Residual Attention Network for Image Classification
2017CVPR
Motivation
Attention模型在图像分割和图像显著性检测方面的应用比较多。它的出发点是将注意力集中在部分显著或者是感兴趣的点上。其实卷积网络本身就自带Attention效果,以分类网络为例,高层feature map所激活的pixel也恰好就是滤波得出有较大的反应的区域,即为在分类任务相关的区域。
本文的思想也就是利用这种attention机制,在普通的ResNet网络中,增加侧分支,侧分支通过一系列的卷积和池化操作,逐渐提取高层特征并增大模型的感受野,前面已经说过高层特征的激活对应位置能够反映attention的区域,然后再对这种具有attention特征的feature map进行上采样,使其大小回到原始feature map的大小,就将attention对应到原始图片的每一个位置上,这个feature map叫做 attention map,与原来的feature map 进行element-wise product的操作,相当于一个权重器,增强有意义的特征,抑制无意义的信息。
Contributions
- 提出一种可堆叠的
Residual Attention Module模块,可以通过模块的堆叠使得网络达到比较深的层次。 - 提出一种基于
Attention的残差学习方式,因为直接进行Attention Module的堆叠使得性能下降。使得非常深的模型能够容易的优化和学习,并且具有非常好的性能。 - 一种
Bottom-up top-down的前向传播Attention机制,即先降采样再上采样。其他利用Attention的网络,往往需要在原有网络的基础上新增一个分支来提取Attention,并进行单独的训练,而本文提出的模型能够就在一个前向过程中就提取模型的Attention,使得模型训练更加简单。
从上面前两点依然发现本文所提出的方法和ResNet没多大的区别,但是把1、2、3点融合起来,就成了本文的一个亮点
网络结构
整体网络结构
结构的主体仍然是基于Residual Unit的ResNet网络结构,论文中的结构图
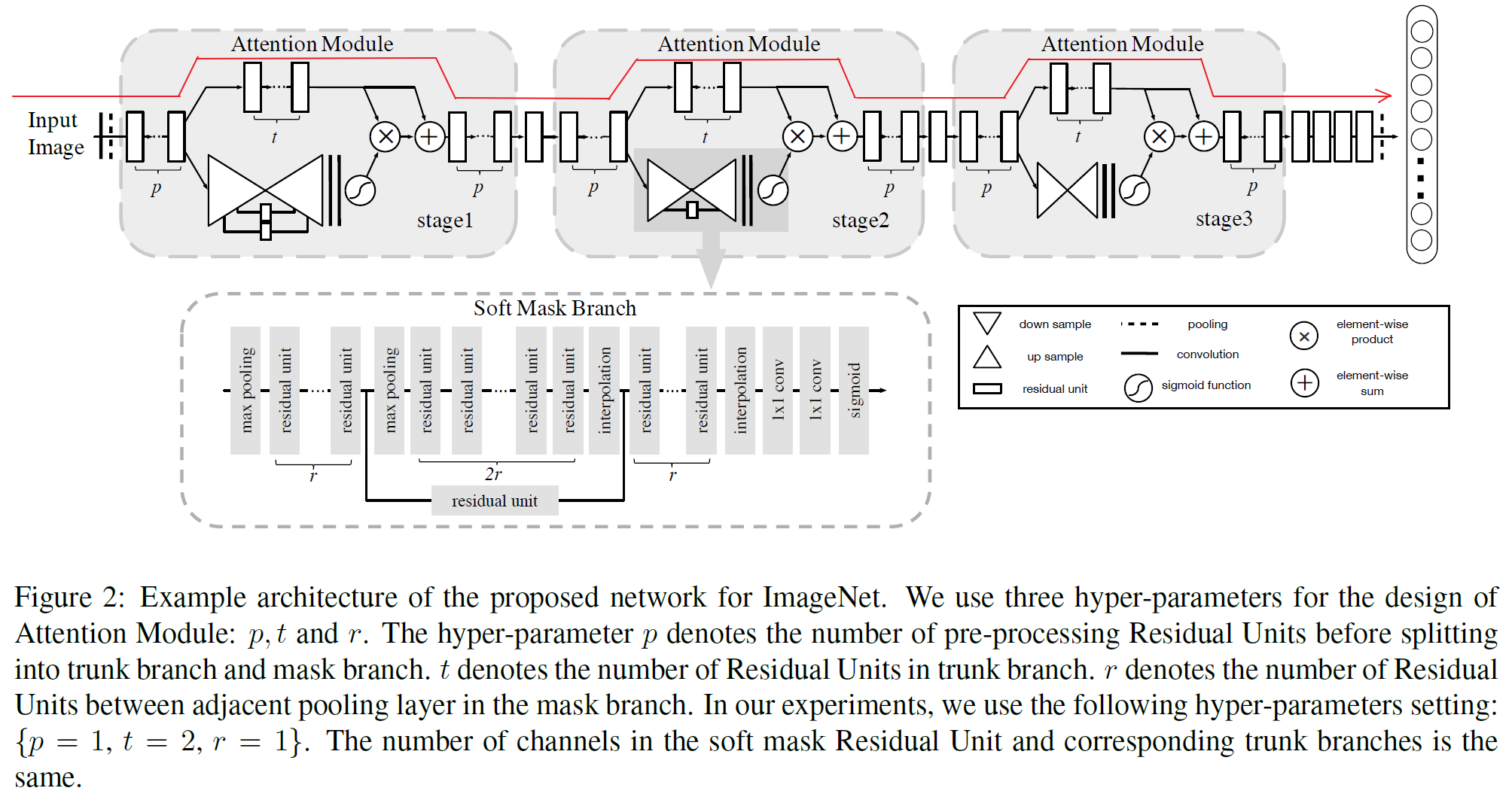
如果只看最上面红色箭头标记的流程,就是一个普通的残差网络,然后在残差块的部分位置,加入另外的分支,构成一个整体的Attention Modle,下面对Attention Module做具体分析。
这里利用Residual Attention Module进行堆叠得到的模型结构,三个stage,由浅到深提取不同层次的Attention信息,值得注意的是,网络中的每一个unit都可以换成目前具有非常好性能的结构,如Residual Block、Inception Block,换个角度说,就是可以将这个Attention的结构无缝连接到目前最优秀的网络中去,使得模型的性能更上一层楼。

