1、DLG文献解析
文献地址:
Deep Leakage From Gradients.pdf
iDLG Improved Deep Leakage from Gradients.pdf
1.1 背景介绍
现在分布式机器学习和联邦学习中普遍接受的一个做法是将数据梯度进行共享,多方数据通过共享的梯度信息进行联合建模,即在原始数据不出库的前提下进行建模。
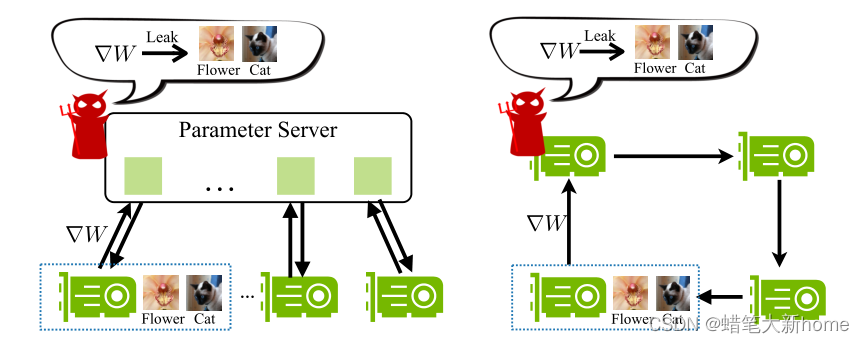
这样的梯度信息是否是安全的呢?我们知道,梯度与标签和样本特征有关,那么意味着梯度其中包含着部分的标签信息和原始信息,所以联邦学习中的梯度信息是非常不安全的数据:
1、在集中式分布式训练中,一般不存储任何训练数据的参数服务器也能够窃取所有参与者的本地训练数据。
2、对于分散的分布式训练,情况变得更糟,因为任何参与者都可以窃取其邻居的私人训练数据。
作者做了这样一个工作:通过神经网络中的梯度信息去反推原始数据和标签。
1.2 算法描述
1、从梯度中逐个像素地窃取图像和逐个单词地窃取句子是可能的。我们关注标准的同步分布式训练:在每个步骤t,每个节点I从其自己的数据集中采样一个小批(xt,I,yt,I)来计算梯度:
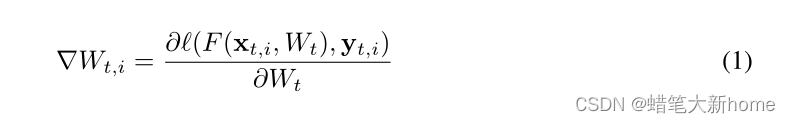
2、梯度在N个服务器上求平均值,然后再更新权重:
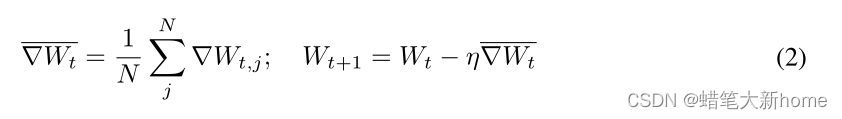
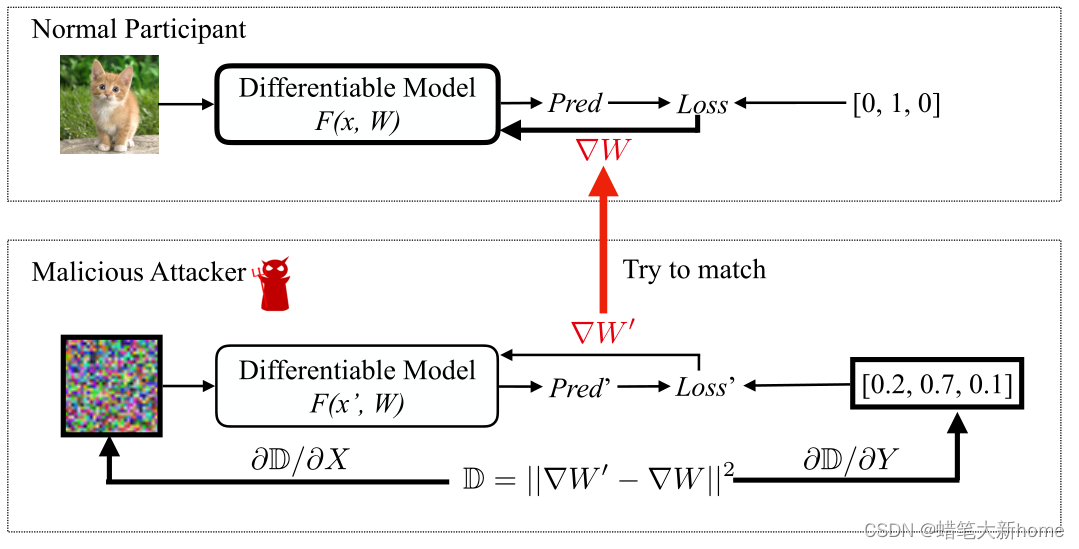
3、当正常参与者使用其私有训练数据计算∇W以更新参数时,恶意攻击者更新其伪输入和标签以最小化梯度距离。当优化完成时,恶意用户能够从真实参与者那里窃取训练数据。
这里拿一张小猫图片进行示例,对于输入样本可以通过训练过的网络得到预测值和梯度。而在攻击模型中,将随机输入我们的输入x和标签向量,将模型迁移过来。然后我们将计算我们的梯度与原模型梯度大差值,通过反推更新输入样本和标签信息,以此进行迭代。
4、给定目标函数,我们通过最小化以下目标来获得训练数据
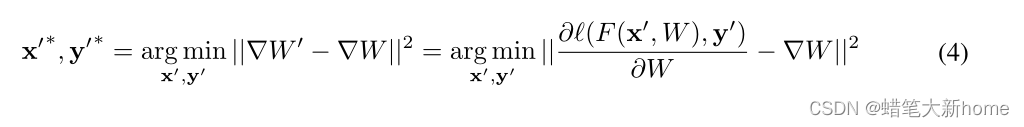
5、算法

