强化学习(五):蒙特卡洛采样方法
在强化学习(四)中,我们学习了如何使用动态规划法求解强化学习问题,我们还学习了策略评估和策略改进,以及广义策略迭代(GPI),事实上,动态规划能够很好地收敛到最优值,但是否动态规划就是最好的呢?显然不是。
回顾一下动态规划的状态价值函数的贝尔曼方程:
如图,这是动态规划的状态价值函数迭代的图,可以发现,在计算每一个状态的价值函数时,都需要遍历所有可能的动作,以及这些动作能够转移的所有下一个状态,这是一个穷举的过程,而事实上,我们无法做到穷举所有动作,同时我们也无法或者已知的状态转移概率分布,因此动态规划是一种理想条件下的方法,也是一种基于模型(model-based)的方法。本文将引入蒙特卡洛方法。蒙特卡洛方法是通过平均样本的回报来解决强化学习问题,其通过多次采样来对潜在的搜索空间进行描述,使用均值来近似价值,这也称为动态规划的一个推广,本人也认为动态规划在某些意义上是一个特殊的蒙特卡洛。
蒙特卡洛是一种随机采样策略,通常意义上说,给定一个确定的策略 ,通过随机采样方式生成若干个采样序列,这些采样序列可以记做: 。我们知道对于一个强化学习的任务,其有两个设定,一个是分幕式设定,一个是折扣收益。本文所描述的蒙特卡洛也基于这两个设定。
1、蒙特卡洛评估
延续GPI的思想。蒙特卡洛方法也是策略评估(预测)和策略控制(改进)之间的相互迭代。在策略评估阶段,首先给定一个初始化固定的策略
,目标便是预测某状态的状态价值函数
,而对于某一个采样序列(幕),存在一些状态它们会被访问若干次,这在动态规划中是不会出现,但对于随机采样的序列是很大概率出现的,因此我们将蒙特卡洛方法其划分为两种:
(1)首次访问型(First-visit):只统计每个状态首次被访问时的状态价值。
(2)每次访问型(Every-visit):统计每个状态所有被访问后产生的状态价值。
一般来说,常用首次访问型方法,因为其可以比较快速的收敛,而对于每次访问型,因为同一个状态不同时间点不一定是独立的,虽然实验显示也会收敛,但速度会比较慢。
如图所示,首次访问型的蒙特卡洛预测算法:

算法的基本思路就是首先生成一系列采样序列,遍历每一个采样序列,从最后一时刻向后遍历状态,并将首次访问的状态统计起来,最后将所有采样序列的状态价值计算均值。其中“For each state s apperaing in the episode”表示的是状态
已出现在这个序列中,即只计算第一次出现在这个序列中对应的价值。另外这里一般采用增量式实现。增量式实现如下图所示:

增量式实现可以减少计算存储压力,因为考虑到一般会有几十万幕的任务,计算均值耗费时间和资源,采用增量式能够提高效率。
蒙特卡洛评估过程中,每个采样序列之间是相互独立的,因此对每一个采样序列中的每个状态估计也是相互独立的,因此对于蒙特卡洛方法,回溯图是一条直线,其中空心点表示状态,实心点表示状态动作二元组:

2、蒙特卡洛控制
GPI的思想是策略评估与策略控制的交叉执行,在蒙特卡洛方法中也如此。
我们仔细思考一个问题,在获得一系类采样序列后,我们使用评估算法来尽可能的在当前策略
下使得状态价值能够收敛,而在控制阶段,我们的目标则是选择一个最优动作。而蒙特卡洛方法因为其随机性,可能导致一个问题——有些状态可能一直没有被访问过,因此这里有三种解决策略:
(1)试探性出发:每一个状态动作二元组都有一定的概率被选作一个幕的起始点。这个假设能够直接保证每个状态动作都能被访问到,但应用场景很受限制;
(2)
贪心和UCB:我们在强化学习(二)也讲过这一类方法,其在每次策略控制阶段,都设置一定概率进行随机选择。基于这一类的策略也被称为同轨策略;
(3)重要度采样:重要度采样时一种通过额外的行动策略分布来尽可能的试探未知的状态动作,来预测目标策略。下面将会分别对着三个蒙特卡洛控制进行讲解。
2.1 基于试探性出发的蒙特卡洛控制
首先基于一个特定的策略
生成一个采样序列,而所有的(状态-动作)二元组都有一定的概率被选做这个采样序列的初始部分,详细的算法如下图所示:

