, whitegrid, darkgrid, ticks,只能从提供的几种主题进行更改。也可以自己去设计一套主题,好比手机的主题。
可以利用移除轴脊柱的方法去掉图表的上边框和右边框。
可以对风格的设置参数有很多,可以根据不同的需求进行设置

颜色风格
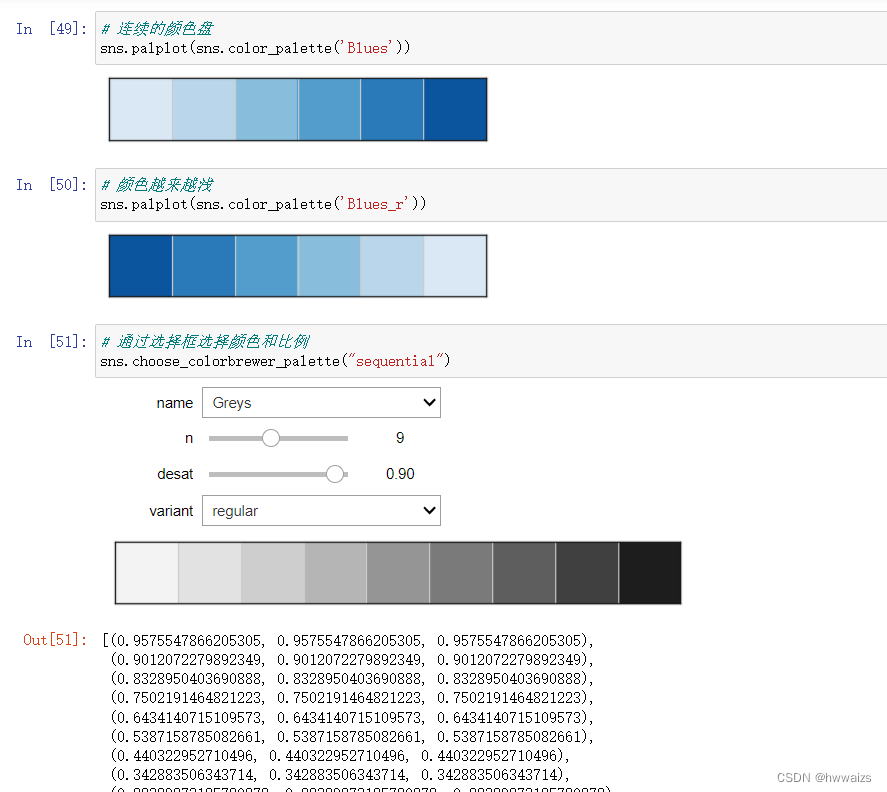
通过循环,遍历颜色深浅范围。

把颜色按照某个程度划分为8个层次,整颜色的亮度和饱和度,l为亮度,0.1-0.9越来越浅,s为饱和度,数字越大,色彩越饱和

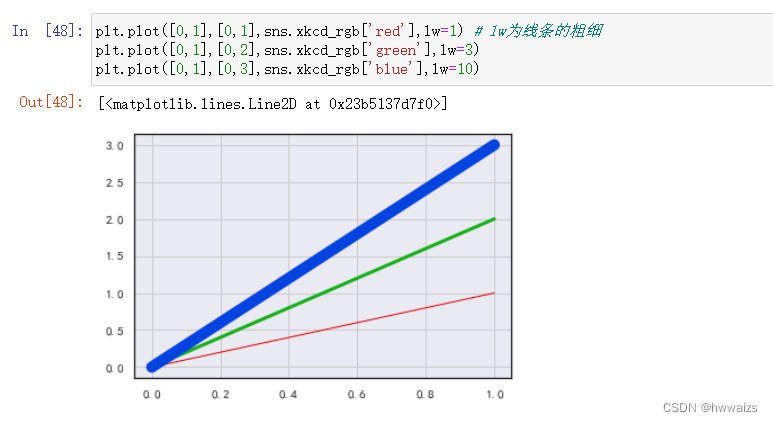
通过调整lw参数,调整线条的粗细
通过选择框和连续的颜色盘来调整颜色
2.常用图表绘制
要清楚图表所对应的函数类型。图表的作用:1. 与数据清洗是相辅相成的,通过散点图、箱线图、直方图观察数据的离群点和异常值,通过图表进行观看,发现异常值及时进行清理,使图表更加的整洁。数据清洗并不是某个环节完成的功能,是遍布数据分析的整个阶段,数据分析不停止,就会随时随地的做数据清洗。2.支持验证性和预测型的数据分析,常见的数据分析是通过数据展现图表,绘制直观的图表供观看。验证性的数据分析是提出假设,通过数据去验证假设是否成立(通过今年每个月广告的投放导致营业额增加,就可以预测广告投入与营业额是正相关,通过数据去验证假设的正确与否;通过去年和千年的数据发现二者没有相关性,就说明假设是不成立的)。预测型的数据分析要选择使用哪些特征,利用关系之间的统计图,了解特征之间的关系,选择什么样的模型进行预测
条形图
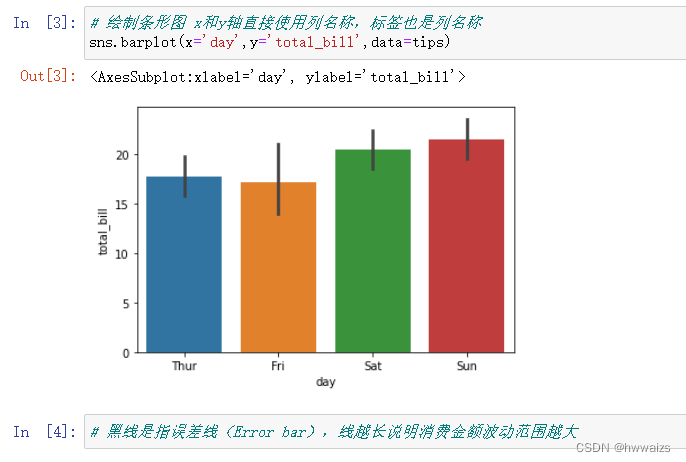