1.3 实验结果
1、文献实验结果
分别在MNIST、CIFAR-100 SVHN和LFW的图像上显示深层渗漏的可视化图像。我们的算法完全恢复了四幅图像,而以前的工作只在具有干净背景的简单图像上成功。

2、复现结果
测试了MNIST和CIFAR100数据集,基本上可以恢复初始图像,但也存在恢复失败的例子。

2、iDLG文献解析
IDLG(Improved Deep Leakage from Gradients)是在DLG方法的基础上进行改进。我们发现共享梯度肯定会泄露ground-truth的标签。我们提出了一种简单而可靠的方法来从梯度中提取准确的数据。特别是,相对于DLG来说,我们的方法肯定能提取出真实的标签,因此我们将其命名为改进的DLG(iDLG)。
2.1 算法描述
1、对于分类情况,NN(神经网络)模型一般是用one-hot标签的交叉熵损失来训练的,它被定义为:

2、那么,每个输出的损失梯度为
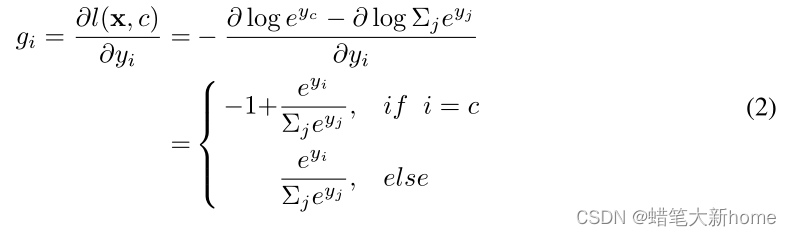
对于概率范围是(0,1),当虚拟标签 i 与真实标签相同时,此时 gi 的值为负值,反之为正值。
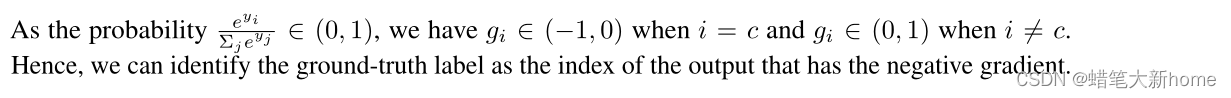
3、然而,我们可能无法获得关于输出 y 的梯度,因为它们不包括在共享梯度 ∇W 中,后者是关于模型W的权重的导数。我们发现梯度向量 ∇W 关于连接到输出层第 i 个 Logit 的权重 W 可以写成:
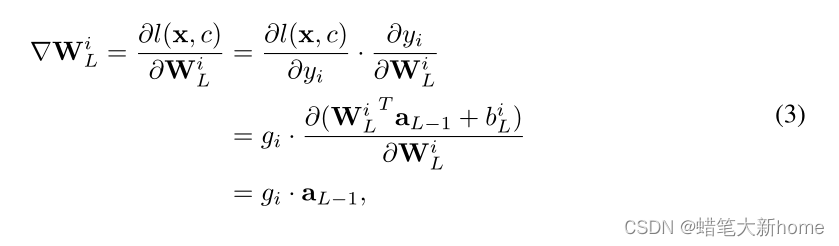
当使用非负的激活函数时,例如ReLU和Sigmoid,∇ W 和 gi 的符号是相同的。因此,我们可以简单地识别出其对应的 ∇W 为负值的ground-truth标签。有了这个规则,我们就很容易从共享梯度∇W中识别出私有训练数据x的ground-truth标签c。
4、算法

2.2 实验结果
1、文献实验结果
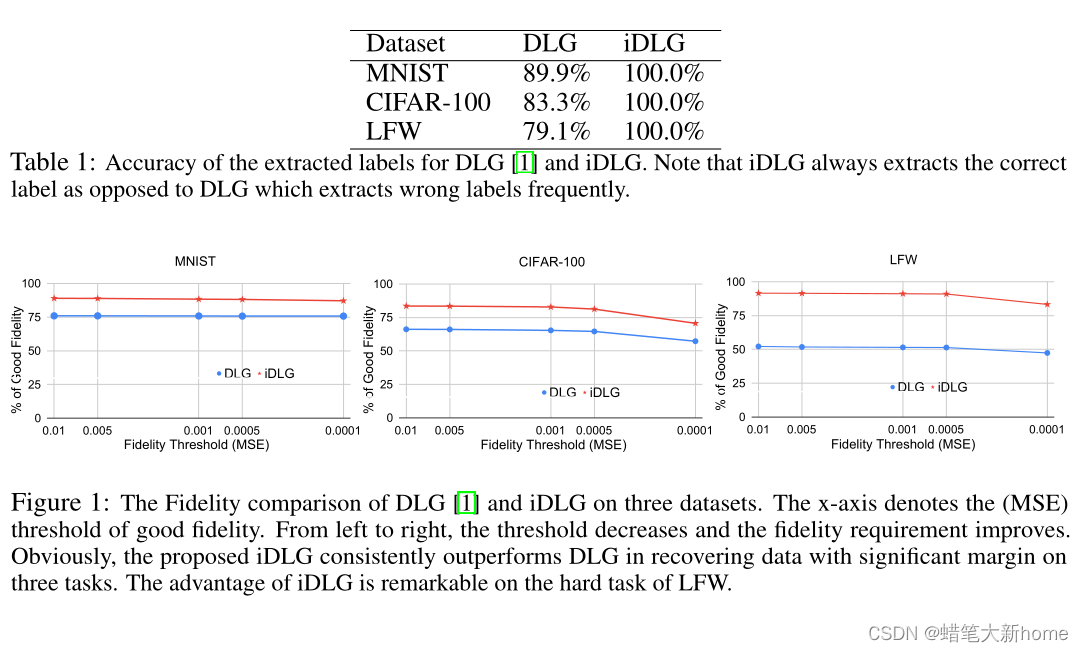
2、实验复现结果
相对于DLG算法,IDLG的恢复效果更快更准确。这主要是因为iDLG对于标签的提取方法比DLG更好,产生的误差更小。

3、代码(DLG和iDLG)
源代码:https://github.com/PatrickZH/Improved-Deep-Leakage-from-Gradients
改进代码含有个人的详细解释,适合初学者阅读。
import time
import os
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import Dataset
from torchvision import datasets, transforms
import pickle
import PIL.Image as Image
class LeNet(nn.Module):
def __init__(self, channel=3, hideen=768, num_classes=10): # hidden是神经网络最后一层全连接层的维度
super(LeNet, self).__init__()
act = nn.Sigmoid
self.body = nn.Sequential(
nn.Conv2d(channel, 12, kernel_size=5, padding=5 // 2, stride=2), # 输入张量大小,输出张量大小,卷积核的大小,填充,步长
act(),
nn.Conv2d(12, 12, kernel_size=5, padding=5 // 2, stride=2),
act(),
nn.Conv2d(12, 12, kernel_size=5, padding=5 // 2, stride=1),
act(),
)
self.fc = nn.Sequential(
nn.Linear(hideen, num_classes) # 全连接层
)
# 前向传播
def forward(self, x):
out = self.body(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def weights_init(m):
try:
# hasattr()函数 用于判断对象是否包含对应的属性。
if hasattr(m, "weight"):