首先,初始化相关变量,然后无限次循环每一个采样序列,采样序列的初始部分的(状态-动作)二元组都有一定概率被选中,其次从后向前依次累计各个状态的价值,并使用增量方法计算动作价值函数的期望值。这里依然也是基于首次访问型。
试探性出发能够解决部分状态动作二元组无法访问的问题,但其也存在另一个问题:一般而言,很多应用领域是不适合随机初始状态的,因此不能够适合所有场景。
2.2 基于软性策略的蒙特卡洛同轨策略控制
如果不使用基于试探性出发来实现,有没有别的方法呢?我们先介绍两个概念:
同轨策略(On-Policy): 当蒙特卡洛采样策略与目标优化策略一致时,我们称之为同轨策略。在同轨策略中,用于生成的采样数据序列的策略和用于实际决策的待评估和改进的策略是一样的。同轨策略也通常是一种“软性”策略,例如 贪心等;
离轨策略(Off-Policy): 当蒙特卡洛采样策略与目标优化策略不一致时,我们称之为离轨策略。在离轨策略中,用于评估或者改进的策略与生成采样的序列是不同的,用于生成的数据“离开”了待优化的策略所决策的序列轨迹
事实上,同轨策略和离轨策略也将是所有基于采样方法的主要分类依据,因此我们先介绍同轨策略的一种方法—— 贪心(软性策略)。
贪心指在策略控制阶段的某一个时刻状态 的概率随机选择一个动作 ,而有 的概率选择当前价值最高的动作 。因此对于非价值最高的动作来说,都有 的概率被选中,而价值最高的动作则有 的概率被选中,因此每个动作被选中的概率均大于等于 ,可以保证试探与开发之间的权衡。下图给出相关算法:

首先初始化变量,以及软性策略
,其中
表示所有的动作数量,循环每一幕,根据这个策略生成一个采样序列,并基于首次访问型来统计每个(状态-动作)二元组的价值函数Q,并进行增量平均(这一部分则是策略评估)。其次先获取当前策略最优的动作
,然后随机初始化一个动作
并使得有
的概率使得
,有
概率使得
。
事实上,这个软性策略可以保证 收敛到一个最优解,此处证明只引入Sutton书中的内容:


2.3 基于重要度采样的蒙特卡洛离轨策略控制
基于同轨的策略实际上是一种妥协,并不能学习到最优的动作,而基于离轨策略则可以学习到最终的最优策略。上面讲过,离轨策略是指用于评估或者改进的目标策略与具有试探性的行动策略不相同,换句话说,就是用行动策略
去做试探性的采样,基于行动策略来改进目标策略
。因此我们有如下的条件:
(1)目标策略
下发生的动作都至少偶尔能在
下发生。因为基于行动策略我们能够观察到的采样序列,但这个采样序列并不是我们学习和改进的目标策略生成的,因此我们必须保证目标策略能够发生的动作,行动策略也要能够发生,才能使得这个行动策略体现出试探性。形式化的描述即为
且
。
(2)重要度采样建立两种不同分布之间的关系。 重要度采样指在给定某个来自其他分布的条件下,估计某种分布的期望值的方法。例如给定行动策略
,这是一个满足
策略的条件概率分布,我们希望用它来估计目标策略
的概率分布。重要度采样比是一种相对概率,其用来表示两种分布之间的相对关系。我们可以使用这个比值来将目标策略的期望
转移到行动策略的期望。公式如下:
其中 则是重要度采样比。在蒙特卡洛方法中,这个采样比我们可以使用在这两个策略下产生的采样序列的概率比值来表示:
事实上,重要度采样就是每个时刻策略分布的比值之积。有了这个内容,我们就可以根据对行动策略的采样序列来估计目标策略的价值,首先定义一下相关变量:
(1)
:表示从时刻
开始一直到一幕的结束,当前状态的重要度采样比;
(2)
:状态s所处的幕序列的终止时间;
(3)
:表示状态
在每一幕中首次出现的位置的集合
(4)
:表示遵循行动策略
在当前状态
的回报;
(5)
:表示估计的目标策略
在当前时刻
的价值。
例如如图所示有三幕按照时间依次排列,时间序列则一起排序,其中状态
在三幕中分别为时刻2,7,所以
,而其中时刻3所处的幕的终止时刻为
。

