论文链接: https://arxiv.org/abs/1811.00538.
1. 介绍
对于大多数的VQA来说,可以直接从图像内容获取到问题的答案无须推理过程,使用一般知识进行推理仍然是算法挑战。为了推进这方面的研究,最近引入了一种新的“基于事实的”视觉问题回答(FVQA)任务,以及一个附带的数据集,其中包含图像,带有相应答案的问题以及从三个不同来源提取的事实的知识库(KB):WebChild ,DBPedia 和ConceptNet 。与经典的VQA数据集不同,FVQA数据集中的问题是通过对图像中的信息和知识库中的事实的集体分析来回答的。每个问题都映射到一个包含问题答案的支持事实。因此,回答一个问题需要分析图像并选择正确的支持事实。

给定一个图像 I 和相应的问题Q,基于事实的图像问答任务(FVQA)任务是使用一个由事实组成的外部知识库KB来预测答案,即,KB={f1,f2,…,f|KB|}。一个事实表示为 f=(x,r,y)形式,其中x是一个基于图像的视觉概念,y是一个属性或短语,r∈R是x和y两个实体之间的关系,分别使用x(f)、y(f)或rel(f)提取。知识库中的关系是一组13个可能的关系的一部分:R={Category,Comparative,HasA,IsA,HasProperty,CapableOf,Desires,RelatedTo,AtLocation,PartOf,ReceivesAction,UsedFor,CreatedBy} 。作者提出了FVQA数据集,该数据集有2190图片,5286问题,问题对应了4126事实。上面的三张图便是摘自FVAQ事实视觉问答任务。
左图问题:图片中的区域是用来做什么的?
事实三元组:(Field,UsedFor,Grazing Animals)田野用于放牧
中间问题:图中的哪个物体和老虎更相近?
事实三元组:( Cat,RelatedTo,Tiger)猫和老虎相关
右图问题:这张图中的地上能找到什么?
事实三元组(Sand,AtLocation,Beatch)沙子在沙滩上
2. Visual Question Answering with Knowledge Bases

