上一章我使用autograd和ndarray实现了一个线性回归,但那只适用于学习,想要快速开发模型最好还是使用gluon来完成。
1、数据集生成
与上一章一样,还是随机生成一些数据:
import mxnet.ndarray as nd
import mxnet.autograd as ag
import mxnet.gluon as gn
import random
num_input=2
num_example=1000
'''---生成数据---'''
true_w=[2,-3.4]
true_b=4.2
x=nd.random_normal(shape=(num_example,num_input)) # 随机生成的数据点x(1000行2列)
y=true_w[0]*x[:,0]+true_w[1]*x[:,1]+true_b
noise=0.01*nd.random_normal(shape=y.shape) # 按照公式写出代码
y=y+noise
# print(y.shape)
print(x[:10],y[:10]) # 打印前10组数据进行查看
2、数据读取
现在使用gluon读取数据:
batch_size=10
dataset=gn.data.ArrayDataset(x,y)
data_iter=gn.data.DataLoader(dataset=dataset,batch_size=batch_size,shuffle=True)
读取一个批次样本看看:
for data,label in data_iter: # 读取第一个batch size看看
print("batch size:",data,label)
break
结果:

3、定义模型
net=gn.nn.Sequential() # 定义一个模型容器
net.add(gn.nn.Dense(1)) # 线性模型就是一个单层的神经网络,这里并没有定义输入节点,在这之后读取数据时系统会自动赋值
print(net)
看看网络结构:
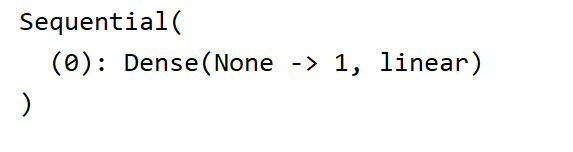
4、初始化训练参数
net.initialize() # 系统初始化参数,包含了weight,bias
5、损失函数
square_loss=gn.loss.L2Loss() # 平方误差(L2误差)
6、优化器
trainer=gn.Trainer(net.collect_params(),optimizer="sgd",optimizer_params={"learning_rate":0.01})
7、训练
epochs=6
for e in range(0,epochs):
total_loss=0
for data, label in data_iter: # 读取第一个batch size看看
with ag.record():
output=net(data)
loss=square_loss(label,output)
loss.backward() # 对loss求导
trainer.step(batch_size)
total_loss+=nd.sum(loss).asscalar()
print("Epoch: %d,average loss: %f"%(e,total_loss/num_example))
运行结果:

为了验证w,b的值,打印看看结果:
print(net[0].weight.data(),net[0].bias.data()) # 取出所在层的权重
结果:

可以看到,w的值为很接近[2,-3.4],b的值很接近4.2。至于为什么与上一篇结果不太一样?那是因为随机生成的数据不一样。
附上所有源码:
import mxnet.ndarray as nd
import mxnet.autograd as ag
import mxnet as mx
import mxnet.gluon as gn
import random
num_input=2
num_example=1000
# mx.random.seed(0) # 固定随机数种子,以便能够复现
'''---生成数据---'''
true_w=[2,-3.4]
true_b=4.2
x=nd.random_normal(shape=(num_example,num_input)) # 随机生成的数据点x(1000行2列)
y=true_w[0]*x[:,0]+true_w[1]*x[:,1]+true_b
noise=0.01*nd.random_normal(shape=y.shape) # 按照公式写出代码
y=y+noise
# print(y.shape)
print(x[:10],y[:10]) # 打印前10组数据进行查看
'''---数据读取---'''
batch_size=10
dataset=gn.data.ArrayDataset(x,y)
data_iter=gn.data.DataLoader(dataset=dataset,batch_size=batch_size,shuffle=True)
for data,label in data_iter: # 读取第一个batch size看看
print("batch size:",data,label)
break
'''---取多少次样本?---'''
# n=0
# for data,label in data_iter(): # 读取第一个batch size看看
# n+=1
# print(n)
'''--------------------定义模型---------------------'''
net=gn.nn.Sequential() # 定义一个模型容器
net.add(gn.nn.Dense(1)) # 线性模型就是一个单层的神经网络,这里并没有定义输入节点,在这之后读取数据时系统会自动赋值
print(net)
# 初始化模型参数
net.initialize() # 系统初始化参数,包含了weight,bias
# 损失函数
square_loss=gn.loss.L2Loss() # 平方误差(L2误差)
#优化
trainer=gn.Trainer(net.collect_params(),optimizer="sgd",optimizer_params={"learning_rate":0.01})
# 训练
epochs=6
for e in range(0,epochs):
total_loss=0
for data, label in data_iter: # 读取第一个batch size看看
with ag.record():
output=net(data)
loss=square_loss(label,output)
loss.backward() # 对loss求导
trainer.step(batch_size)
total_loss+=nd.sum(loss).asscalar()
print("Epoch: %d,average loss: %f"%(e,total_loss/num_example))
print(net[0].weight.data(),net[0].bias.data()) # 取出所在层的权重
# help(net[0].weight.data())