条形图(sns.barplot),可以用pandas直接读取文件,也可以用seaborn的方法去读取,如果读取的时候不加data_home参数会从官网进行下载,data_home参数可以从指定的文件夹下读取本地文件
相对于传统的柱形图,每个图形上多列一条黑线,黑线是指误差线(Error bar),线越长说明消费金额波动范围越大。
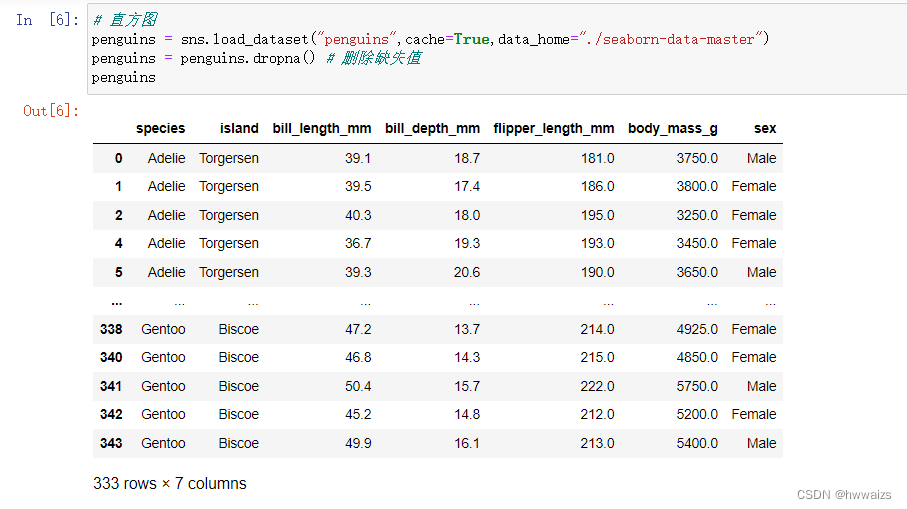
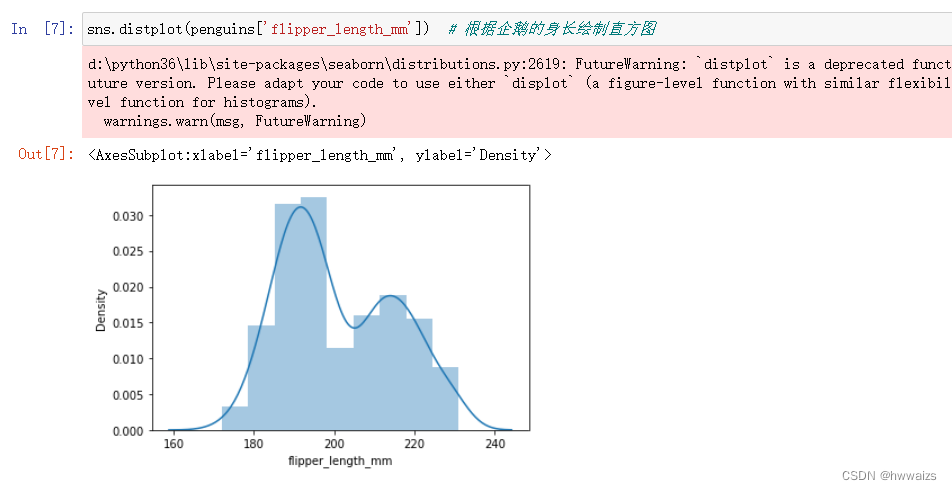
直方图
直方图(sns.distplot)
饼图(不支持)
折线图
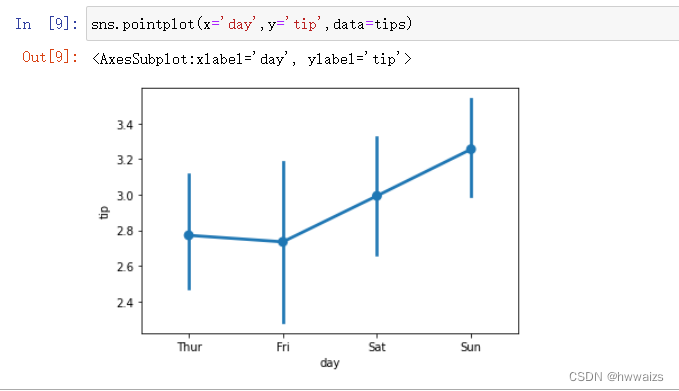
折线图(sns.pointplot)
每个点上竖直的线代表置信区间,在方法里还有个ci参数,如果ci=50,竖线会普遍的变短,若ci=68,说明有68%的概率确信周五给的消费在这个范围内。不写ci参数时,竖线比较长,周五给的小费在上下边缘内,当概率为68%时,会有68%的把握给的小费竖线集中的的范围内。
散点图
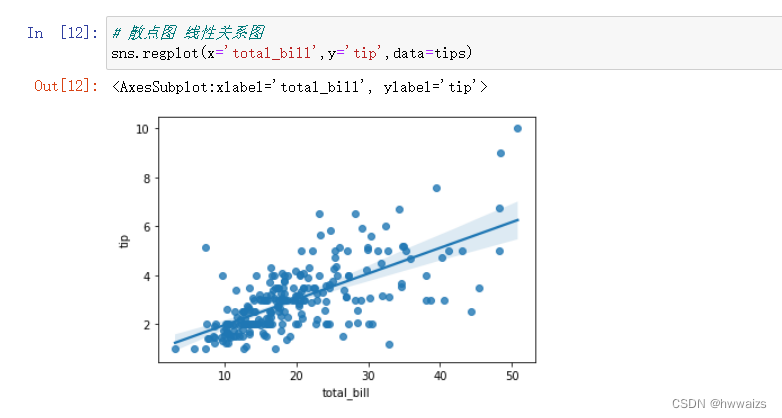
散点图(sns.regplot),绘制后会有条直线,直线表示x轴和y轴之间的线性回归关系,消费的金额多,给的小费也就多。
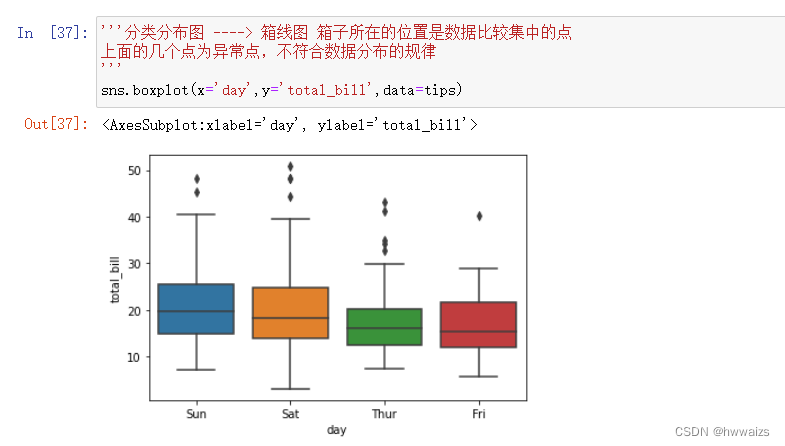
箱线图
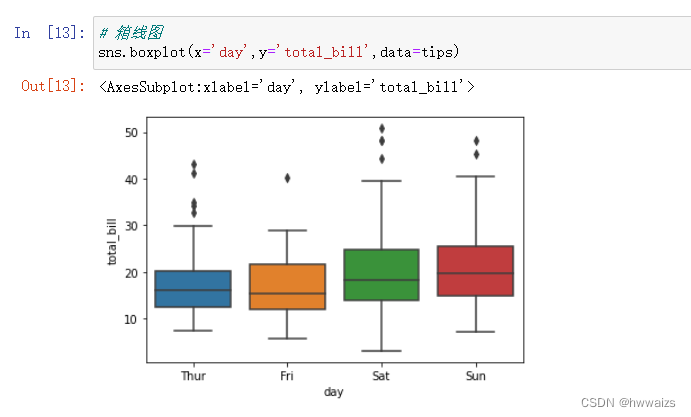
