分类目录:《深入理解强化学习》总目录
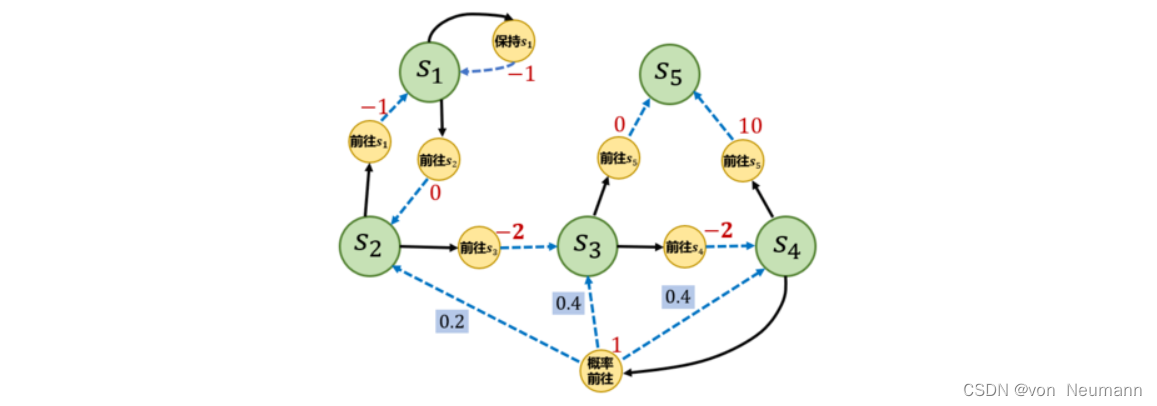
在文章《深入理解强化学习——马尔可夫决策过程:蒙特卡洛方法-[基础知识]》中我们介绍了利用蒙特卡洛方法计算马尔可夫决策过程价值的方法,本文将用代码定义一个采样函数。采样函数需要遵守状态转移矩阵和相应的策略,每次将(s,a,r,s_next)元组放入序列中,直到到达终止序列。然后我们通过该函数,用随机策略在下图的马尔可夫决策过程中随机采样几条序列。
def sample(MDP, Pi, timestep_max, number):
''' 采样函数,策略Pi,限制最长时间步timestep_max,总共采样序列数number '''
S, A, P, R, gamma = MDP
episodes = []
for _ in range(number):
episode = []
timestep = 0
s = S[np.random.randint(4)] # 随机选择一个除s5以外的状态s作为起点
# 当前状态为终止状态或者时间步太长时,一次采样结束
while s != "s5" and timestep <= timestep_max:
timestep += 1
rand, temp = np.random.rand(), 0
# 在状态s下根据策略选择动作
for a_opt in A:
temp += Pi.get(join(s, a_opt), 0)
if temp > rand:
a = a_opt
r = R.get(join(s, a), 0)
break
rand, temp = np.random.rand(), 0
# 根据状态转移概率得到下一个状态s_next
for s_opt in S:
temp += P.get(join(join(s, a), s_opt), 0)
if temp > rand:
s_next = s_opt
break
episode.append((s, a, r, s_next)) # 把(s,a,r,s_next)元组放入序列中
s = s_next # s_next变成当前状态,开始接下来的循环
episodes.append(episode)
return episodes
# 采样5次,每个序列最长不超过20步
episodes = sample(MDP, Pi_1, 20, 5)
print('第一条序列\n', episodes[0])
print('第二条序列\n', episodes[1])
print('第五条序列\n', episodes[4])
输出:
第一条序列
[('s1', '前往s2', 0, 's2'), ('s2', '前往s3', -2, 's3'), ('s3', '前往s5', 0, 's5')]
第二条序列
[('s4', '概率前往', 1, 's4'), ('s4', '前往s5', 10, 's5')]
第五条序列
[('s2', '前往s3', -2, 's3'), ('s3', '前往s4', -2, 's4'), ('s4', '前往s5', 10, 's5')]
紧接着,我们就可以对所有采样序列计算所有状态的价值:
def MC(episodes, V, N, gamma):
for episode in episodes:
G = 0
for i in range(len(episode) - 1, -1, -1): #一个序列从后往前计算
(s, a, r, s_next) = episode[i]
G = r + gamma * G
N[s] = N[s] + 1
V[s] = V[s] + (G - V[s]) / N[s]
timestep_max = 20
# 采样1000次,可以自行修改
episodes = sample(MDP, Pi_1, timestep_max, 1000)
gamma = 0.5
V = {
"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0}
N = {
"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0}
MC(episodes, V, N, gamma)
print("使用蒙特卡洛方法计算MDP的状态价值为\n", V)
输出:
使用蒙特卡洛方法计算MDP的状态价值为
{
's1': -1.228923788722258, 's2': -1.6955696284402704, 's3': 0.4823809701532294, 's4': 5.967514743019431, 's5': 0}
可以看到用蒙特卡洛方法估计得到的状态价值和我们用马尔科夫奖励过程解析解得到的状态价值是很接近的。这得益于我们采样了比较多的序列,感兴趣的读者可以尝试修改采样次数,然后观察蒙特卡洛方法的结果。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022