Paper name
Retrieval Augmented Visual Question Answering with Outside Knowledge
Paper Reading Note
URL: https://arxiv.org/pdf/2210.03809.pdf
TL;DR
- EMNLP 2022 文章,提出名为 RA-VQA 的一种联合训练方案,该方案可以同时训练答案生成模块和文档检索模块,从而可以以端到端的方式训练系统
Introduction
背景

- 外部知识视觉问答(OK-VQA)是一项具有挑战性的VQA任务,需要检索外部知识来回答有关图像的问题
- 最近的OKVQA系统使用密集段落检索(DPR)从外部知识库(如维基百科)检索文档,但DPR与答案生成分开训练,这可能会限制系统的整体性能
- 之前的工作 Retrieval Augmented Generation (RAG) 已经表明,基于DPR的QA系统端到端联合训练可以优于两步系统的 baseline;RAG 的一个显著特征是它的损失函数:它结合了检索到的文档的边缘似然,使得每当文档改进预测时,文档的训练分数都会增加。然而在 OK-VQA 上初步做 RAG 实验并没有好的效果,经过调查发现,OK-VQA训练问题中的很大一部分可以通过仅从图像中提取的信息以闭卷形式回答(即使用T5等预训练模型(Raffel等人,2020)),结果是RAG损失函数在文档上进行的 award 实际上没有助于回答问题;另外 OK-VQA 比 RAG 做实验的 Open QA 数据集更难,存在更多的无法用可检索的知识回答的疑难问题
- 本文制定了一个损失函数,避免在存在不相关文档的情况下向检索模型发送误导信号
本文方案
- 本文提出了一种联合训练方案,该方案包括与答案生成集成的可微DPR,从而可以以端到端的方式训练系统
- 还引入了新的诊断指标来分析检索和生成是如何交互的
- 本文模型的强大检索能力显著减少了训练中所需的检索文档数量,在训练所需的答案质量和计算资源方面产生了显著的好处
- 本文主要贡献有