箱线图(sns.boxplot),每天都会有超过箱线消费金额范围的人就餐,周四大部分人的消费靠近下边缘,周五的消费居于上下边缘中间。
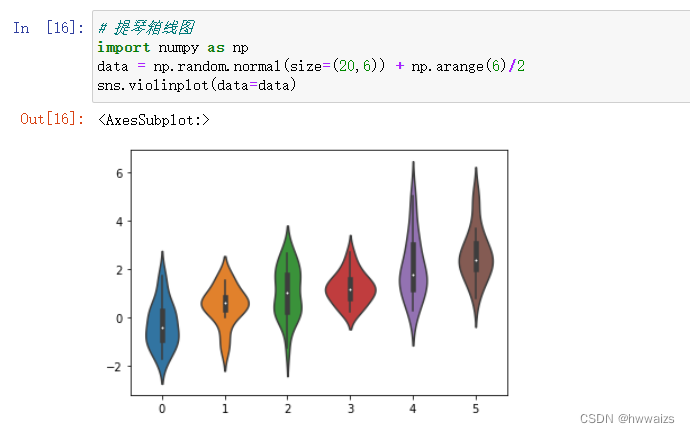
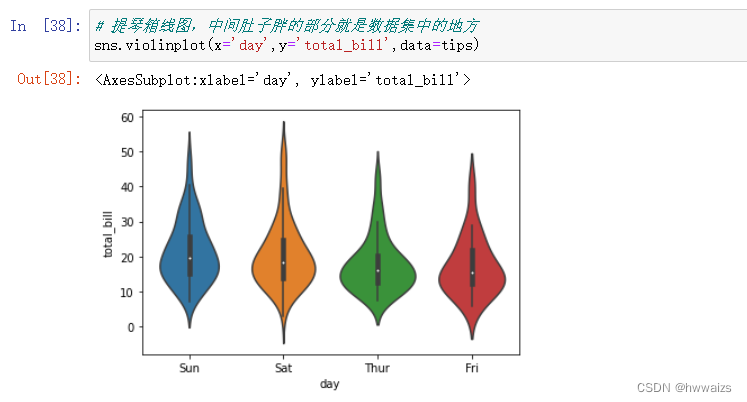
提琴箱线图(sns.violinplot),白色的点相当于箱线图中间的黑实线,黑色线条对应于箱线图的箱子
3.绘图方法(重要)
画图的目的是从图表中获取有用的信息,了解图表适用的方面,绘制图表的场景,根据图表反馈的信息得到结论,做进一步的分析。
做数据分析前,一定要先理解数据,对数据的理解程度越深,画图的时候思路就越清晰。
折线图表示数据之间的趋势,两列数据之间的关系一般用散点图
线性关系可视化
散点图例子
relplot方法可以绘制线性关系图形,绘制出的图表不带线性回归的直线,比scatterplot更加灵活。
需求:绘图展现出总金额与小费的关系,绘制散点图
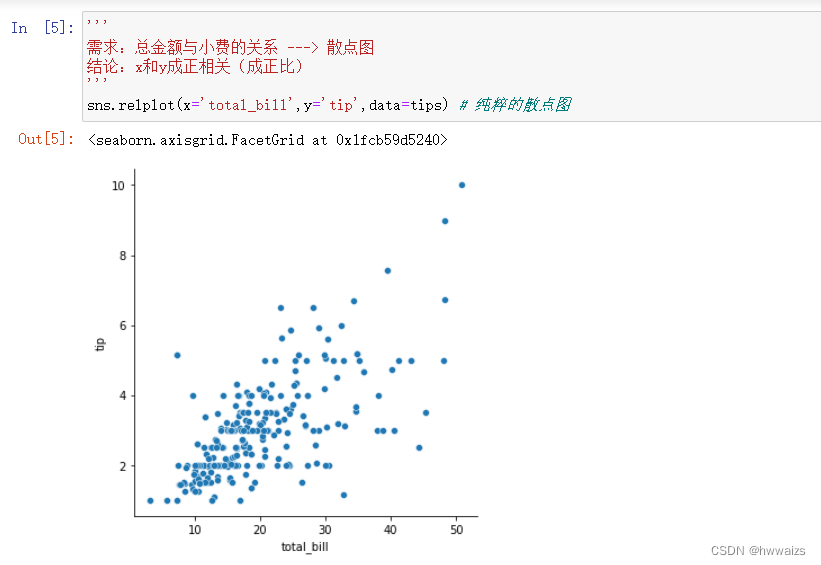
增加需求:周几出去吃饭的人最多,增加一个分类因素,周几
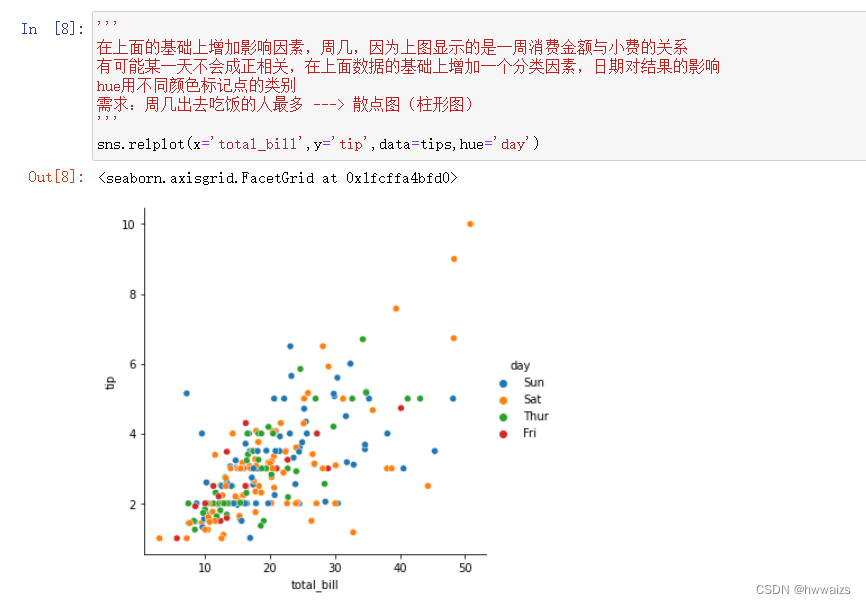
需求:对比午餐和晚餐人数,通过点的数量对比时间段人的多少
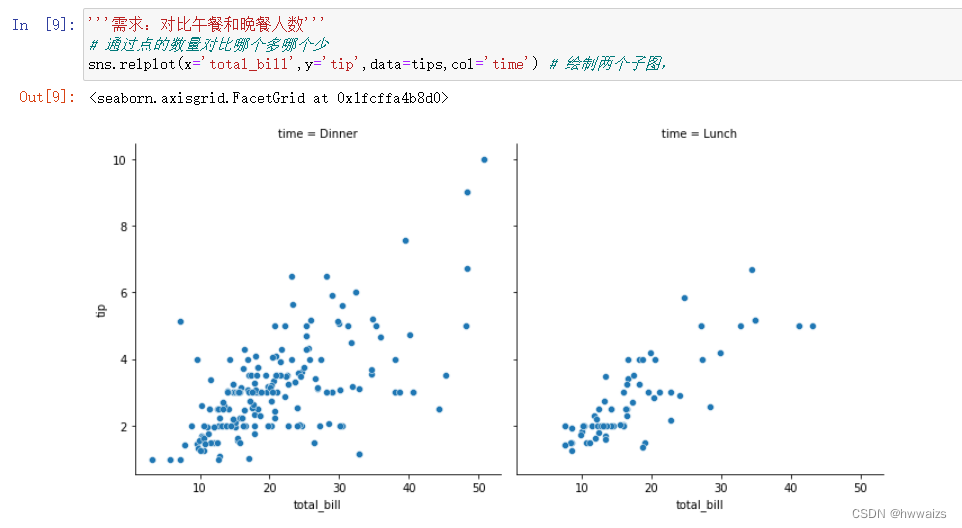
把两个子图竖着排列,可以控制参数 col_wrap=1 一行只能容纳一个子图,控制列数;row_wrap 控制行数;或者改变col为row 改变子图摆放的位置
需求: 根据就餐人数来显示不同的点,就餐人数越多,点就越大,size指点的大小