# 使用均匀分布U(a,b)初始化Tensor,即Tensor的填充值是等概率的范围为 [a,b) 的值。均值为 (a + b)/ 2.
m.weight.data.uniform_(-0.5, 0.5)
except Exception:
print('warning: failed in weights_init for %s.weight' % m._get_name())
try:
if hasattr(m, "bias"):
m.bias.data.uniform_(-0.5, 0.5)
except Exception:
print('warning: failed in weights_init for %s.bias' % m._get_name())
class Dataset_from_Image(Dataset):
def __init__(self, imgs, labs, transform=None):
self.imgs = imgs # img paths
self.labs = labs # labs is ndarray
self.transform = transform
del imgs, labs
def __len__(self):
return self.labs.shape[0]
def __getitem__(self, idx):
lab = self.labs[idx]
img = Image.open(self.imgs[idx])
if img.mode != 'RGB':
img = img.convert('RGB')
img = self.transform(img)
return img, lab
def lfw_dataset(lfw_path, shape_img):
images_all = []
labels_all = []
folders = os.listdir(lfw_path)
for foldidx, fold in enumerate(folders):
files = os.listdir(os.path.join(lfw_path, fold))
for f in files:
if len(f) > 4 and f[-4:] == '.jpg':
images_all.append(os.path.join(lfw_path, fold, f))
labels_all.append(foldidx)
transform = transforms.Compose([transforms.Resize(size=shape_img)])
dst = Dataset_from_Image(images_all, np.asarray(labels_all, dtype=int), transform=transform)
return dst
def main():
dataset = 'MNIST'
root_path = '.'
data_path = os.path.join(root_path, './data/MNIST').replace('\\', '/')
save_path = os.path.join(root_path, './results/iDLG_%s'%dataset).replace('\\', '/')
lr = 1.0
num_dummy = 1
Iteration = 300
num_exp = 1000
use_cuda = torch.cuda.is_available()
device = 'cuda' if use_cuda else 'cpu'
tt = transforms.Compose([transforms.ToTensor()])
tp = transforms.Compose([transforms.ToPILImage()])
print(dataset, 'root_path:', root_path)
print(dataset, 'data_path:', data_path)
print(dataset, 'save_path:', save_path)
if not os.path.exists('results'):
os.mkdir('results')
if not os.path.exists(save_path):
os.mkdir(save_path)
''' load data '''
if dataset == 'MNIST':
shape_img = (28, 28)
num_classes = 10
channel = 1
hidden = 588
dst = datasets.MNIST(data_path, download=True)
elif dataset == 'cifar100':
shape_img = (32, 32)
num_classes = 100
channel = 3
hidden = 768
dst = datasets.CIFAR100(data_path, download=True)
elif dataset == 'lfw':
shape_img = (32, 32)
num_classes = 5749
channel = 3
hidden = 768
lfw_path = os.path.join(root_path, './data/lfw')
dst = lfw_dataset(lfw_path, shape_img)
# dst = lfw_dataset(data_path, shape_img)
else:
exit('unknown dataset')
''' train DLG and iDLG '''
for idx_net in range(num_exp):
net = LeNet(channel=channel, hideen=hidden, num_classes=num_classes)
net.apply(weights_init)
print('running %d|%d experiment'%(idx_net, num_exp))
net = net.to(device)
idx_shuffle = np.random.permutation(len(dst))
for method in ['DLG', 'iDLG']:
print('%s, Try to generate %d images' % (method, num_dummy))
criterion = nn.CrossEntropyLoss().to(device) # 计算交叉熵损失函数
imidx_list = []
for imidx in range(num_dummy):
idx = idx_shuffle[imidx]
imidx_list.append(idx)
tmp_datum = tt(dst[idx][0]).float().to(device)
tmp_datum = tmp_datum.view(1, *tmp_datum.size())
tmp_label = torch.Tensor([dst[idx][1]]).long().to(device)
tmp_label = tmp_label.view(1, )
if imidx == 0:
gt_data = tmp_datum
gt_label = tmp_label
else:
gt_data = torch.cat((gt_data, tmp_datum), dim=0) # tensor拼接
gt_label = torch.cat((gt_label, tmp_label), dim=0)
# compute original gradient
out = net(gt_data)
y = criterion(out, gt_label) # 计算loss
dy_dx = torch.autograd.grad(y, net.parameters()) # 通过自动求微分得到真实梯度
# 这一步是一个列表推导式,先从dy_dx这个Tensor中一步一步取元素出来,对原有的tensor进行克隆, 放在一个list中
# https://blog.csdn.net/Answer3664/article/details/104417013
original_dy_dx = list((_.detach().clone() for _ in dy_dx))
# generate dummy data and label
dummy_data = torch.randn(gt_data.size()).to(device).requires_grad_(True) # 初始化虚拟参数
dummy_label = torch.randn((gt_data.shape[0], num_classes)).to(device).requires_grad_(True)
if method == 'DLG':
