helloworld
把文件传入 hdfs
$ hadoop fs -ls /
$ hadoop fs -mkdir /input
$ hadoop fs -put /usr/local/spark-2.4.5/README.md /input
2020-04-10 15:22:06,562 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
$ hadoop fs -ls /input
Found 1 items
-rw-r--r-- 2 root supergroup 3756 2020-04-10 15:22 /input/README.md
在 pyspark 中读取文件
>>> lines = sc.textFile("/input/README.md")
>>> lines.persist()
/input/README.md MapPartitionsRDD[13] at textFile at NativeMethodAccessorImpl.java:0
>>> lines.count()
104
>>> lines.first()
u'# Apache Spark
总结
- Create some input RDDs from external data.
- Transform them to define new RDDs using transformations like filter() .
- Ask Spark to persist() any intermediate RDDs that will need to be reused.
- Launch actions such as count() and first() to kick off a parallel computation, which is then optimized and executed by Spark.
一、创建 RDD
两种方式:
- 通过现有的集合创建,
sc.parallelize()
lines = sc.parallelize(["pandas", "i like pandas"])
- 通过外部文件创建
lines = sc.textFile("/path/to/README.md")
二、RDD 操作
两种操作:变换transformation、动作 action
- 变换:RDD => RDD,常见的有:map() , filter()
- 动作:RDD => value,常见的有:count() , first()
1. 变换
filter
inputRDD = sc.textFile("log.txt")
errorsRDD = inputRDD.filter(lambda x: "error" in x)
warningsRDD = inputRDD.filter(lambda x: "warning" in x)
badLinesRDD = errorsRDD.union(warningsRDD)
# 以下是动作
print "Input had " + badLinesRDD.count() + " concerning lines"
print "Here are 10 examples:"
for line in badLinesRDD.take(10):
print line
一个 RDD在创建和变换之后并不会执行,只是定义了一个计算图,有点类似tensorflow,真正遍历数据是在动作
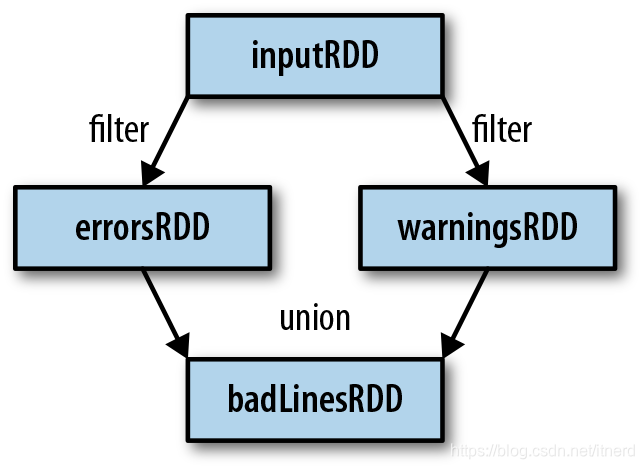
这个例子显然有更好的解法:
badLinesRDD = inputRDD.filter(lambda x: "warning" or "error" in x)
map
nums = sc.parallelize([1, 2, 3, 4])
squared = nums.map(lambda x: x * x)
# 动作
for num in squared.collect():
print "%i " % (num)
注意:collect() 是返回 rdd 的所有元素的动作,不可以在数据总量超过单机内存的情况下使用!!!
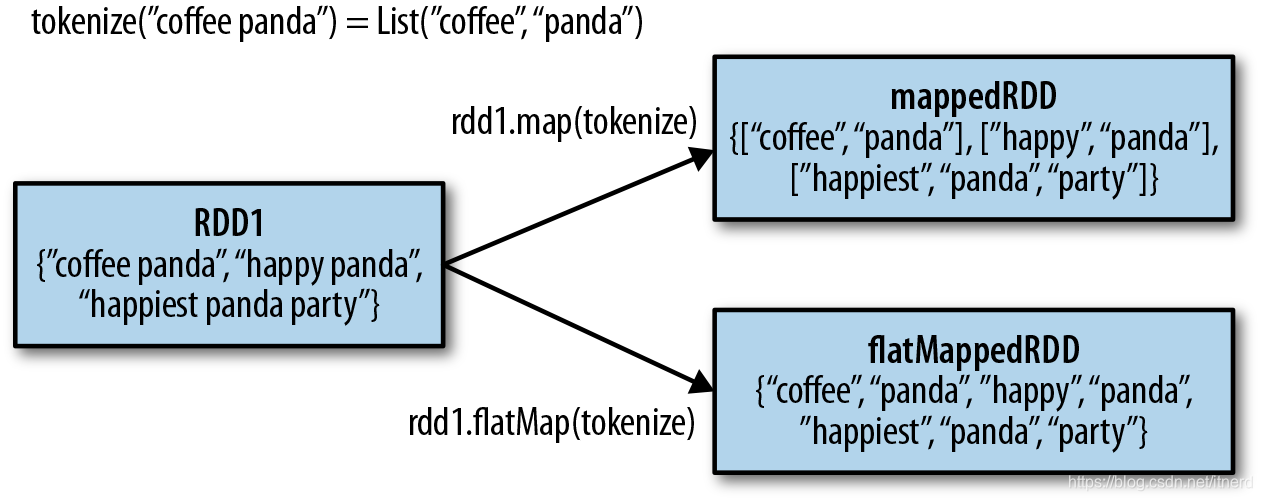
flatmap
>>> lines = sc.parallelize(["hello world", "hi"])
>>> words = lines.flatMap(lambda line: line.split(" "))
>>> words.first()
'hello'
>>> words.collect()
['hello', 'world', 'hi']
和 map 的区别
2. 动作
- count(),
- first(),
- collect(),
- take(10),
- …
三、自定义函数
通过 lambda 表达式
word = rdd.filter(lambda s: "error" in s)
通过 函数
def containsError(s):
return "error" in s
word = rdd.filter(containsError)
注意
不要把类的成员函数传给 filter,否则会把整个对象传给各个计算节点,造成额外开销