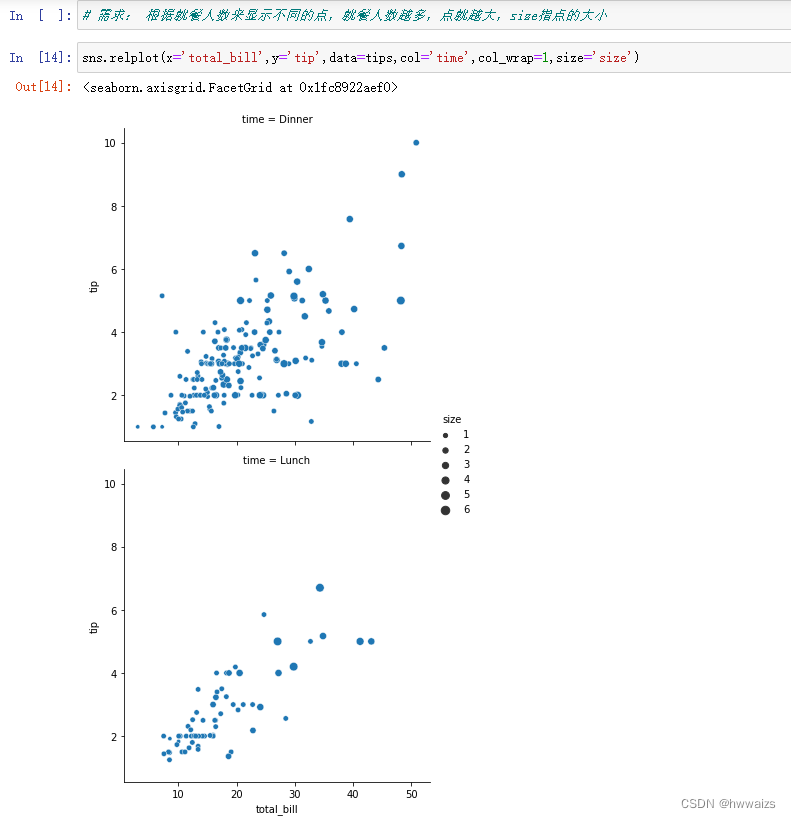
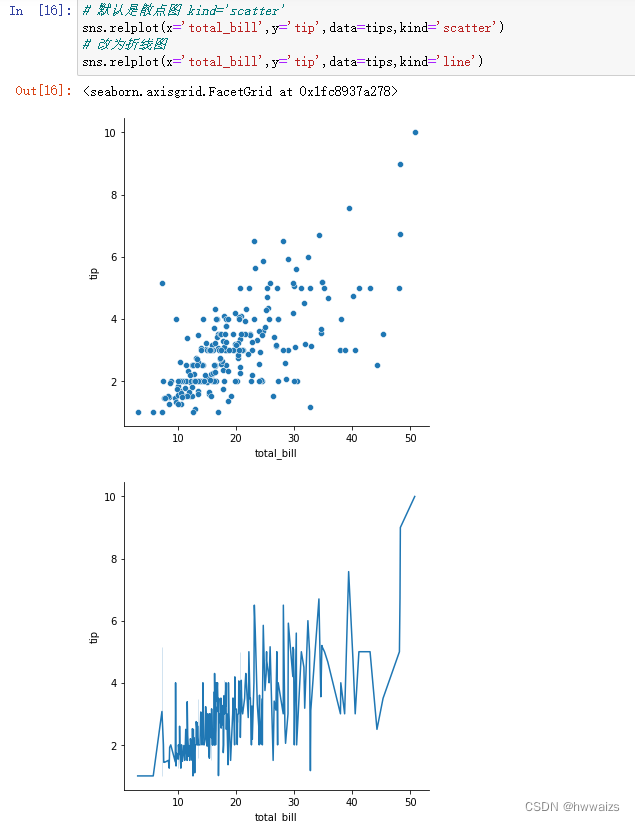
默认是散点图,kind=‘scatter’,修改kind='line’改为折线图
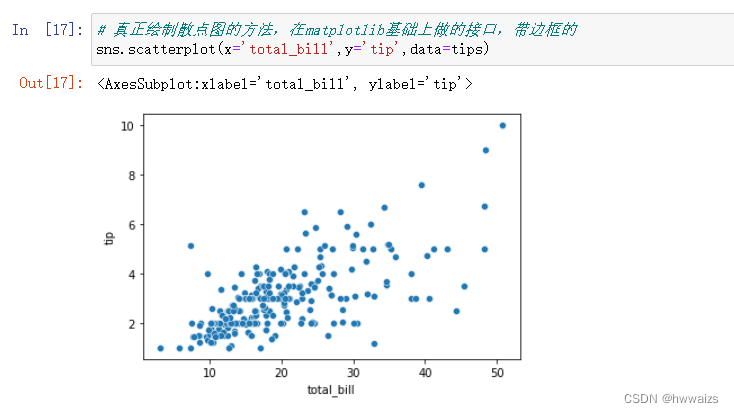
scatterplot 是真正绘制散点图的方法,绘制的图表带边框,在matplotlib基础上做的接口。
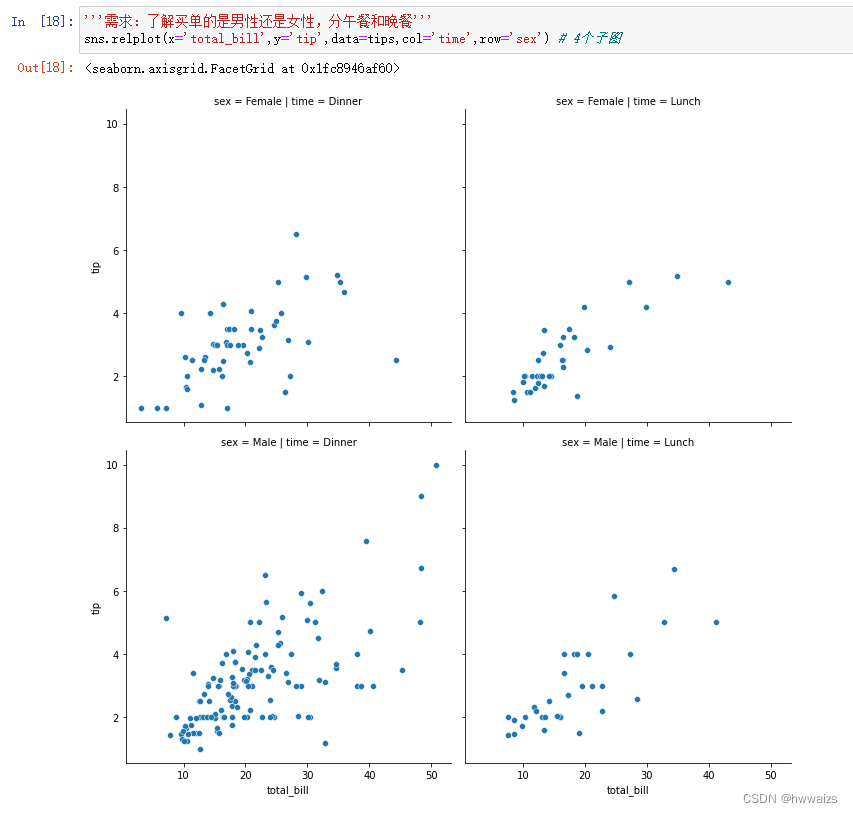
需求:了解买单的是男性还是女性,分午餐和晚餐,会绘制出4个子图
折线图例子
relplot 对折线图和散点图的封装,使用比较灵活,可以通过参数控制绘制哪个图形,更加便捷。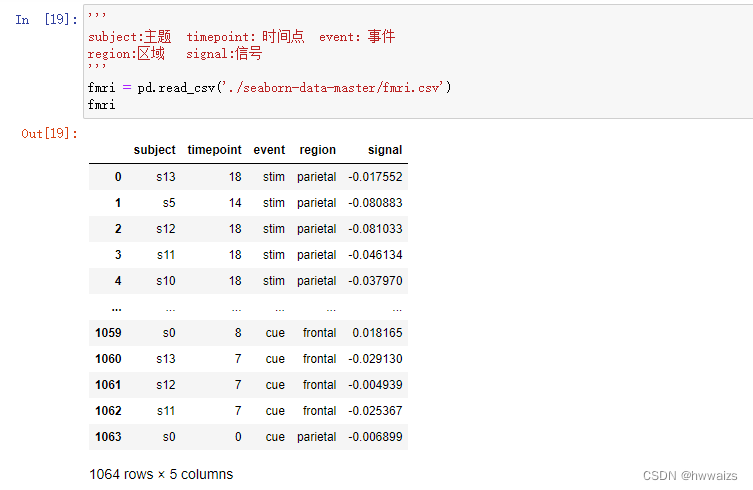
需求:了解信号值和时间点的变化关系,绘制折线图
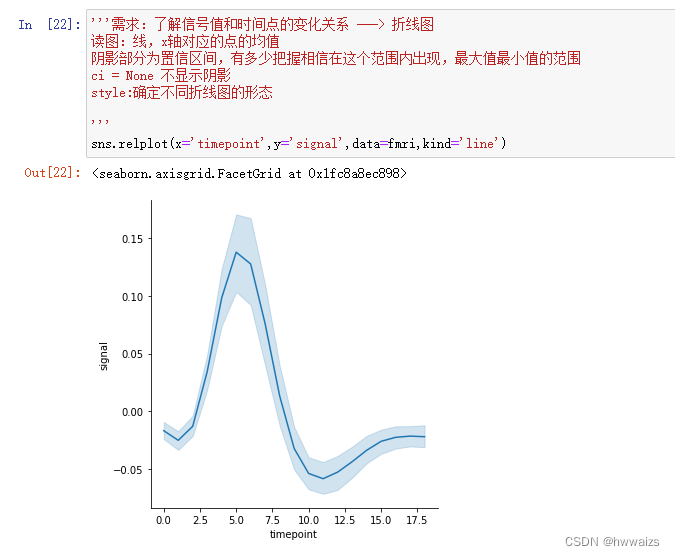
增加需求:同区域内,信号值和时间点的变化
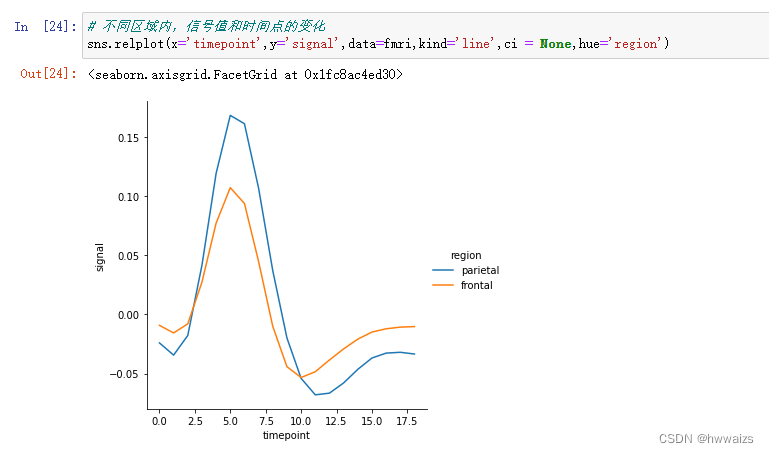
增加需求,不同事件,不同区域内,信号值和时间点的变化,会根据事件的多少画出多个子图
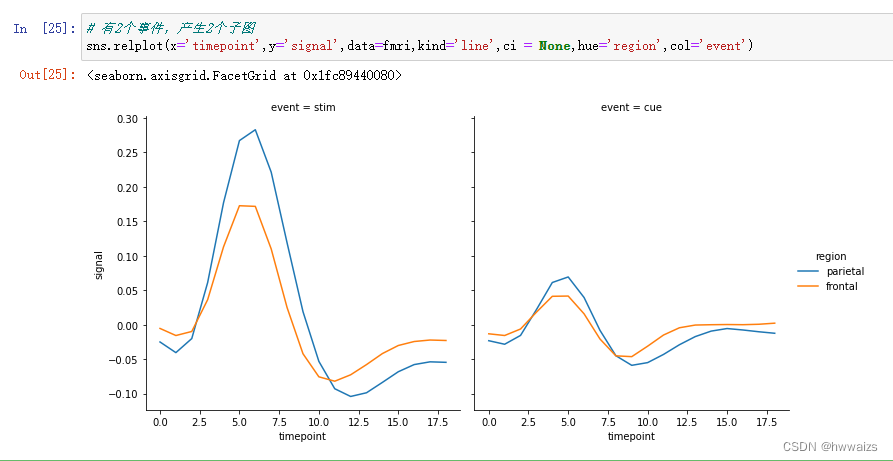
增加需求:根据不同的区域确定不同折线图的形态,根据区域的多少产生多种折线图的形态。跟散点图一样,也可以控制参数 col_wrap=1 一行只能容纳一个子图,控制列数;row_wrap 控制行数;或者改变col为row 改变子图摆放的位置
