本节将介绍如何只利⽤ Tensor 和 autograd 来实现⼀个线性回归的训练。
⾸先,导⼊本节中实验所需的包或模块,其中的matplotlib包可⽤于作图,且设置成嵌⼊显示。
⾸先,导⼊本节中实验所需的包或模块:
import torch
from IPython import display
from matplotlib import pyplot as plt #matplotlib包可用于作图,且设置成嵌入显示
import numpy as np
import random一、生成数据集
我们构造⼀个简单的⼈⼯训练数据集,它可以使我们能够直观⽐较学到的参数和真实的模型参数的区
别。设训练数据集样本数为1000,输⼊个数(特征数)为2。给定随机⽣成的批量样本特征 \(X \in R^{1000 \times 2}\),我们使⽤线性回归模型真实权 \(w = [2,-3.4]^T\) 和偏差 \(b = 4.2\) ,以及⼀个随机噪声项 \(\epsilon\) 来⽣成标签
\[ y = Xw + b + \epsilon \]
其中噪声项 \(epsilon\) 服从均值为0、标准差为0.01的正态分布。噪声代表了数据集中⽆意义的⼲扰。下⾯,让我们⽣成数据集。
# 1.生成数据集
num_inputs = 2 #2个特征
num_examples = 1000 #训练集1000个样本数量
true_w = [2,-3.4] #两个特征的权重值
true_b = 4.2 # 偏差
features = torch.from_numpy(np.random.normal(0,1,(num_examples,num_inputs)))
# 下面两行是使用一个随机噪声生成标签$y = Xw+b+ \epsilon$
lables = true_w[0] = features[:,0] + true_w[1] * features[:,1] + true_b
lables += torch.from_numpy(np.random.normal(0,0.01,size=lables.size()))
#注意:`features`的每一行是一个长度为2的向量,而`lables`的每一行是一个长度为1的向量(标量)。
print(features[0],lables[0])输出结果:
tensor([0.8702, 1.1407], dtype=torch.float64) tensor(1.2039, dtype=torch.float64)绘制线性关系图:
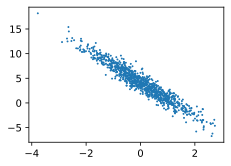
# 通过生成第二个特征`features[:,1]和标签`lables`的散点图,可以更直观观察两者间的线性关系
# 若没有导入`/d2lzh_pytorch`包里添加下面两个函数,则需要在此添加
def use_svg_display():
# 用矢量图显示
display.set_matplotlib_formats('svg')
def set_figsize(figsize = (3.5,2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
"""
# 在d2lzh_pytorch里面添加上面两个函数后就可以这样导入
import sys
sys.path.append("..")
from d21zh_pytorch import *
"""
set_figsize()
plt.scatter(features[:,1].numpy(),lables.numpy(),1);输出图片:
二、读取数据
在训练模型的时候,我们需要遍历数据集并不断读取⼩批量数据样本。这⾥我们定义⼀个函数:它每次返回 batch_size(批量⼤⼩)个随机样本的特征和标签。