# LBFGS具有收敛速度快、内存开销少等优点???
optimizer = torch.optim.LBFGS([dummy_data, dummy_label], lr=lr) # 设置优化器为拟牛顿法
elif method == 'iDLG':
optimizer = torch.optim.LBFGS([dummy_data, ], lr=lr)
# predict the ground-truth label
label_pred = torch.argmin(torch.sum(original_dy_dx[-2], dim=-1), dim=-1).detach().reshape((1,)).requires_grad_(False)
history = []
history_iters = []
losses = []
mses = []
train_iters = []
print('lr =', lr)
for iters in range(Iteration):
def closure():
# 清空过往梯度
optimizer.zero_grad()
pred = net(dummy_data)
if method == 'DLG':
# 将假的预测进行softmax归一化,转换为概率
dummy_loss = - torch.mean(torch.sum(torch.softmax(dummy_label, -1) * torch.log(torch.softmax(pred, -1)), dim=-1))
# dummy_loss = criterion(pred, gt_label)
elif method == 'iDLG':
dummy_loss = criterion(pred, label_pred)
dummy_dy_dx = torch.autograd.grad(dummy_loss, net.parameters(), create_graph=True)
grad_diff = 0
for gx, gy in zip(dummy_dy_dx, original_dy_dx):
grad_diff += ((gx - gy) ** 2).sum()
grad_diff.backward()
return grad_diff
optimizer.step(closure)
current_loss = closure().item()
train_iters.append(iters)
losses.append(current_loss)
mses.append(torch.mean((dummy_data-gt_data)**2).item())
if iters % int(Iteration / 30) == 0:
current_time = str(time.strftime("[%Y-%m-%d %H:%M:%S]", time.localtime()))
print(current_time, iters, 'loss = %.8f, mse = %.8f' %(current_loss, mses[-1]))
history.append([tp(dummy_data[imidx].cpu()) for imidx in range(num_dummy)])
history_iters.append(iters)
for imidx in range(num_dummy):
plt.figure(figsize=(12, 8))
plt.subplot(3, 10, 1)
# plt.imshow(tp(gt_data[imidx].cpu()))
# 得到灰度图像
plt.imshow(tp(gt_data[imidx].cpu()), cmap='gray')
plt.title('Truth image')
for i in range(min(len(history), 29)):
plt.subplot(3, 10, i + 2)
plt.imshow(history[i][imidx], cmap='gray') # 这一行是显示灰度图片的意思, 如果不是mnist数据集,将这一行改为如下
# plt.imshow(history[i][imidx])
plt.title('iter=%d' % (history_iters[i]))
plt.axis('off')
if method == 'DLG':
plt.savefig('%s/DLG_on_%s_%05d.png' % (save_path, imidx_list, imidx_list[imidx]))
plt.close()
elif method == 'iDLG':
plt.savefig('%s/iDLG_on_%s_%05d.png' % (save_path, imidx_list, imidx_list[imidx]))
plt.close()
if current_loss < 0.000001: # 收敛阈值
break
if method == 'DLG':
loss_DLG = losses
label_DLG = torch.argmax(dummy_label, dim=-1).detach().item()
mse_DLG = mses
elif method == 'iDLG':
loss_iDLG = losses
label_iDLG = label_pred.item()
mse_iDLG = mses
print('imidx_list:', imidx_list)
print('loss_DLG:', loss_DLG[-1], 'loss_iDLG:', loss_iDLG[-1])
print('mse_DLG:', mse_DLG[-1], 'mse_iDLG:', mse_iDLG[-1])
print('gt_label:', gt_label.detach().cpu().data.numpy(), 'lab_DLG:', label_DLG, 'lab_iDLG:', label_iDLG)
print('----------------------\n\n')
if __name__ == '__main__':
main()