真正绘制折线的方法,lineplot没有kind参数,没有col参数
分类数据可视化
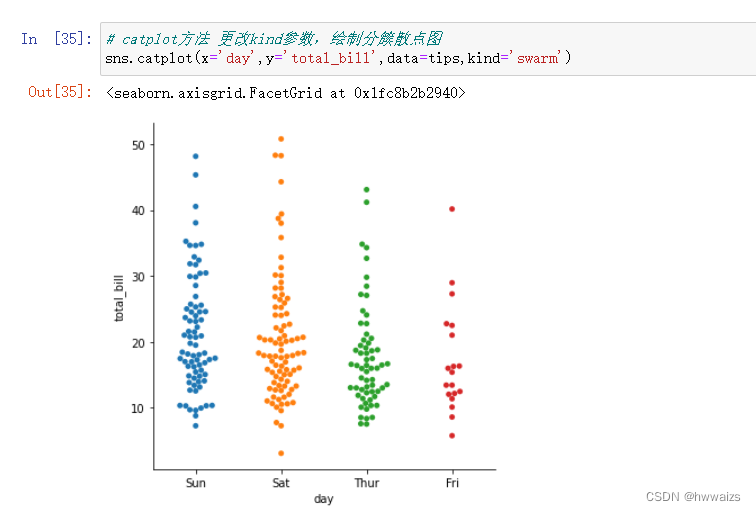
catplot是高级函数,通过改变kind,绘制分布散点图、分布箱线图、分簇散点图,也可以用每个图表各自的方法进行绘制。
分类散点图
默认kind=strip
使用绘制散点图的方法stripplot进行绘制
分簇散点图
用分簇散点图的方法swarmplot进行绘制
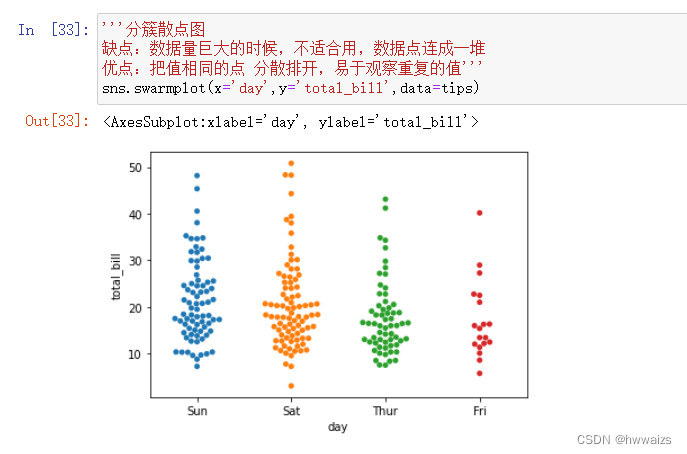
更改参数kind=swarm 绘制分簇散点图
分类分布图–箱线图
用箱线图的方法boxplot进行绘制,也可以使用catplot方法,更改kind参数进行绘制
分类分布图–提琴箱线图
用提琴箱线图的方法violinplot进行绘制,也可以使用catplot方法,更改kind参数进行绘制
分类柱形图
使用catplot方法,更改kind参数进行绘制
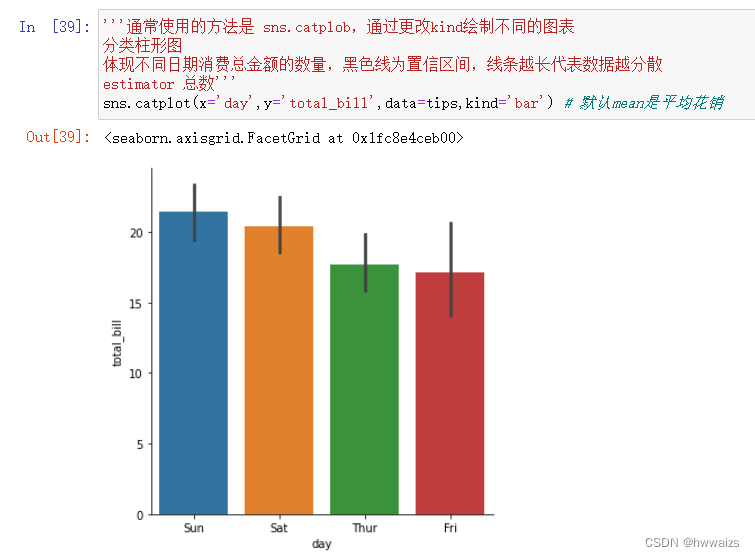
默认estimator参数为mean,求平均,可以传入函数sum、max、min等函数
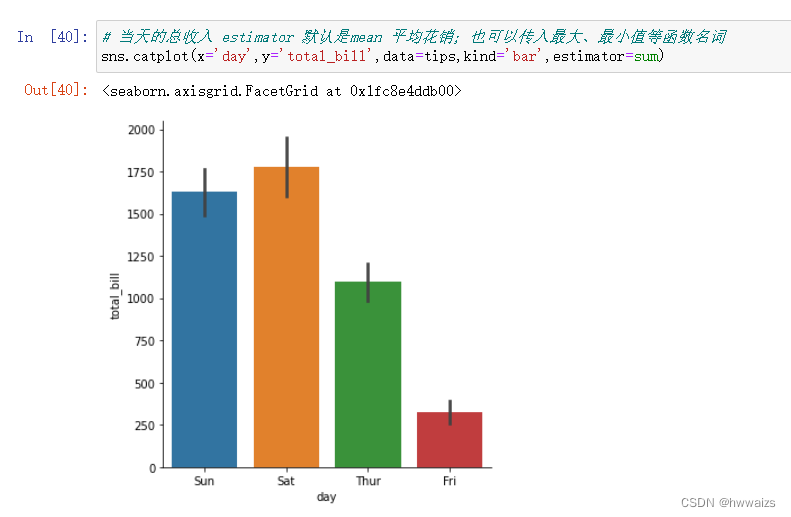
使用barplot方法绘制柱状图
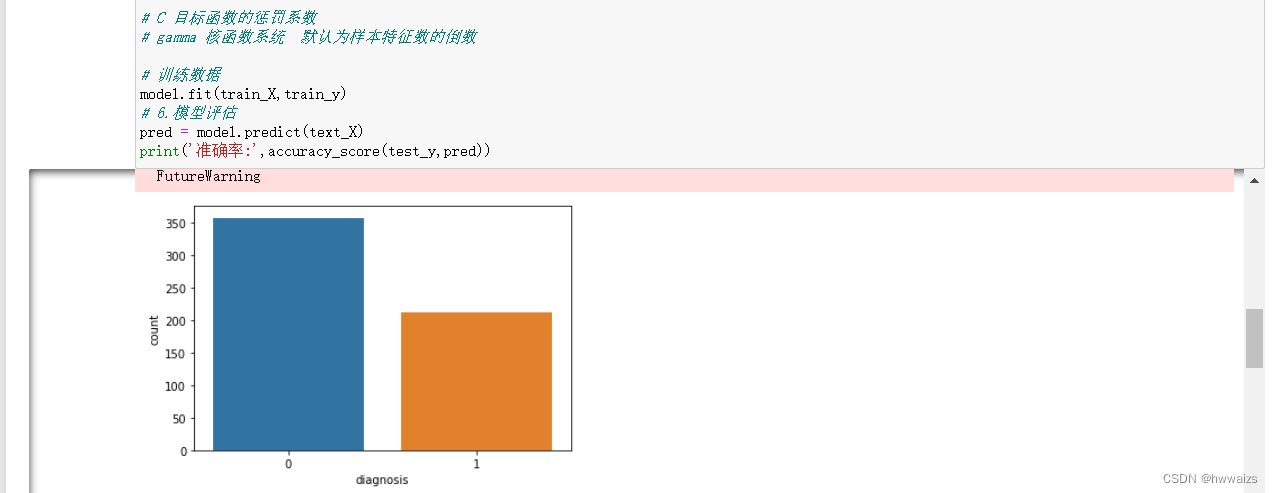
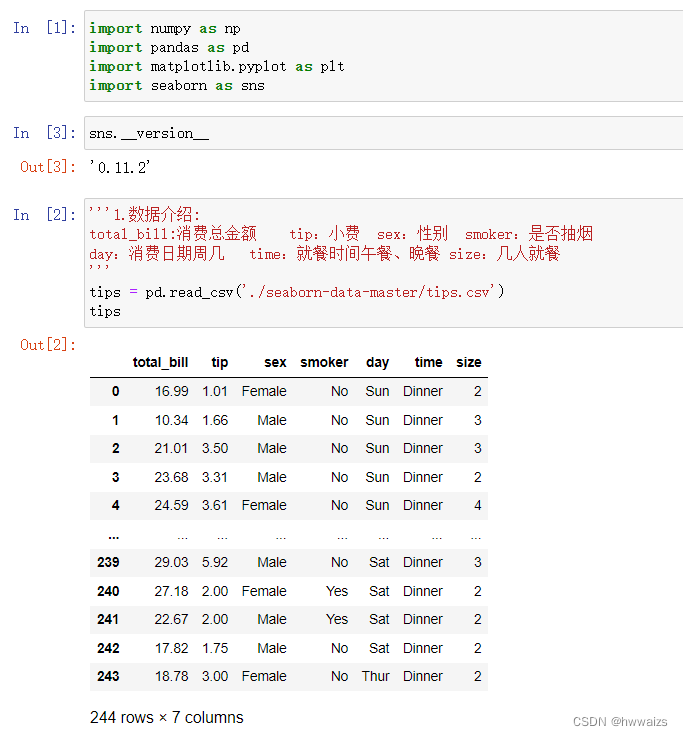
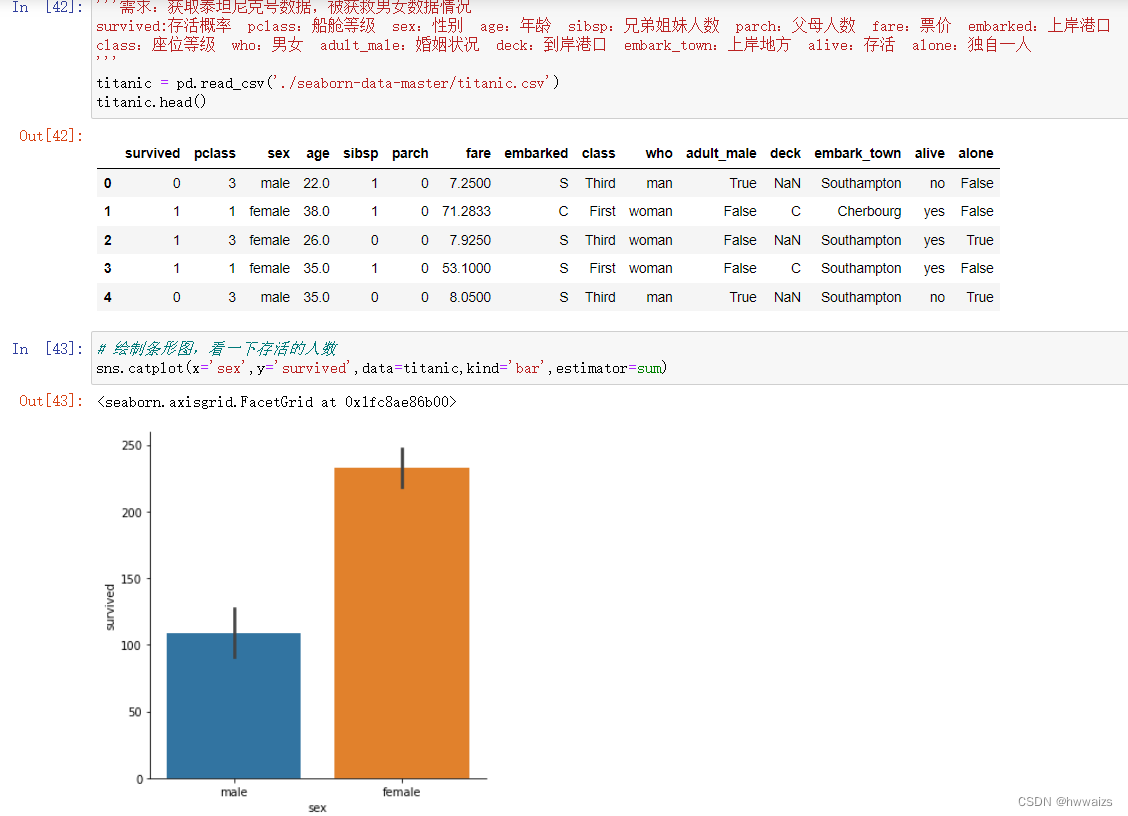