- 提出了一种用于知识检索和答案生成的联合训练框架(RA-VQA),改进了Retrieval Augmented Generation (RAG) 和基于DPR的两步基线系统
- 调查了转化为“语言空间”的视觉基础特征,并评估其对OK-VQA性能的贡献
- 研究了文档检索在KB-VQA中的作用,并评估了其与检索增强生成的交互作用。同时还表明,在联合训练中,检索变得更加有效,需要在训练中检索相对较少的(~5)文档
Dataset/Algorithm/Model/Experiment Detail
实现方式
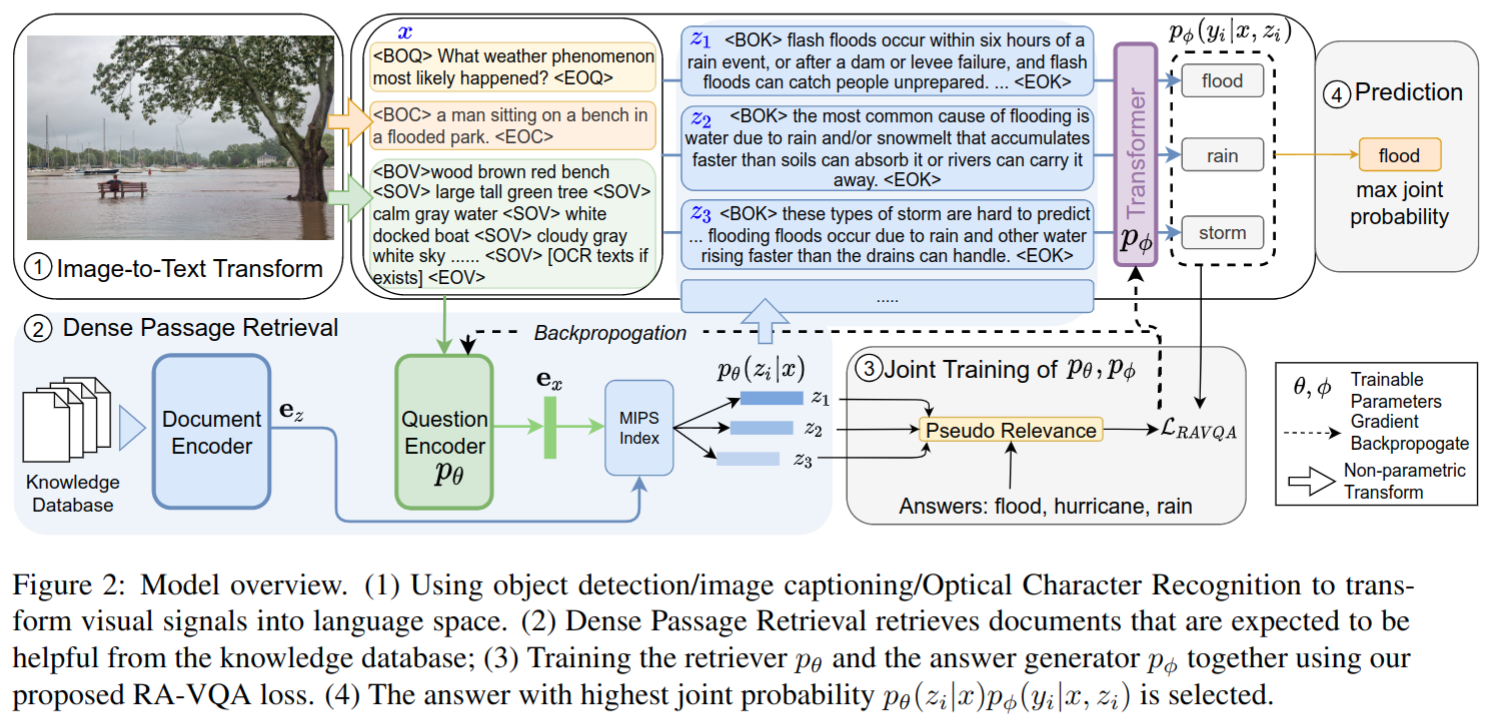
Vision-to-Language Transformation
- 在RA-VQA中,每个图像都由视觉目标及其属性、图像标题和图像中检测到的任何文本字符串表示
- 目标检测模型使用 VinVL,属性包括颜色和材质
- 图像标题模型用的是 Oscar+
- 文本字符串用 Google OCR API 来提取
- 基于上述模型处理,视觉图片被处理为只有文本的训练集
Weakly-supervised Dense Passage Retrieval (DPR)
- DPR 包含 query encoder 和 document encoder,都是 transformer 结构,目标是基于与 query 的相似性从外部数据库中检索出 K 个有助于回答问题的 document,相似性就是特征內积计算得到
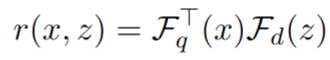
- RA-VQA 在训练过程中对于 document 和回答问题相关时,最大化相似度 r(x, z)
- 基于伪相关作为监督信号:当 document z 中包含答案时(通过字符串匹配)相关性为 1,否者为 0。DPR 的 loss 函数如下
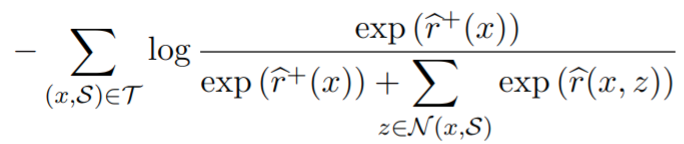
其中 r+ 为正样本,r为负样本
