在介绍RDD之前,先讲点前话:
因为我用的Java api,所以第一件事就是创建一个JavaSparkContext对象,这个对象告诉了Spark如何访问集群
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master); JavaSparkContext sc = new JavaSparkContext(conf);
这个 appName 参数是一个在集群 UI 上展示应用程序的名称。 master 是一个 Spark,Mesos 或 YARN 群集的 URL 地址,或者指定为 “local” 字符串以在 local mode(本地模式)中运行。在实际工作中,当在集群上运行时,您不希望在程序中将 master 给硬编码,而是用 使用 spark-submit 启动应用程序 并且接收它。然而,对于本地测试和单元测试,您可以通过 “local” 来运行 Spark 进程。
一些Spark相关的shell操作在此就不做细说了。
下面开始介绍Spark最重要的一个概念RDD:
RDD(Resilient Distributed Datasets ),弹性分布式数据集,Spark 主要以其为中心,它是一个容错且可以执行并行操作的元素的集合。有两种方法可以创建 RDD : 在你的 driver program(驱动程序)中 parallelizing 一个已存在的集合,或者在外部存储系统中引用一个数据集,例如,一个共享文件系统,HDFS,HBase,或者提供 Hadoop InputFormat 的任何数据源。
Parallelized collections:
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5); JavaRDD<Integer> distData = sc.parallelize(data);
可以在您的 driver program(驱动程序)中已存在的集合上通过调用 SparkContext 的 parallelize 方法来创建并行集合。该集合的元素从一个可以并行操作的 distributed dataset(分布式数据集)中复制到另一个 dataset(数据集)中去。
并行集合中一个很重要参数是 partitions(分区)的数量,它可用来切割 dataset(数据集)。Spark 将在集群中的每一个分区上运行一个任务。通常您希望群集中的每一个 CPU 计算 2-4 个分区。一般情况下,Spark 会尝试根据您的群集情况来自动的设置的分区的数量。当然,您也可以将分区数作为第二个参数传递到 parallelize (e.g. sc.parallelize(data, 10)) 方法中来手动的设置它。
External datasets:
JavaRDD<String> distFile = sc.textFile("data.txt");
Spark 可以从 Hadoop 所支持的任何存储源中创建 distributed dataset(分布式数据集),包括本地文件系统,HDFS,Cassandra,HBase,Amazon S3 等等。 Spark 支持文本文件,SequenceFiles,以及任何其它的 Hadoop InputFormat。
可以使用 SparkContext 的 textFile 方法来创建文本文件的 RDD。此方法需要一个文件的 URI(计算机上的本地路径 ,hdfs://,s3n:// 等等的 URI),并且读取它们作为一个 lines(行)的集合。
使用 Spark 来读取文件的一些注意事项 :
如果使用本地文件系统的路径,所工作节点的相同访问路径下该文件必须可以访问。复制文件到所有工作节点上,或着使用共享的网络挂载文件系统。
所有 Spark 中基于文件的输入方法,包括 textFile(文本文件),支持目录,压缩文件,或者通配符来操作。例如,您可以用 textFile("/my/directory"),textFile("/my/directory/*.txt") 和 textFile("/my/directory/*.gz")。
textFile 方法也可以通过第二个可选的参数来控制该文件的分区数量。默认情况下,Spark 为文件的每一个 block(块)创建的一个分区(HDFS 中块大小默认是 64M),当然你也可以通过传递一个较大的值来要求一个较高的分区数量。请注意,分区的数量不能够小于块的数量。
RDD操作:
RDD支持两种操作:transformation和action
1、transformations(转换):在一个已存在的 dataset 上创建一个新的 dataset。
2、actions(动作): 将在 dataset 上运行的计算结果返回到驱动程序。
需要注意的是,RDD转化过程都是惰性求值的。这意味着在被调用行动操作之前Spark不会开始计算,spark会在内部记录下所要求执行的操作的相关信息,我们可以把每个RDD看作我们通过转化操作构建出来的、记录如何计算数据的指定列表。把数据读取到RDD的操作同样是惰性的。
RDD提供了许多转换操作,每个转换操作都会生成新的RDD,这是新的RDD便依赖于原有的RDD,这种RDD之间的依赖关系最终形成了DAG( Directed Acyclic Graph 有向无环图)。