泰坦尼克号数据分析,survived:存活概率 pclass:船舱等级 sex:性别 age:年龄 sibsp:兄弟姐妹人数 parch:父母人数 fare:票价 embarked:上岸港口 class:座位等级 who:男女 adult_male:婚姻状况 deck:到岸港口 embark_town:上岸地方 alive:存活 alone:独自一人
分析被获救男女数据情况,与舱位之间的关系
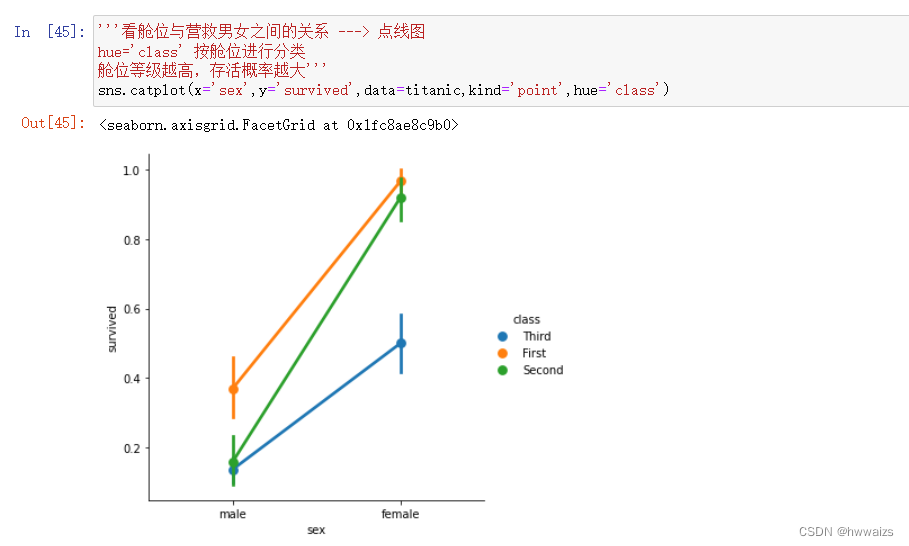
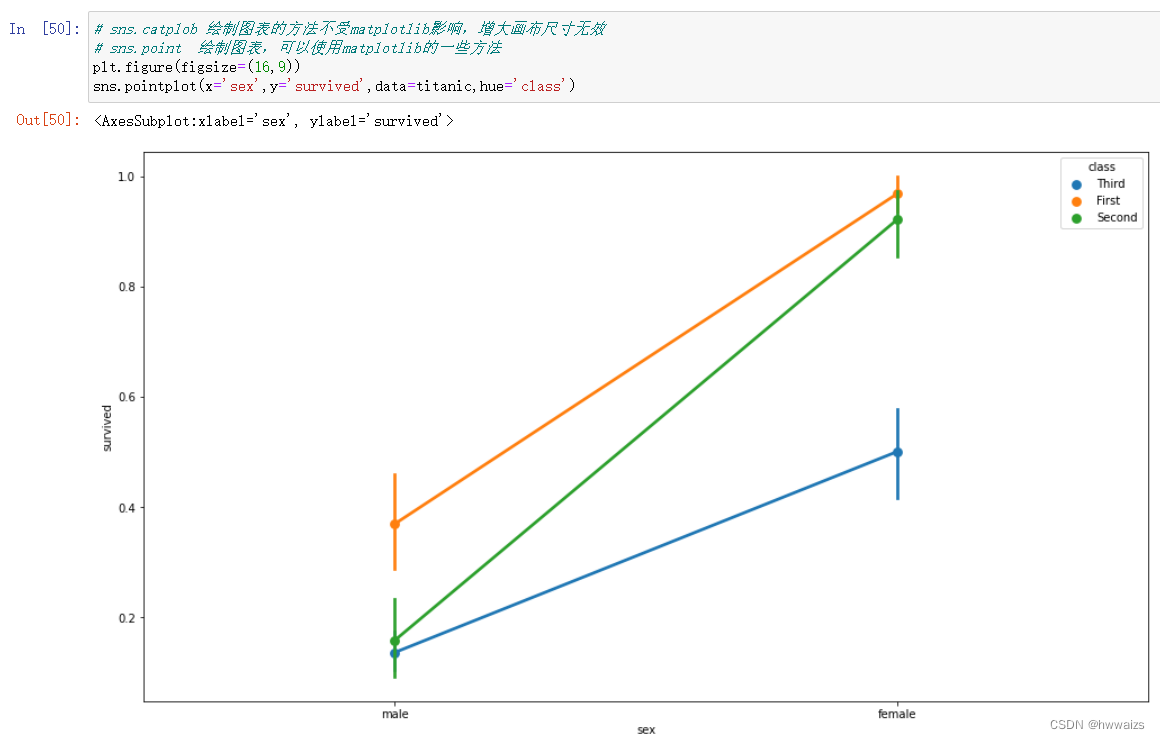
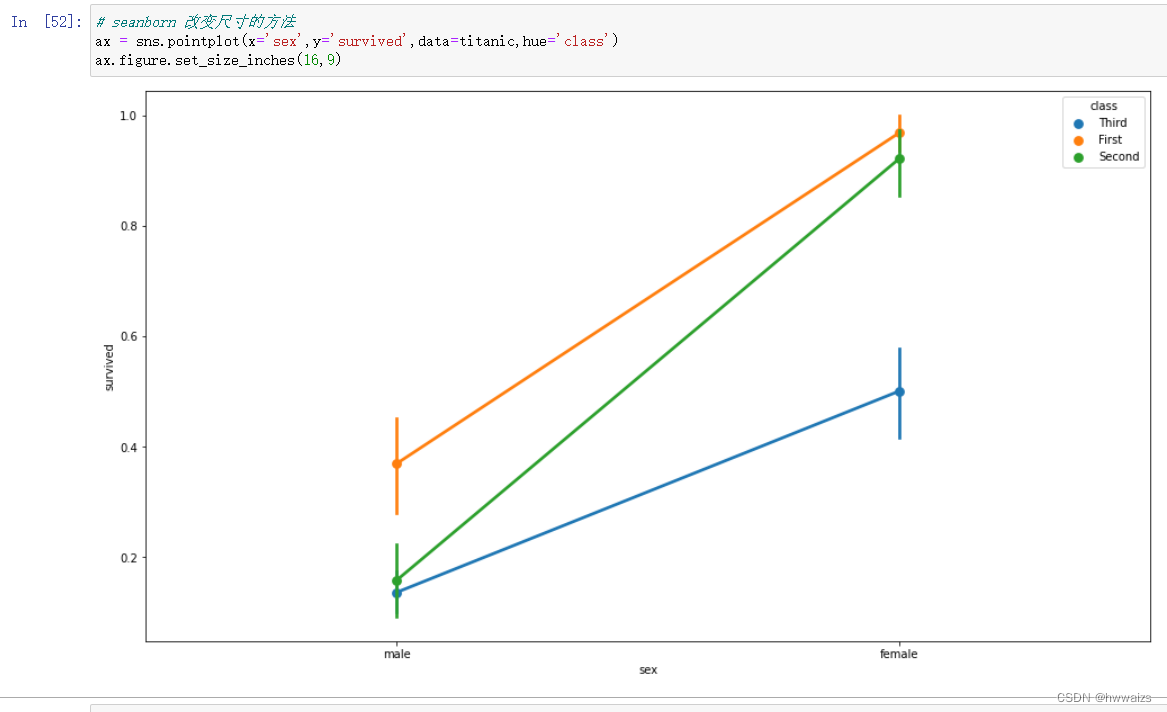
seanborn 通过调用figure.set_size_inches的方法,改变尺寸
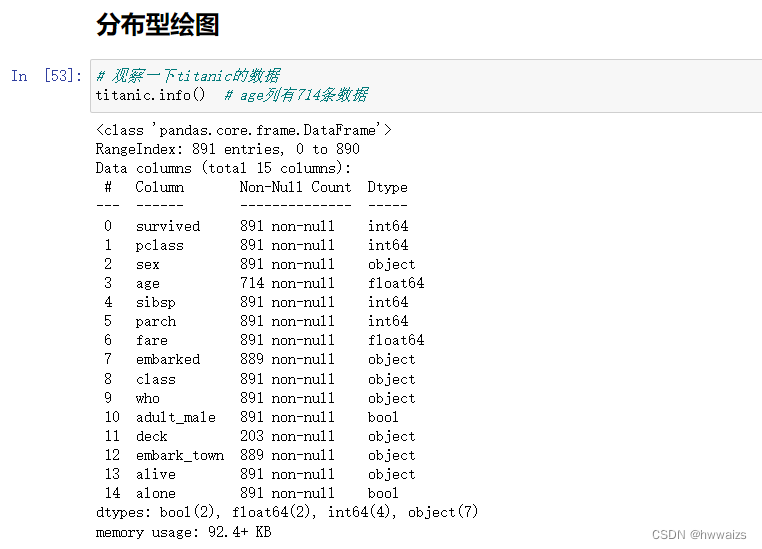
数据集分布可视化
分布型绘图
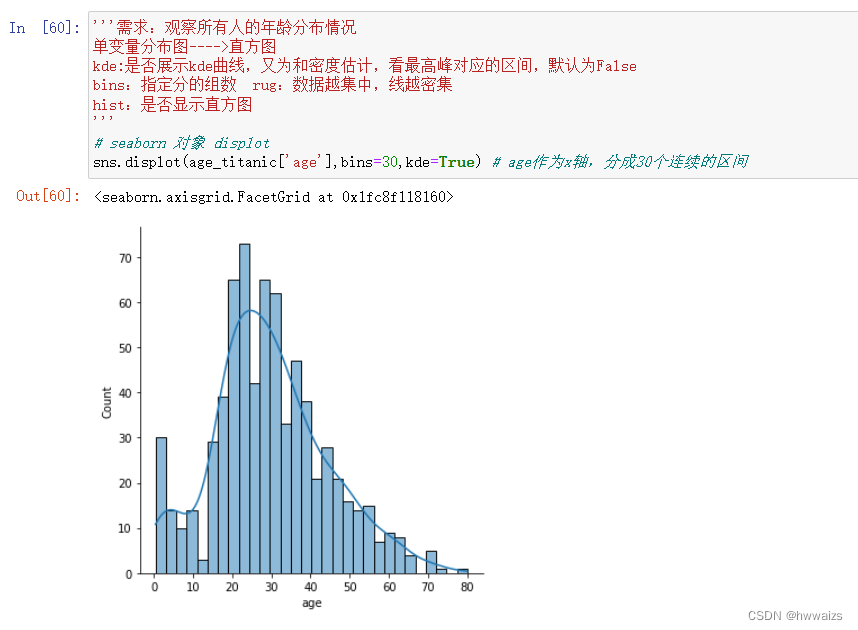
通过titanic的数据来分析所有人年龄分布情况。

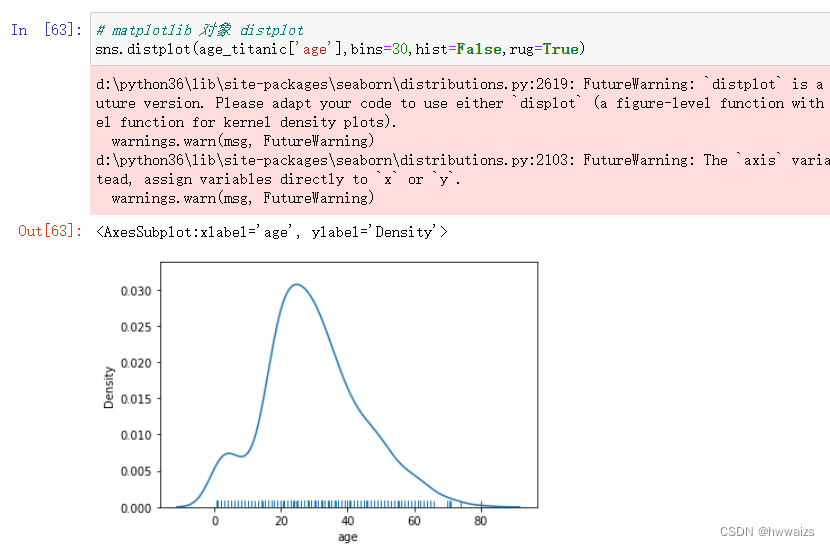
kde:是否展示kde曲线,又为和密度估计,看最高峰对应的区间,默认为False bins:指定分的组数 rug:数据越集中,线越密集
hist:是否显示直方图
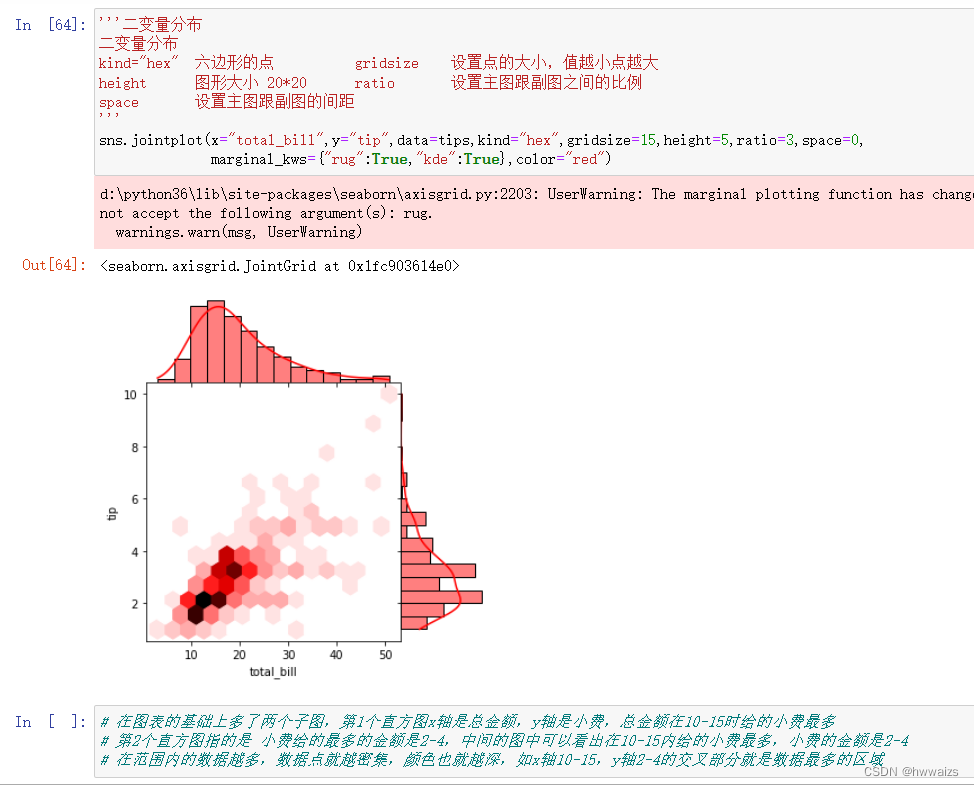
二变量分布
kind=“hex” 六边形的点 gridsize 设置点的大小,值越小点越大
height 图形大小 20*20 ratio 设置主图跟副图之间的比例
