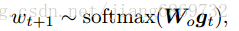《iVQA: Inverse Visual Question Answering》读书笔记
一、iVQA介绍
VQA是根据image、question生成关于image的答案,而iVQA是VQA的逆过程,给出一个answer、image生成与之相关的question。
二、iVQA面临的挑战
(1) iVQA模型利用问题偏差的可能性可能小于VQA通过答案偏差得分高的范围(问题偏差较少,利用它比分类答案更难);
(2)与VQA中的问题相比,答案本身在iVQA中提供了非常稀疏的线索。因此,在iVQA中单独从答案中推断问题的机会可能少于在VQA中单独从问题中推断出答案的机会。 因此,iVQA任务更依赖于理解图像内容;
(3) 从知识表示和推理的角度来看,iVQA可以提供测试更复杂的推理策略的机会,例如反事实推理。
三、文章的贡献
(1)新颖的iVQA问题被引入作为高级多模态视觉语言理解的替代挑战;
(2)我们提出了一种基于多模态动态关注的iVQA模型;
(3)我们提出了一个基于问题排名的iVQA评估方法,有助于诊断不同模型的优缺点;
(4)作为VQA的双重问题,我们表明iVQA有可能帮助提高VQA性能。
四、实验模型
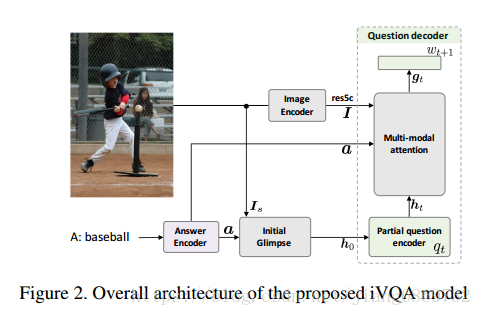
所需解决问题的定义:
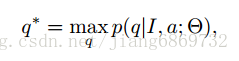
模型共包括3部分
1. Image Encoder
从给定的image中提取局部和全局信息,使用ResNet-152模型计算的res5c特征用作局部特征 ,得到2048*14*14,2028表示通道数;全局信息利用image caption中最常用的1000个语义概念作为image的全局信息
2. Answer Encoder
使用具有512个单元的LSTM,将final hidden state和cell state的串联作为答案a的表示
3. Question decoder
Question decoder部分包括Multi-modal attention
Dynamic multi-modal attention
- Initial glimpse
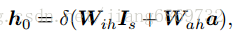
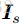
- Encoding of partial question
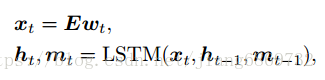
- Multi-modal attention network
为了获得部分问题 - 答案上下文,将部分问题编码ht和答案编码a融合为:

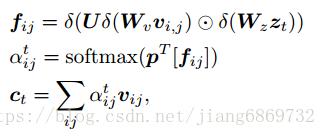
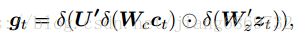
- Word predictor