Attention Module
两个分支:主干分支(Trunk Branch),Mask分支(Mask Branch)

上图基本上可以囊括本文的绝大部分内容,对于某一层的输出feature map,也就是下一层的输入,对于一个普通的卷积网络,只有右半部分称为主干分支,也就是Trunk Branch,此时下面的网络结构的输入就是,本结构输入feature map的单纯卷积输出,和正常级联网络结构没有区别。
作者在这个基础上增加了左半部分:Soft Mask Branch——一个Bottom-up Top-down的结构。
这样一个Attention Module分为两个分支,右边的分支就是普通的卷积网络,即主干分支,叫做Trunk Branch。左边的分支是为了得到一个掩码mask,该掩码的作用是得到输入特征 x x x的attention map,所以叫做Mask Branch,这个Mask Branch包含down sample和up sample的过程,最终目的是为了保证和右边分支的输出大小一致。
Bottom-up Top-down结构
Bottom-up Top-down的结构首先通过一系列的卷积和pooling,逐渐提取高层特征并增大模型的感受野,之前说过高层特征中所激活的Pixel能够反映Attention所在的区域,于是再通过相同数量的up sample将feature map的尺寸放大到与原始输入一样大(这里的upsample通过deconvolution来实现,可以利用bilinear interpolation 也可以利用deconvolution自己来学习参数,可参考FCN中的deconvolution使用方式),这样就将Attention的区域对应到输入的每一个pixel上,我们称之为Attention map。
Bottom-up Top-down这种encoder-decoder的结构在图像分割中用的比较多,如FCN,也正好是利用了这种结构相当于一个weakly-supervised的定位任务的学习。
分支结合
接下来就要把Soft Mask Branch与Trunk Branch的输出结合起来,Soft Mask Branch输出的Attention map中的每一个pixel值相当于对原始feature map上每一个pixel值的权重,它会增强有意义的特征,而抑制无意义的信息,因此,将Soft Mask Branch与Trunk Branch输出的feature map进行element-wised的乘法,就得到了一个weighted Attention map。但是无法直接将这个weighted Attention map输入到下一层中,因为Soft Mask Branch的激活函数是Sigmoid,输出值在(0,1)之间(之所以这么做,我认为是不希望给前后两层的feature map带来太大的差异和扰动,其次能够进一步的抑制不重要的信息,也有可能是因为如果使用别的激活函数可能会出现过大激活值的情况,进行featuremap间对应位置乘法的时候就很容易出现问题),因此通过一系列这样的乘法,将会导致feature map的值越来越小,并且也可能打破原始网络的特性,当层次极深时,给训练带来了很大的困难。因此作者在得到了weighted Attention map之后又与原来Trunk Branch的feature map进行了一个element-wised的操作,这就和ResNet有异曲同工之妙,该层的输出由下面这个式子组成。于是就有了如下的改进。
Attention Residual Learning
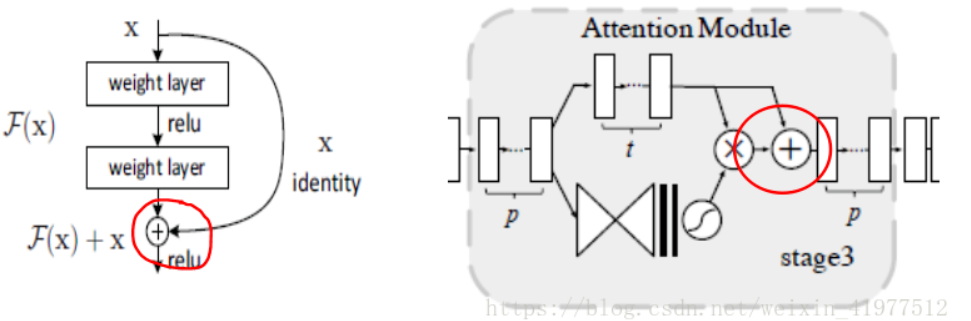
前面已经说了直接进行element-wise product操作会使得性能降低,那么比较好的方式就借鉴ResNet恒等映射的方法:
H i , c ( x ) = ( 1 + M i , c ( x ) ) ∗ F i , c ( x ) H_{i, c}(x)=\left(1+M_{i, c}(x)\right) * F_{i, c}(x) Hi,c(x)=(1+Mi,c(x))∗Fi,c(x)

