什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的5特属性
- 获取分区列表(getPartitions):有一个数据分片列表,能够将数据进行切分,切分后的数据能够进行并行计算,是数据集的原子组成部分。
- 可以在每一个分区上进行计算(compute):计算每个分区,得到一个可便利的结果,用于说明在父RDD上执行何种计算。
- 获取每个RDD的依赖(getDependencies):计算每个RDD对父RDD的依赖列表,源RDD没有依赖,通过依赖关系描述血统。
- RDD的键值分区器( @transient val partitioner: Option[Partitioner] = None):描述分区模式和数据存放的位置,键值对的RDD根据哈希值进行分区。
- 在那个分区上进行计算最好(getPreferredLocations):每一个分片的优先计算位置。
通俗点来讲,可以将 RDD 理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个 RDD 可以分成多个分区,每个分区就是一个数据集片段。一个 RDD 的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同结点上进行并行计算。
RDD 的基本概念
RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。
Spark基于弹性分布式数据集(RDD)模型,具有良好的通用性、容错性与并行处理数据的能力RDD( Resilient Distributed Dataset):弹性分布式数据集(相当于集合),它的本质是数据集的描述,记录对数据的存储位置,处理方法,转换关系,和处理后的数据形式等(只读的、可分区的分布式数据集),而不是数据集本身,分区时会尽量均匀
图 1 展示了 RDD 的分区及分区与工作结点(Worker Node)的分布关系。

RDD的优点
Spark的设计就是基于这个抽象的数据集(RDD),你操作RDD这个抽象的数据集,就像操作一个本地集合一样,Spark包底层的细节都隐藏起来的(任务调度、Task执行,任务失败重试等待),开发者使用起来更加方便简洁
操作RDD,其实是对每个分区进行操作,分区会生成Task,Task会调度Executor上执行相关的计算逻辑,进而对数据进操作
理解从HDFS读入文件默认是怎样分区的
Spark从HDFS读入文件的分区数默认等于HDFS文件的块数(blocks),HDFS中的block是分布式存储的最小单元。如果我们上传一个30GB的非压缩的文件到HDFS,HDFS默认的块容量大小128MB,因此该文件在HDFS上会被分为235块(30GB/128MB);Spark读取SparkContext.textFile()读取该文件,默认分区数等于块数即235。
图解RDD
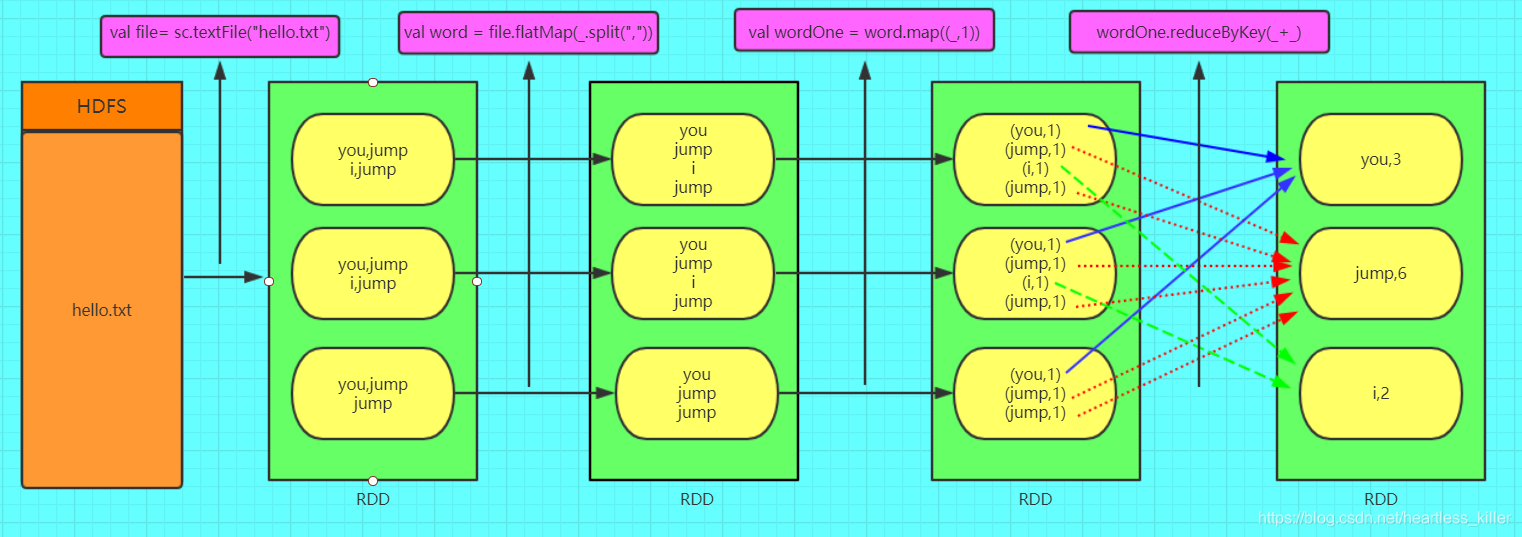
RDD的创建方式
2.1 通过读取文件生成的
由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
scala> val file = sc.textFile("/spark/hello.txt")

2.2通过并行化的方式创建RDD
由一个已经存在的Scala集合创建。
scala> val array = Array(1,2,3,4,5)
array: Array[Int] = Array(1, 2, 3, 4, 5)
scala> val rdd = sc.parallelize(array,2) //后面的参数可以指定2分区数量
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at parallelize at <console>:26

3.调用一个已经存在了的RDD的Transformation,会生成一个新的RDD
)
RDD编程API
Spark支持两个类型(算子)操作:Transformation和Action
Transformation