RDD之间的依赖关系分为两种,分别是NarrowDependency与ShuffleDependency,其中ShuffleDependency为子RDD的每个Partition都依赖于父RDD的所有Partition,而NarrowDependency则只依赖一个或部分的Partition。下图的groupBy与join操作是ShuffleDependency,map和union是NarrowDependency。
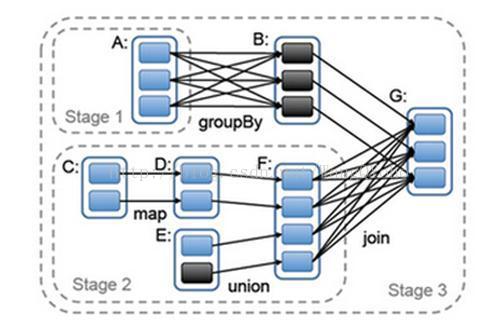
当执行到一个action时,会依次倒溯,完成每一次transformation。默认情况下,每次你在 RDD 运行一个 action 的时, 每个 transformed RDD 都会被重新计算。但是,您也可用 persist (或 cache) 方法将 RDD persist(持久化)到内存中;在这种情况下,Spark 为了下次查询时可以更快地访问,会把数据保存在集群上。此外,还支持持续持久化 RDDs 到磁盘,或复制到多个结点。
持久化存储:
SparkRDD是惰性求值的,而有时候我们希望能够多次使用同一个RDD。如果简单地对RDD调用行动操作,Spark每次都会重算RDD以及它的所有依赖。这在迭代算法中消耗很大。
此时我们可以让spark对数据进行持久化操作。当我们让Spark持久化存储一个RDD时,计算出的RDD节点会分别保存它们所求出的RDD分区数据。如果一个有持久化数据的节点发生故障,Spark会在需要用到缓存数据时重算丢失的数据分区。我们可以把我们的数据备份到多个节点避免这种情况发生。
传递参数给Spark:
当驱动程序在集群上运行时,Spark 的 API 在很大程度上依赖于传递函数。有2种推荐的方式来做到这一点 :
1、匿名函数的语法 Anonymous function syntax,它可以用于短的代码片断。
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(new Function<String, Integer>() {
public Integer call(String s) { return s.length(); }
});
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) { return a + b; }
});2、在全局单例对象中的静态方法。例如,你可以定义对象 MyFunctions 然后传递 MyFunctions.func1。
class GetLength implements Function<String, Integer> {
public Integer call(String s) { return s.length(); }
}
class Sum implements Function2<Integer, Integer, Integer> {
public Integer call(Integer a, Integer b) { return a + b; }
}
JavaRDD<String> lines = sc.textFile("data.txt");
JavaRDD<Integer> lineLengths = lines.map(new GetLength());
int totalLength = lineLengths.reduce(new Sum());
关键问题!Spark集群模式下理解闭包:
在集群中执行代码时,一个关于 Spark 更难的事情是理解的变量和方法的范围和生命周期。
修改其范围之外的变量 RDD 操作可以混淆的常见原因。在下面的例子中,我们将看一下使用的 foreach() 代码递增累加计数器,但类似的问题,也可能会出现其他操作上。
int counter = 0;
JavaRDD<Integer> rdd = sc.parallelize(data);
// Wrong: Don't do this!!
rdd.foreach(x -> counter += x);
println("Counter value: " + counter);
上面的代码行为是不确定的,并且可能无法按预期正常工作。Spark 执行作业时,会分解 RDD 操作到每个执行者里。在执行之前,Spark 计算任务的 closure(闭包)。而闭包是在 RDD 上的执行者必须能够访问的变量和方法(在此情况下的 foreach() )。闭包被序列化并被发送到每个执行器。
闭包的变量副本发给每个 executor ,当 counter 被 foreach 函数引用的时候,它已经不再是 driver node 的 counter 了。虽然在 driver node 仍然有一个 counter 在内存中,但是对 executors 已经不可见。executor 看到的只是序列化的闭包一个副本。所以 counter 最终的值还是 0,因为对 counter 所有的操作所有操作均引用序列化的 closure 内的值。
在本地模式,在某些情况下的 foreach 功能实际上是同一 JVM 上的驱动程序中执行,并会引用同一个原始的计数器,实际上可能更新。
为了确保这些类型的场景明确的行为应该使用的 Accumulator(累加器)。当一个执行的任务分配到集群中的各个 worker 结点时,Spark 的累加器是专门提供安全更新变量的机制。这个之后再说了。
在一般情况下,closures - constructs 像循环或本地定义的方法,不应该被用于改动一些全局状态。Spark 没有规定或保证突变的行为,以从封闭件的外侧引用的对象。一些代码,这可能以本地模式运行,但是这只是偶然和这样的代码如预期在分布式模式下不会表现。改用如果需要一些全局聚集累加器。