space 设置主图跟副图的间距
在图表的基础上多了两个子图,第1个直方图x轴是总金额,y轴是小费,总金额在10-15时给的小费最多。
第2个直方图指的是 小费给的最多的金额是2-4,中间的图中可以看出在10-15内给的小费最多,小费的金额是2-4。
在范围内的数据越多,数据点就越密集,颜色也就越深,如x轴10-15,y轴2-4的交叉部分就是数据最多的区域
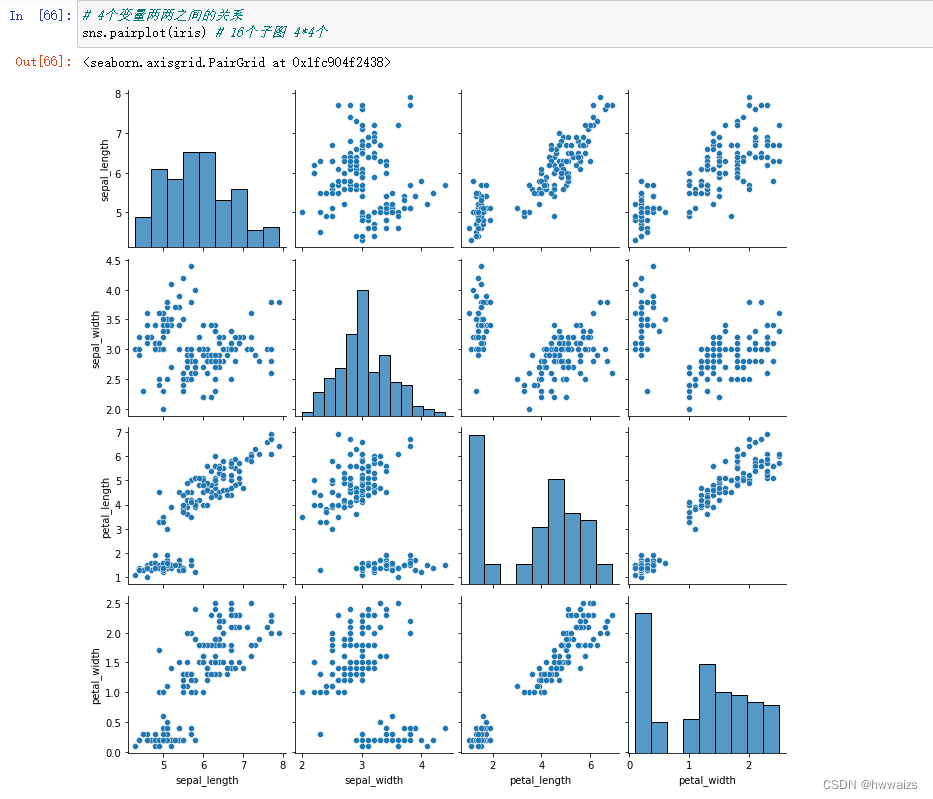
观察4个变量间两两之间的关系
sepal_length:花萼长度 sepal_width:花萼宽度 petal_length: 花瓣长度 petal_width:花瓣宽度 species:花的类别
前4个变量会影响到最后1个变量
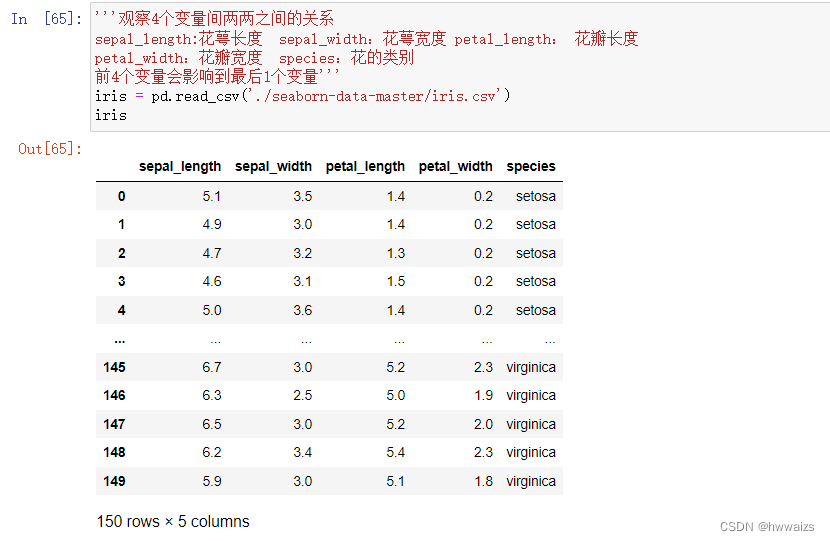
4个变量两两之间的关系
绘图时按花的种类分布
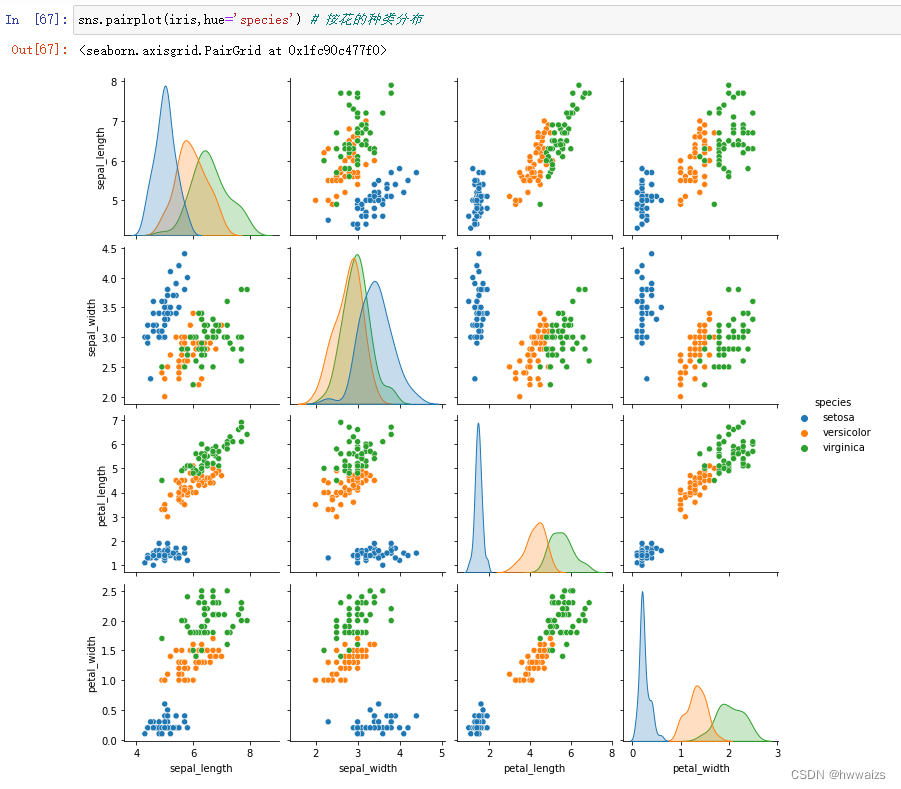
4个直方图是 自己跟自己的关系,4个变量两两之间的关系 看另外12个散点图就可以。
从第1行的另外三个散点图可以看出,数据密集的是一种花,代表花瓣的长度和宽度会影响到一种花。
比如花瓣长度在1-10范围内,就可以确定一种花的类型。
关系矩阵图
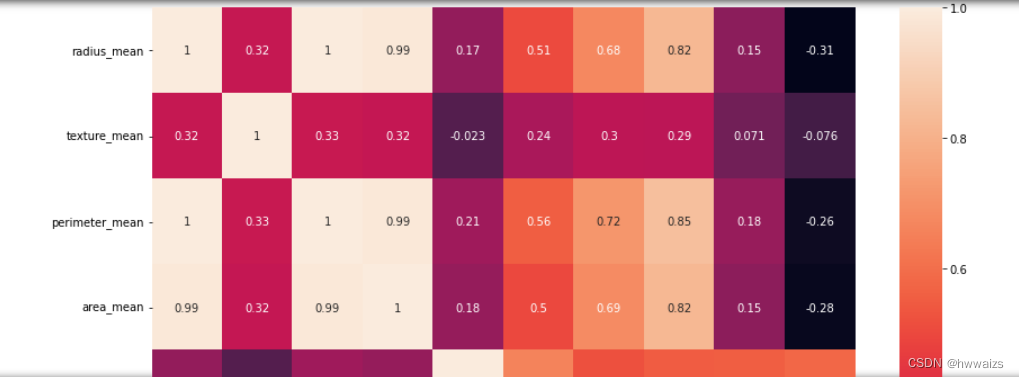
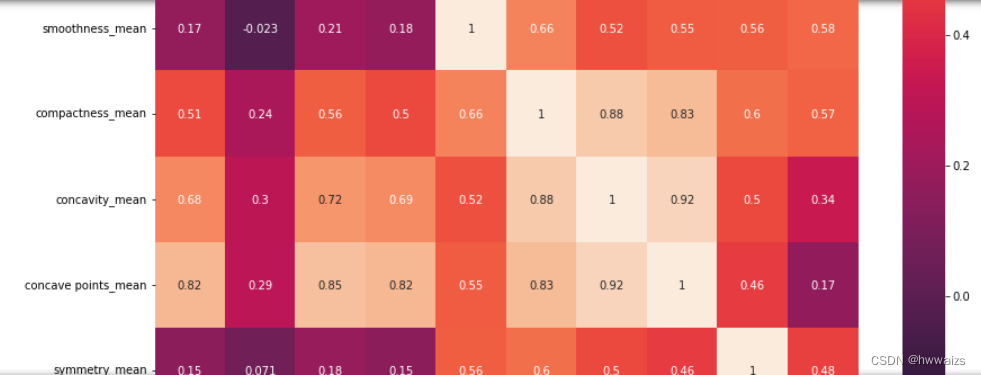
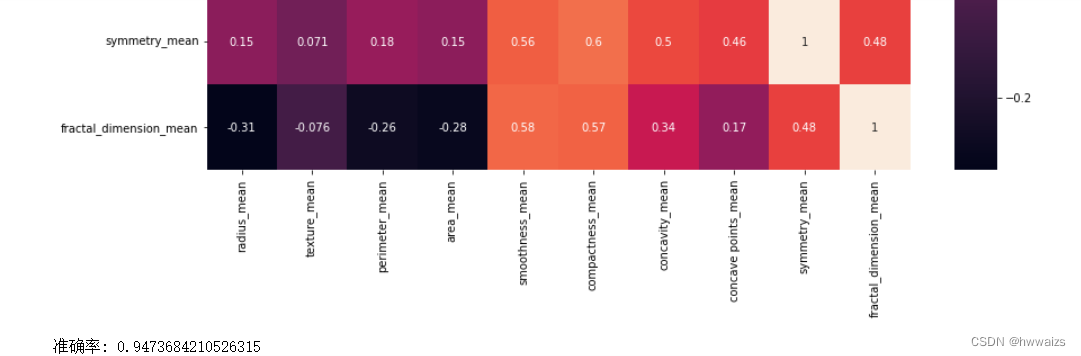