主要做的是就是将一个已有的RDD生成另外一个RDD。Transformation具有lazy特性(延迟加载)。Transformation算子的代码不会真正被执行。只有当我们的程序里面遇到一个action算子的时候,代码才会真正的被执行。这种设计让Spark更加有效率地运行。
常用的Transformation:
| 函数名 | 作用 | 实例 | 结果 |
|---|---|---|---|
| map(func) | 将函数应用于 RDD 的每个元素,返回值是新的 RDD | rdd1.map(x=>x+l) | {2,3,4,4} |
| mapValue(func) | 将函数应用于(K,V) ,RDD 的每个元素的value,返回值是新的 RDD | rdd1.mapValue(_.sum) | “jarry”:(1),tom:(1,2,3)---->“jarry”:1,“tom”,6 |
| flatMap(func) | 将函数应用于 RDD 的每个元素,将元素数据进行拆分,变成迭代器,返回值是新的 RDD ,即会扁平化 | rdd1.flatMap(x=>x.to(3)) | {1,2,3,2,3,3,3} |
| filter(func) | 函数会过滤掉不符合条件的元素,返回值是新的 RDD | rdd1.filter(x=>x!=1) | {2,3,3} |
| distinct() | 将 RDD 里的元素进行去重操作 | rdd1.distinct() | (1,2,3) |
| union() | 生成包含两个 RDD 所有元素的新的 RDD | rdd1.union(rdd2) | {1,2,3,3,3,4,5} |
| join() | 在(K,V)上调用,对于相同key的对象,将其整合在一起 | rdd1.join(rdd2) | {“jarry”:1,“tom”:1,“tom”,2},{“tom”:1,“lin”:1} ——》{“tom”,(1,2),“tom”,(1,1),”jarry”,(1,1)} |
| intersection() | 求出两个 RDD 的共同元素 | rdd1.intersection(rdd2) | {3} |
| subtract() | 将原 RDD 里和参数 RDD 里相同的元素去掉 | rdd1.subtract(rdd2) | {1,2} |
| cartesian() | 求两个 RDD 的笛卡儿积 | rdd1.cartesian(rdd2) | {(1,3),(1,4)……(3,5)} |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] | rdd.mapPartitions((it: Iterator[Int])=> { it.map(e => $e")}) | |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在的RDD上运行时,func的函数类型必须是(Int, Interator[T](int表示分区编号,interrator表示分区的引用)) => Iterator[U]------------------------------------------一次拿出一个分区(分区中并没有数据,而是记录要读取哪些数据,真正生成的Task会读取多条数据),并且可以将分区的编号取出来 ~~~~~~~功能:取分区中对应的数据时,还可以将分区的编号取出来,这样就可以知道数据是属于哪个分区的(哪个区分对应的Task的数据) | mapPartitionsWithIndex( func) val func = (index: Int, it: Iterator[Int]) => { it.map(e => s"part: $index, ele: $e")}//该函数的功能是将对应分区中的数据取出来,并且带上分区编号 传入的参数第一个是参数的编号,第二个是对分区数据的引用,可对分区数据独立操作 | |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD | “jarry”:1,“tom”:1,“tom”,2,“tom”,2,“tom”:3—>“jarry”:(1),tom:(1,2,3) | |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置,局部先进行聚合,然后全局聚合,局部和全局运用同一个函数进行处理 | ||