上图中标有的7个小步骤:给定一个图像和一个问题,我们使用相似度评分技术(1)从事实空间获得相关事实(2)LSTM从问题预测关系,以进一步减少相关事实及其实体的集合。将图像的视觉概念嵌入(3)、问题的LSTM嵌入(4)和实体的LSTM嵌入(5)串联起来,得到实体嵌入。(6)每个实体在图中形成单个节点,并且关系构成边 GCN ,(7)GCN和MLP进行联合评估来预测答案。
该方法的重点是学习用于检索正确事实的联合图像-问题-事实嵌入,我们开发了一种基于图卷积网(GCN)的方法,用于基于知识库的视觉问题回答。在接下来的部分中,首先概述所提议的方法,然后再深入研究各个组件的细节。
概述:每个问题Q都与一个单一的事实相关联f,这有助于回答问题。更具体地说,答案 A 是这一事实的两个实体之一,即A=x或A=y,这两个实体都可以从f=(x,r,y*)中提取。由于存在超过190000个事实,因此获取正确的支持f是很有挑战性的,而且计算效率也很低。为了获得正确的支持f,我们开发了两个步骤的解决方案:(1) 检索给定问题图像对的最相关事实。(2)将预测答案作为简化事实空间fREL中的实体之一。
由图2可知,作者提出的方法主要分为两个模块,左边的事实检索模块,右边的答案预测模块
(1 )事实检索模块:检索给定问题- 图像对的最相关事实。采用了相似性评分技术,执行初始会从问题中移除停止词(例如“做什么”,“在哪里”,“了”)。为了给每个事实分配相似性得分,我们计算手套嵌入事实中每个单词与问题中的单词的余弦相似度和与检测到的视觉概念中单词的余弦相似度。我们选择事实中具有最高相似度的单词的前ķ%(K = 80可以得到最好的结果),并将这些值平均作为该事实的相似性得分。根据问题与事实之间的单词相似性提取前100个事实,即f100。通过基于事实关系与预测关系的一致性来减少F100,来获得一组相关事实 fREL(事实关系与预测关系的一致性是LSTM从问题中预测到的关系,去和检测到的100个事实中的关系匹配筛选,预测到的关系是ISA,那么就从F100中把不是ISA关系的事实筛掉)
对于每个问题,事实 frel中的唯一实体被分组为一组候选实体,E={x(f):f∈frel}∪{y(f):f∈frel}, |E|≤200(2个实体/事实,最多100个事实)
(2 )答案预测模块:将答案预测为这个减少的事实空间中的一个实体。为了共同评估 E 中所有候选实体的适用性,我们开发了一种基于图形卷积网(GCN)的方法,该方法由多层感知器(MLP)增强。所用图中的节点对应于可用实体e∈E={x(f):f∈frel}∪{y(f):f∈frel},它们的节点表示作为GCN的输入(***即X或者y在事实空间中。如果事实与两者相关,则图中的两个实体是连接的。使用GCN允许联合评估所有实体的适用性)***。GCN以多个迭代步骤组合实体表示.。由GCN学习的最终转换后的实体表示被用作mlp的输入,mlp预测每个实体e∈E的二进制标签,即{1,0},指示e是否是答案。
更正式地说,GCN的目标是学习如何组合图形的节点e∈E的表示。在我们的例子中,每个节点e∈E由相应的图像、问题和实体表示的串联表示,即: . GCN由L隐层组成,其中每个层都是非线性函数f(·,·)
. GCN由L隐层组成,其中每个层都是非线性函数f(·,·) 其中GCN的输入为H(0)。 GCN的输出
其中GCN的输入为H(0)。 GCN的输出 通过MLP获得概率
通过MLP获得概率 ,这个e∈E是给定的问题图像对的答案。我们得到了预测的答案
,这个e∈E是给定的问题图像对的答案。我们得到了预测的答案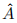 通过
通过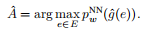
如上面所述,每个节点e∈E由相应的图像、问题和实体表示的串联表示,即gw(e) = (gvw(I),gQw(Q),gCw(e))。下面介绍下这三种说法:
1).图像表示:图像表示gvw(I)∈{0,1}1176是一个大小为1176的 multi-hot vector,表示基于图像的视觉概念。图像中检测到三种类型的视觉概念:动作、场景和对象。
2). 问题表示: 使用LSTM网络将每个问题编码到表示gQw(Q)∈R128中。LSTM是用手套嵌入对问题中的每个单词进行初始化的,在训练期间进行了微调。LSTM的隐藏表示构成了问题编码。
3).实体表示: 对于每个问题,实体gCw(e)针对实体集 E设置中的每个实体e进行计算。注意,一个实体通常由多个单词组成。因此,类似的对于问题编码,使用LSTM网络的隐藏表示。手套嵌入每个单词在实体中进行初始化,在训练过程中进行微调
答案预测模型参数由问题嵌入、实体嵌入、GCN和MLP的权重组成。这些是端到端的训练。
3. 实验

之前在FVQA上表现最好的STTF方法的准确率为62.20%,本文最好的结果12有69.35%,比先前高了7%。上面的表是其它方法的准确率,下面的表是作者做的控制变量实验。说明VC(Visual Concept),MLP,GCN Layers,REL对模型的作用。
用一张来自FVQA论文的图解释一下视觉概念:

只看最左边这列,一张图,用目标检测器,场景分类器,属性分类器,从图中提取出物体,场景,动作三种信息,得到图中的目标为猫,狗,围栏,场景为庭院,行为是坐着和站立这些视觉概念在本文的方法中用于和问题嵌入,实体嵌入连接,形成节点图作为GCN的输入本文中VC的图如下:
 下图是成功案例和失败案例:成功案例显示在前两行。我们的方法正确地预测了关系、视觉概念和答案。下面一行显示了三种不同的故障情况。
下图是成功案例和失败案例:成功案例显示在前两行。我们的方法正确地预测了关系、视觉概念和答案。下面一行显示了三种不同的故障情况。

