1 Word2Vec,Glove & Fastext
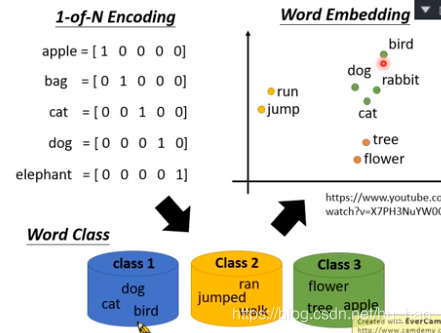
回顾之前内容,对于词如何转为数学表示,最基础的是词的编码,即one-hot编码,这样可以将词转为计算机可以处理的对象,但缺点是完全丢失了词本身的语意信息,只达到了区分效果,每个词之间互不相关。
作为改进,有了词嵌入算法,该算法可以看做词分类技术,将具有类似含义的词嵌入到相似的数学空间,这时词为一个一个向量,相似的词之间的余弦距离更小。代表的算法有基于预测模型的word2vec,Glove。
但对于这类算法,有两个特点,首先对于一个type,只有一个embedding,无法表示多个token。第二是无法解决OOV问题。
- 修仙者:可以讲得更通俗易懂一点么?
- NPC:好的(就等你这么问了,哈哈)
简单来说,就是对于拼写相同的词,该类算法只会产生一个向量,这样就无法表示不同的token(含义),也就是难以解决一词多义的问题。所以这类词嵌入算法,也叫做静态词嵌入。第二个就是无法解决没有出现在词库内词的识别问题。
对于第二个问题,研究者认为是嵌入的词粒度太大(词水平词嵌入),因此希望将词向量更细粒度分解,这样就产生了字符级词嵌入模型,子词模型,Fastext就是在word2vec上加入子词模型的混合模型。
那么一词多义要如何解决呢,这就产生了ELMO,BERT等模型
2 一词多义
对于一个单词,基于不同上下文,会产生不同的embedding,这就是大多数一词多义模型的原理。
如下图,mouse如果上下文出现computer,click等词,那么其应该为鼠标的意思,应该单独为一个embedding,如果出现moving,loving等词,那么大概率表示老鼠,需要单独生成一个embedding。这样,基于不同上下文动态生成embedding的方法,就可以解决一词多义问题。
目前有三种主流算法,ELMO,BERT和GPT。

2.1 ELMO
ELMO有两个部分,基于前文生成后一个单词(左边),基于后文,生成前一个词(右边)。这是基于语言模型的词嵌入方法。
- 修仙者貌似有话想说,但还是把话咽了回去。
- NPC:我知道你想问,什么是语言模型?其实就是基于前文,预测下一个词的算法,比于给出:锄禾日当,那么该算法会预测下一个词为:午。
- 修仙者:额,其实我想说,芝麻街里全身红毛的玩偶,也叫ELMO。
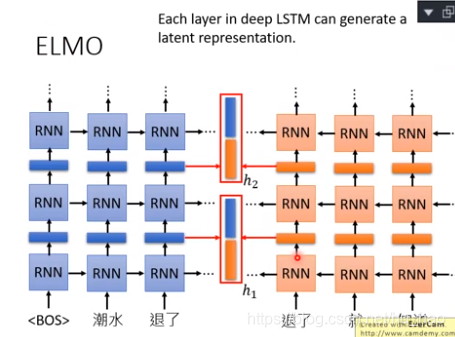
得到两个词向量,用哪一个呢?ELMO说,我全都要!

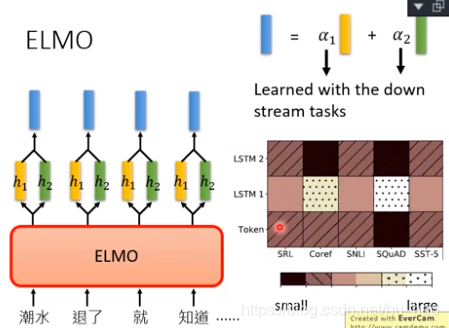
于是对于多个词向量,ELMO采取了加权和,而具体系数,需要在下游任务,也就是实际任务中学习得到。
以下是不同任务中,两个词向量的比重对比。
2.2 BERT
对于bert,则是利用transformers来代替RNN,更具体的来说,Bert是transformers的Encoder部分,而GPT是Decoder部分。
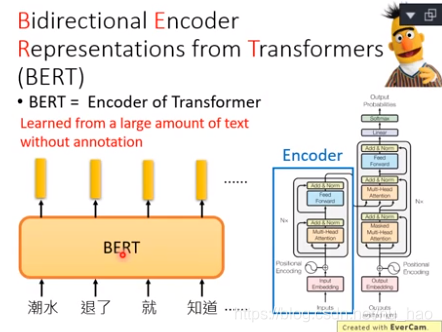
- NPC:正如你所看到,Bert也是芝麻街中角色的名字。
- 修仙者:我就知道这不是巧合!
2.3 GPT
GPT是OPEN AI开发的模型,因其体量巨大而出名,是的,就是字面那个意思。特别是GPT-2,有1542M,我很担心94M的ELMO会被它一脚踩死。
- ELMO:大有大的好处,小有小的好处,说这个1542M的GPT-2你也就图一乐,别人不开源,要真正上线,你还得来咱们芝麻街。
- NPC:。。。(扎心了)

如前所说,GPT是transformer的Decoder部分,GPT在没有进行训练的情况下(下游训练),可以完成很多神奇的任务,但鉴于开源程度,实际落地还是以BERT为多。

3 小结