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 在一个(K,V)的RDD上调用, 先按分区聚合 再总的聚合 ,调用两个函数,分别应用与第一次和第二次 每次要跟初始值交流 | aggregateByKey(0)(—±---,—±---) 对k/y的RDD进行操作 | |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD | ||
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 第一个参数是根据什么排序 第二个是怎么排序 false倒序 第三个排序后分区数 默认与原RDD一样 | ||
| mapValues(func) | mapValues顾名思义就是输入函数应用于RDD中Kev-Value的Value,原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素。因此,该函数只适用于元素为KV对的RDD。 | ||
| foldByKey(zero)(func, [numTasks]) | 和ruduceByKey类似只是多了个初始值 | b.mapValues(“x” + _ + “x”) | |
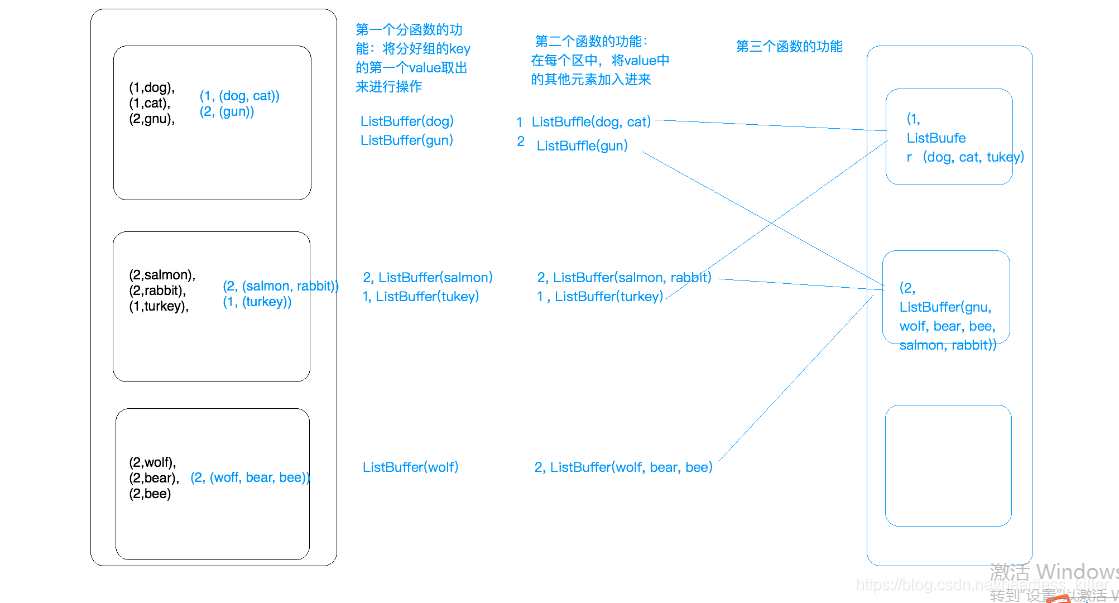
| combineByKey(func1,func2,func3) | 在一个(K,V)的RDD上调用, 第一个分函数的功能将分好组的key的第一个value取出来进行操作,第二个函数的作用是,将每个分区除第一个value的其他value进行操作,第三个函数将各个分区的结果根据key相同的进行操作,因为是比较底层的方法,所以需要指定参数 | rdd.combineByKey(x=>x,(a:Int,b:Int)=>{a+b},(n:Int,m:Int)=>{n+m}) //普通的key/value加和 代码二:rdd.combineByKey(x=>ListBuffer[String],(a:ListBuffer[String],b:Int)=>{a+=b}),(n:ListBuffer[String],m:ListBuffer[String])=>{n++=m} //第一个分函数,将每个key的第一个value加入List,第二个分函数,根据key,将其余的value加入List,第三个value,将各个分区的结果进行整合,根据key进行整合 | 结果如下图和执行过程 |
Action
触发代码的运行,我们一段spark代码里面至少需要有一个action操作。当我们的程序里面遇到一个action算子的时候,代码才会真正的被执行。
| 函数名 | 作用 | 示例 | 结果 |
|---|---|---|---|
| collect() | 返回 RDD 的所有元素 | rdd.collect() | {1,2,3,3} |
| count() | RDD 里元素的个数 | rdd.count() | 4 |
| countByKey() | RDD 出现的元素的个数 | rdd.count() | (“a”,1)(“b”,2)(“c”,3")(a",1) 变成a–>2,b–>1,c–>1 |
| countByValue() | 各元素在 RDD 中的出现次数 | rdd.countByValue() | {(1,1),(2,1),(3,2})} |
| take(num) | take用于获取RDD中从0到num-1下标的元素,不排序。 | rdd.take(2) | {1,2} |
| top(num) | 从 RDD 中,按照默认(降序)或者指定的排序返回最前面的 num 个元素 | rdd.top(2) | {3,3} |
| reduce() | 并行整合所有 RDD 数据,如求和操作 | rdd.reduce((x,y)=>x+y) | 9 |
| fold(zero)(func) | 和 reduce() 功能一样,但需要提供初始值 | rdd.fold(0)((x,y)=>x+y) | 9 |