其中 H ( x ) H(x) H(x)是注意力模块的输出, M ( x ) M(x) M(x)为Soft Mask Branch的输出, F ( x ) F(x) F(x)为Trunk Branch的输出,那么当 M ( x ) = 0 M(x)=0 M(x)=0时,该层的输入就等于 F ( x ) F(x) F(x),因此该层的效果不可能比原始的 F ( x ) F(x) F(x)差,这一点也借鉴了ResNet中恒等映射的思想,同时这样的加法,也使得Trunk Branch输出的feature map中显著的特征更加显著,增加了特征的判别性。
出于网络深度的扩展
在对网络深度进行扩展时,主要存在的问题是,简单的注意力模块堆叠会造成明显的性能下降,原因如下:
1)mask的取值范围为[0,1],在深层网络中重复地进行点积,会消减特征的值。
2)mask潜在地打破了trunk分支的一些特性,比如说残差单元的恒等映射(identical mapping)
解决方案:作者类比残差学习提出了注意力残差学习,仿其提出假设:如果mask单元能被构造成恒等映射,那么它的性能将不会比没有注意力机制的网络差。
关于混合注意力的说明:
f 1 ( x i , c ) = 1 1 + exp ( − x i , c ) f 2 ( x i , c ) = x i , c ∥ x i ∥ f 3 ( x i , c ) = 1 1 + exp ( − ( x i , c − mean c ) / std c ) f_{1}\left(x_{i, c}\right)=\frac{1}{1+\exp \left(-x_{i, c}\right)}\\ f_{2}\left(x_{i, c}\right)=\frac{x_{i, c}}{\left\|x_{i}\right\|}\\ f_{3}\left(x_{i, c}\right)=\frac{1}{1+\exp \left(-\left(x_{i, c}-\operatorname{mean}_{c}\right) / \operatorname{std}_{c}\right)} f1(xi,c)=1+exp(−xi,c)1f2(xi,c)=∥xi∥xi,cf3(xi,c)=1+exp(−(xi,c−meanc)/stdc)1

- f 1 f_{1} f1是对图片特征张量直接sigmoid激活函数,就是混合域的注意力;
- f 2 f_{2} f2是对图片特征张量直接做全局平均池化(global average pooling),所以得到的是通道域的注意力(类比SENet[5]);
- f 3 f_{3} f3 是求图片特征张量在通道域上的平均值的激活函数,类似于忽略了通道域的信息,从而得到空间域的注意力。

总结
经过这种残差结构的堆叠,能够很容易的将模型的深度达到很深的层次,具有非常好的性能。
就是可以将这个Attention的结构无缝连接到目前最优秀的网络中去,使得模型的性能更上一层楼。
问题
输入只能是偶数
效果提升不大,且新引入了很大参数量,训练时间得好久
参考文献
GitHub - fwang91/residual-attention-network: Residual Attention Network for Image Classification
Residual Attention Network for Image Classification - 知乎
论文笔记:Residual Attention Network for Image Classification_小时候贼聪明-CSDN博客
论文地址Residual Attention Network for Image Classification