原文链接
本文发表于自然语言处理领域顶级会议 ACL 2018
摘要
本文提出了一种提取深层次语义特征的词向量的方法,该方法是通过一个在大规模语料库上预训练得到的模型来提取词向量的。通过本文方法提取到的词向量效果十分好,可用于多种类型的NLP任务。本文把这种新的词向量表示方法称为EMLo
模型
本文采用了一种名为biLM的模型,该模型是一种“双向”的模型,什么叫做“双向”呢?
假设我们有一个包含N个单词的句子,我们可以把它表示为:
,那么我们要从“前向”的角度来计算这个句子的概率的话,我们可以通过每个词语“之前的”词语来对其进行建模,具体而言如下公式所示:
依次类推,如果我们要从“后向”的角度来计算的话,公式可以写为:
而本文采用的“双向”模型,是兼顾前向和后向的概率的,用公式表示为:
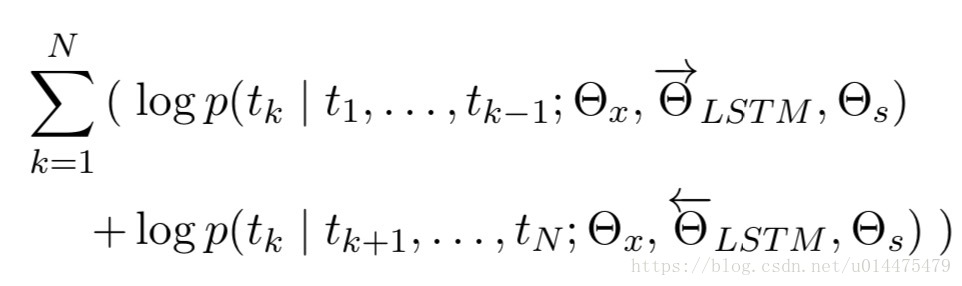
本文提出的EMLo,就是将原始输入进行embedding之后再送入上述模型,用上述模型的“每一层”输出来作为词向量的表示(注意不仅仅是最终输出),公式可以表示为:
其中 是输入的embedding表示, (双向LSTM的每一层输出的两个方向输出的concat), 为LSTM的层号。
得到上述表示之后,我们还不能把它直接作为应对各种NLP任务的词向量,我们要因地制宜地对其进行一些微调,公式如下:
其中 和 分别起着控制缩放与权值的作用, 它们的取值需要根据具体任务来进行调整。
文中推荐了一种EMLo的使用方式,即:直接在 biLM 的基础之上连接自己的神经网络,并且将 biLM 的参数固定 (根据实际情况, 如果只是轻微的 fine-tune 应该也没问题),将biLM的输出当作自己网络的输入,根据任务的不同,可以调整为 或 。
总结
1.文中指出一点: biLM 不同层的激活值可能会有不同的分布, 可采用 Layer Normlaition. (这在 Attention is All You Need 和 Distance Self-Attention Network 中都使用过)
2.有一点很惊艳的是, ELMo 能相当大程度地提高训练效率: 在其中一项实验中, 不使用 ELMo 的模型在 486 个 epochs 后取得达到最大 F1 值; 使用 ELMo 只用了 10 个 epochs。
3.由于 ELMo 的词向量是不同层状态向量的函数, 对 attention-based model, 相当于后续层可以接触到 biLM 的内部表示; 综合了不同层的表示, ELMo 的词向量还具有消除歧义的作用。