| foreach(func) | 对 RDD 的每个元素都使用特定函数 | rdd1.foreach(x=>printIn(x)) | 打印每一个元素 |
| foreachPartition(func) | 对 RDD 的每个元素都使用特定函数 ,但是分区,需要传入参数为Iterator[V]函数 | rdd1.foreach(it=>it.foreach(x=>println())) | 分区打印每一个元素 |
| saveAsTextFile(path) | 将数据集的元素,以文本的形式保存到文件系统中 | rdd1.saveAsTextFile(file://home/test) | |
| saveAsSequenceFile(path) | 将数据集的元素,以顺序文件格式保存到指 定的目录下 | saveAsSequenceFile(hdfs://home/test) | |
| aggregate(zero)(func1,func2) | 先对分区进行操作,在总体操作,第一个参数指定初始值,可传入两个函数(局部和全局,都需要与初始值比较) | rdd1.aggregate(20)(math.max(_ ,) ,+)//局部先找出最大值(找最大值时候需要和初始值比较,然后将其求和)————————————————————rdd1.aggregate(@)(+,+_)//将字符串拼接,局部和全局拼接都需要用到初始值@ | (a,b,c)(d,e,f,)------>@@abc@def |
| flatMapValue(func) | 将函数应用于 RDD 的每个元素的Value,将元素数据进行拆分,变成迭代器,返回值是新的 RDD ,即会扁平化 | rdd1.flatMapValue(-.split("_")) | {“a”,(“1”,“2”),“b”(,“2”,“2”)}----->a,1 a,2 b,2 b,2 |
| sortBy | sortBy根据给定的排序k函数将RDD中的元素进行排序。 | //按照V进行降序排序scala> rdd1.sortBy(x => x._2,false).collectres4: Array[(String, Int)] = Array((B,7), (B,6), (B,3), (A,2), (A,1)) |
WordCount代码
精简版
sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).sortBy(_._2, false).saveAsTextFile(args(1))
详细版
object WordCount {
def main(args: Array[String]): Unit = {
//创建spark配置,设置应用程序名字
//val conf = new SparkConf().setAppName("ScalaWordCount")
val conf = new SparkConf().setAppName("ScalaWordCount").setMaster("local[4]")
//创建spark执行的入口
val sc = new SparkContext(conf)
//指定以后从哪里读取数据创建RDD(弹性分布式数据集)
val lines: RDD[String] = sc.textFile("hdfs://node-4:9000/wc1", 1)
//分区数量
partitionsNum=lines.partitions.length
//切分压平
val words: RDD[String] = lines.flatMap(_.split(" "))
//将单词和一组合
val wordAndOne: RDD[(String, Int)] = words.map((_, 1))
//按key进行聚合
val reduced:RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//排序
val sorted: RDD[(String, Int)] = reduced.sortBy(_._2, false)
//将结果保存到HDFS中
reduced.saveAsTextFile(args(1))
//释放资源
sc.stop()
}
}
}}