- 基于伪相关作为监督信号:当 document z 中包含答案时(通过字符串匹配)相关性为 1,否者为 0。DPR 的 loss 函数如下
Joint Training of Retrieval and Answer Generation
- DPR 基于 query x 从数据库中检索出最相关的 document z,检索的 document 的分数基于如下公式计算
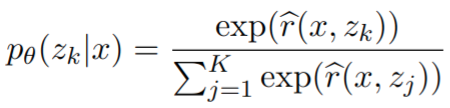
- 基于 T5 之类的文本模型生成答案
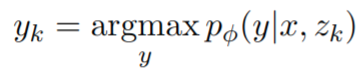
- 对于训练样本检索到的每个 document,都与 x concat 后生成答案 s k ∗ s_{k}^{*} sk∗,对于答案集 S 中的答案,如果在 document 中则会被选择为 gt,如果 document 中不包含任何答案,则选择 S 中最 popular (OKVQA 每个问题有5个标注员,投票最多的答案是最 popular) 的答案作为 gt
- 基于模型预测结果和伪相关标签将检索的 document 分为两类
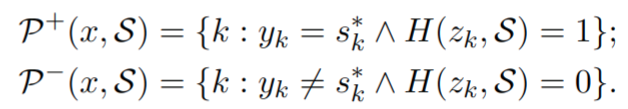
P+ 是伪相关文档的索引,同时也有助于模型生成 popular 答案;P- 是指不利于生成答案的文档,训练loss 如下
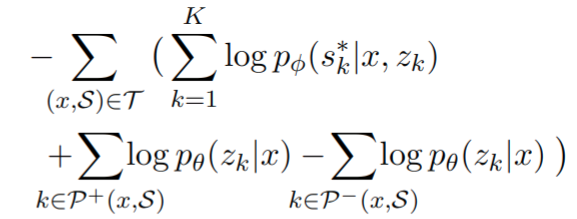
损失中的第一项改进了从查询和检索到的文档中生成答案的能力;其余项影响文档检索能力:第二个 loss 鼓励检索不仅伪相关而且能够产生正确答案的文档,而第三个术语用于从排名靠前的检索文档中删除不相关的项目。信息流示意图如下
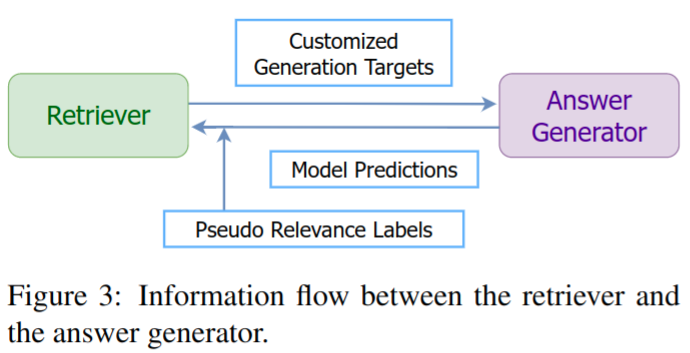
检索和生成在训练中相辅相成:伪相关性标签和模型预测为改进检索提供了积极和消极的信号,而改进的检索通过对 s k ∗ s_{k}^{*} sk∗ 的训练改进了答案生成(因为对每个检索到的 document 都生成了答案)