- 普通重要度采样(平均重要度采样):
- 加权重要度采样:
二者主要区别在于分母不同。
例如例题无穷方差,其只有一个状态和两个动作,向左则有0.1的概率终止当前一幕,有0.9的概率回到这个状态,而向右则直接终止当前幕。如图所示:
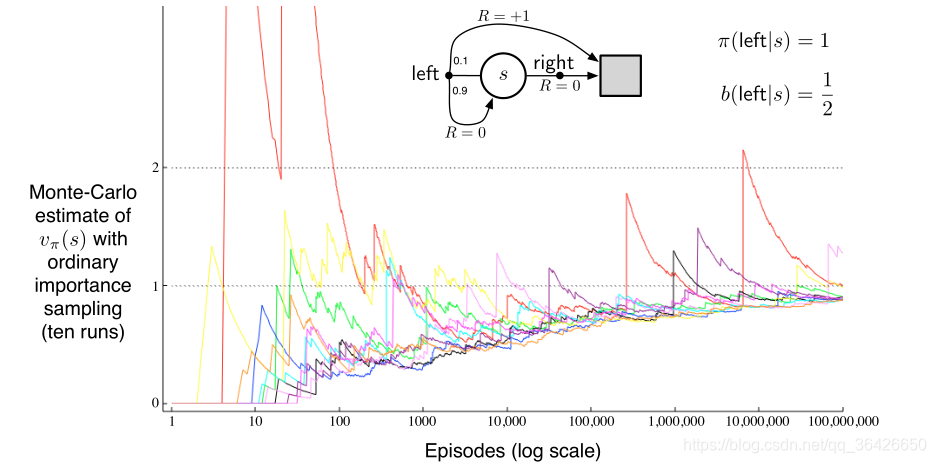
行动策略
对于两个方向的动作都有0.5的概率,当使用基于普通重要度采样时其不能保证
收敛到预期的结果
,而基于加权重要度采样则可以收敛。
下面给出基于重要度采样的蒙特卡洛离轨预测算法:

在该算法中,需要注意的是其采用增量式计算行动策略
的价值期望
,并不断更新重要度采样比
并求行动策略的
值。结束条件表示当且仅当目标策略的概率分布为0时(即表示在当前状态下没有动作可以执行时)。
基于重要度采样的蒙特卡洛离轨控制算法:

这里与上面一致,不过需要注意的是最后一行更新公式
,其次终止条件为
表示行动策略的动作与基于当前重要度采样估计的目标策略的最优策略对应的动作不相等时,退出当前幕循环。
3、总结
蒙特卡洛方法很好的解决了动态规划无法事先知道状态转移等先验分布的问题,通过对采样序列的价值期望来预测价值也能保证收敛。因此蒙特卡洛有三大优势:
(1)符合实际的经历和应用场景;
(2)可以从模拟中进行学习;
(3)每一幕采样相互独立;
个人对MC收敛性有个简单的理解:如果说动态规划是一个非常理想化的内容,MC则是介于实际和理想化之间的一个过渡,上节课证明了DP的收敛性,可以推广,DP是一个对状态动作空间全部采样的一个特殊的MC,或者说是MC是DP的“子集”,如果MC能够执行几百万几千万次采样(绝大多数的MC例子都是很多次采样),结合贪心策略或重要度采样等方法,姑且可以认为可以达到DP的境界。但是,事实上,MC的收敛性并不是一个简单的MDP收敛问题,它还受到如何选择策略影响的,例如在有些时候,同样的算法,如果基于加权重要度采样可以收敛,但基于普通重要度采样就不会收敛,因此探讨MC收敛性不是那么简单的一件事情。
另外MC有个很强的假设——分幕式假设,这个在书的一开始就限定了,试想一下,像下棋可以认为是分幕式任务,每一幕是一局,每个采样序列就是落子,但是有的任务不满足这个设定,有些任务甚至是无限的(例如),所以MC在此就完全不可用;另外MC的一个弊端就是它必须遍历整个序列才能得到每个状态的价值期望,这很显然造成计算负担并不实用,,现如今一些强化学习系统也并不直接使用MC,就好比在关联规则数据挖掘里面,实际应用并不会去使用Apriori算法。