这是肿瘤的数据,有3组数据,2-12列是10个特征值的平均值,12-22列是10个特征值的标准差,22-32列是10个特征值的最大值,特征值有平均半径、平均面积纹理、平均周长等,10个特征之间绘制关系型图表,可以对10个特征进行降维,分析特征值之间的关系,减少特征值数量,便于分析。用pandas中的corr(),字段和字段之间的相关性函数,选择这些特征,求他们的相关性,用热力图来绘制图表,图表是矩阵包含一个一个的小方格,第一行的小方格,第一个是x轴的radius_mean和y轴的radius_mean是一样的,自己和自己的相关性就是1;radius_mean和texture_mean的关系是0.32,说明相关性不是很大;如果有10个特征,其中有3列分别是半径、周长、面积,在做机器学习,进行分析的时候要把多的特征变少,减少模型预测的干扰,根据半径可以求出周长和面积,周长和面积之间有相关的联系的,去除掉相关性比较强的特征,保留1个半径就可以了,特征数量就会减少2个。在图中radius_mean和smoothness_mean的关系是1,radius_mean和compactness_mean的关系是0.99,所以可以只保留1个特征值;从图中可以看出compactness_mean、concavity_mean、concave point_mean 之间的关系分别是0.88,0.3,0.92,说明它们三者的相关性也是一样的,可以去除2个,只保留1个特征,这就是关系型矩阵图的特征,为了特征工程做特征降维提供便利。
做相关性热力图的作用,找到并去除相关性比较强的特征,保留相关性不强的特征,一般高于0.8的都是相关性比较强的,10个特征减少到只剩下6个,便于后期分析及模型的建立。