RA-VQA Generation
- 联合检索和生成的置信度确定最终答案
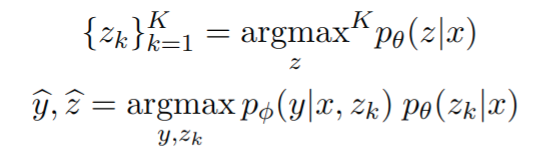
实验结果
实验配置
- 知识库选择用 corpus GS-full:包含 168,306 documents
- 知识库检索模型用 BERT-base
- 答案生成模型用 T5-large
- 本文方法的变种模型
- RA-VQA-NoDPR:完全省略检索,因此仅通过微调T5生成答案,即答案生成简化为
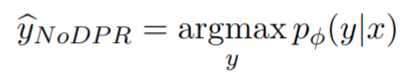
- RA-VQA-FrDPR:检索模型固定参数,只对答案生成模型进行 finetune
- RA-VQA-NoPR:文档检索模型仅使用模型预测进行训练,即正负样本定义修改为如下
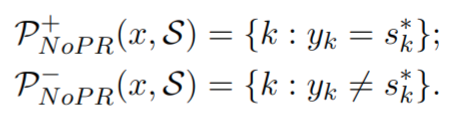
- RA-VQA-NoCT:gt 直接使用答案集中最 popular 的答案
- RA-VQA-NoDPR:完全省略检索,因此仅通过微调T5生成答案,即答案生成简化为
评价指标
- VQA Score:与 OK-VQA 数据集提出的指标一样
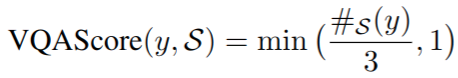
#S (y) 是标注 y 的标注员数目。这个分数确保了模型得到部分奖励,即使它从人类的反应中产生了一个不太受欢迎的答案 - Exact Match (EM):对人类标注的标签平等对待
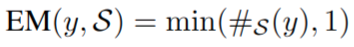
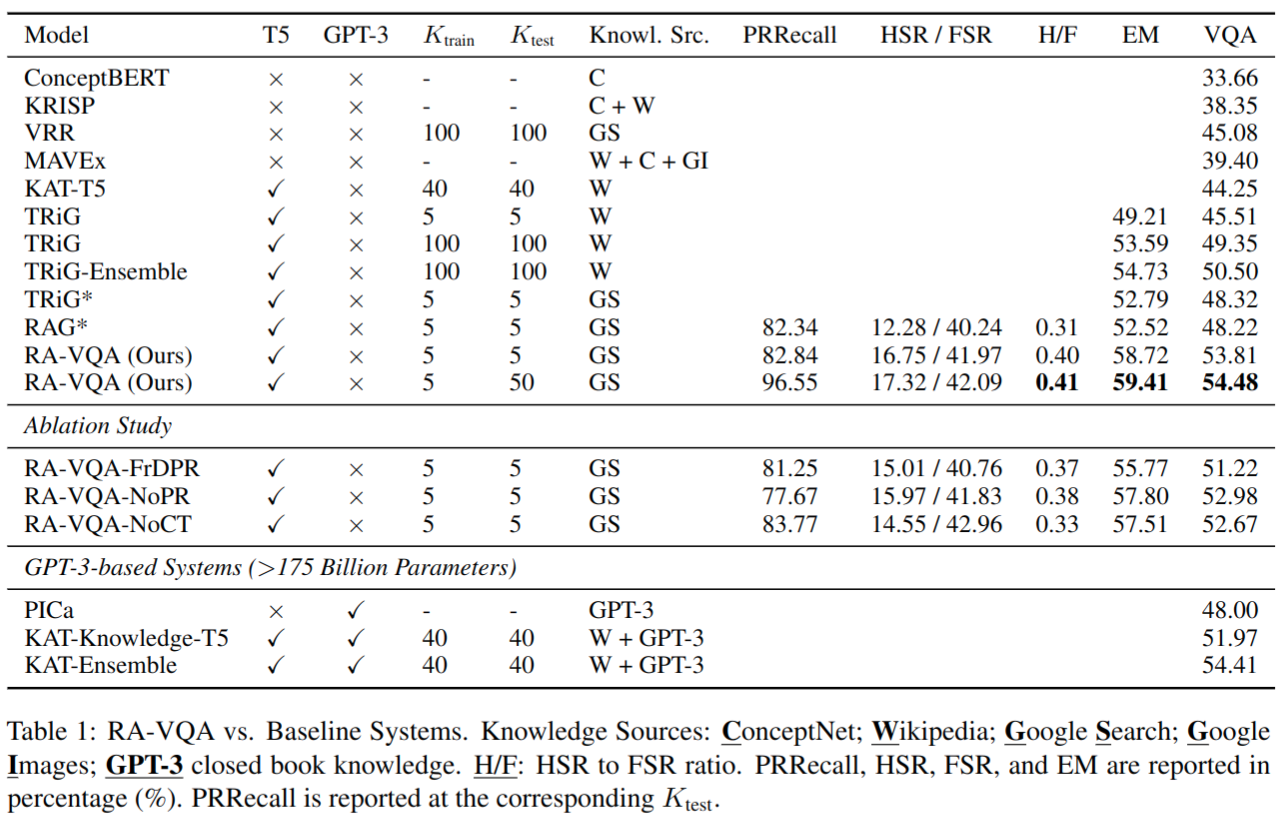
与 SOTA 对比
- 与类似的工作 TRiG 相比精度更高;与 KAT-T5 比也是有很大优势;与带 GPT-3 的 KAT 比精度差不多,不过 GPT-3 参数量大
Thoughts
- end-to-end 对文档检索模块和答案生成模块都进行联合训练看起来是很科学的,相比于类似计算量的 KAT-T5 优势很明显