第五章:蒙特卡洛方法
和前几章讲的不一样,蒙特卡洛方法不需要对环境进行完全的建模,而只需要经验,也就是实际或者仿真的与环境进行交互的整个样本序列,包括状态动作和反馈信息。从实际交互中学习并不需要对环境建模,而从仿真交互中学习也只需要能够产生相应的转移样本而不是完整的环境状态转移概率分布。而且很多的例子中产生相应的交互例子很容易,得到概率分布却很难。
蒙特卡洛方法采用平均样本反馈的方法来解决强化学习问题。为了保证得到定义好的reward值,我们只在episodic tasks上使用蒙特卡洛方法。也就是假设每个任务都能分为一个个episode,每个episode结束以后才进行值更新和策略的改进。因此蒙特卡洛法是以一个episode为单位来计算,而不是以每一步(online)来计算。
和第二章的bandit问题类似,蒙特卡洛法用的也是为每个状态或者状态动作对平均反馈的方式。但是在这个方法中有很多个状态,而且不同状态之间相互联系,同时每个动作的选择都在学习中,因此这个问题是非稳态且是associative search的。
为了解决这种非稳态,我们使用了第四章介绍的GPI框架。也就是在样本反馈中计算值函数,同时对策略进行改进最终达到最优。
5.1 Monte Carlo Prediction
首先考虑在给定策略下估计状态值函数的问题。状态的值是从该状态开始之后得到反馈的期望,一个简单的计算方式就是将从该状态开始的反馈值加起来求平均。随着计算次数增加,最终平均值会逼近期望值。这个想法在蒙特卡洛法中一直得到应用。
假设给定了一堆在策略下经过状态s的序列样本,我们想要评估在策略
下状态s的值函数
。每次转移到状态s都叫做对s的一次访问(visit)。s有可能在样本中被访问多次,因此我们把第一次访问s的时间叫做对s的first-vist。首次访问蒙特卡洛法(first-visit MC method)把第一次访问状态s后得到的反馈值进行平均,而每次访问蒙特卡洛法(every-visit MC method)是把所有访问s后的反馈值进行平均。随着访问次数趋近于无穷,这两种方法的估计值都会收敛至目标值。

练习5.1 因为最后两步停止了要牌不会爆掉而且点数很大容易获胜。 前面一直在要牌,容易爆掉。 在没有11点的牌但是却总点数大于12的情况下继续要牌更容易爆。
练习5.2 不会,因为每个状态只会经过一次。
DP方法需要完全了解环境建模,而且需要知道采取动作之后下一个状态的转移分布,但是有的问题中很难去产生下一状态的概率分布。因此即使对于有环境建模的问题,蒙特卡洛方法只需要生成状态序列的做法也是一个很大的优点。
对于蒙特卡洛方法来说,它的backup diagrams会是一条直线。因为每一个序列的状态轨迹都只有所有可能的其中一条,因此它的backup diagrams是从根节点状态开始,采取一个动作转移到一个状态一直到结束状态。而不像是DP算法中把所有的可能性都考虑到。
关于蒙特卡洛法估计值函数的另一个重要特点是,这个方法对每个状态值的估计是独立的。换句话说,蒙特卡洛法并没有使用bootstrap。
而且蒙特卡洛法估计每一个单个的状态值的时候,计算复杂性和整个状态的数量无关。所以对于只关注某几个状态的时候蒙特卡洛法特别实用,这是蒙特卡洛法对比DP法的第三个优点。
5.2 Monte Carlo Estimation of Action Values
如果没有对环境的建模,那么评估状态动作值函数相对于状态值函数就会更有效。如果有了环境模型,那么只需要状态值函数就可以得到一个贪心策略,但是如果没有环境模型,只有状态值函数是做不到确定一个贪心策略的。因此我们的目标是估计,使用的是policy evaluation方法。
对于评估状态动作值函数来说,计算方法和上节讲的类似,只不过是把遍历每个状态改为遍历每个状态动作对。只不过这里存在一个问题,那就是直接这么评估状态动作对,可能会导致有的状态动作对永远不会被访问。但是为了选择最好的动作,我们需要变量当前状态所有的动作,而不只是当前选择的动作。这就是之前第二章提到的保持explore的问题,为了解决这个问题有一个方法叫做exploring starts。这个方法是以一个状态动作对作为交互的开始,而每一个状态动作对都有可能作为开始,之后才遵循策略
。只要episode的次数足够多,那么最终会让状态动作值函数达到收敛。
exploring starts的方法有时候有用但不值得依赖。最好的方法是保证在一个每个状态的每一个动作都有非0概率选择到的策略下进行采样。
练习5.3 同样是一条线。
5.3 Monte Carlo Control
现在考虑用蒙特卡洛法用在control中,也就是逼近最优策略。依然采用的是DP算法中提出的GPI的想法。其中policy evaluation使用的是前两节讲的方法。首先假设问题中有无限多个数量的episode而且都是使用exploring starts的方法。policy improvement是通过让策略保持与当前状态动作值保持贪心。也就是:
每次进行policy improvement都让下一个策略作为以
为基础的贪心策略。Policy Improvement Theorem会保证最终策略收敛至最优策略。蒙特卡洛方法通过这样的方式做到了在没有环境建模的情况下收敛至最优策略和最优值函数。为了保证收敛我们做了两个假设,一是保证每个episode都是用exploring starts开始,二是保证每次policy evaluation都能在有限步后计算完成。
为了让算法更通用,现在需要拿掉这两个假设。这里只考虑拿掉假设二。假设二中利用了为值函数的变化设置上限的方式。也就是两次值函数之间的变化小于一个上限后即认为计算完成。只要变化上限设置的足够小,那么就能够保证值函数能够正确收敛。第二种拿掉假设二的方法就是我们不必在每次policy improvement之前都完全计算完成policy evaluation。value iteration就是一个例子。
对于蒙特卡洛方法而言,每次episode之后进行一次policy evaluation和一次policy improvement是很自然的。有一个很简单的方法就是遵循这个方式,叫做Monte Carlo ES。

练习5.4 存储一个访问次数N并每次更新,然后把Q的计算改为增量式。
在Monte Carlo ES中,无论是遵循什么策略,算法对每次产生的状态动作对的反馈都进行了平均。也就是说算法最终一定会收敛到最优策略,因为只有达到最优时策略才会稳定不变。
5.4 Monte Carlo Control without Exploring Starts
接下来考虑使用Monte Carlo Control的第一个假设,也就是假设使用exploring starts。解决的办法就只有考虑能够遍历所有可能的状态动作对。有两种情况,一种是on-policy的情况,另一种是off-policy。on-policy是指当前正在被evaluate和improvement的策略就是用来做决策的策略,而off-policy是指指导决策的策略与正在被评估改进的策略不是同一个策略。对于on-policy的问题就只能够选择评估和改进soft的策略。soft的意思是指在每个状态s,采取每个动作a的概率都大于0,但是策略需要慢慢地接近最优的贪心策略。比如之前讨论过的-greedy算法就是一种soft的策略。在所有
-soft的策略中,
-greedy算法是最接近最优的贪心算法的。
on-policy的蒙特卡洛控制依然是使用GPI的框架。没有了exploring starts的设计就没法直接在改进策略的时候选择贪心的动作,但是GPI框架不要求策略必须是一个贪心策略,只需要这个策略越来越接近贪心最优的策略即可。在我们的算法中,将策略最终改进至一个-greedy的策略。

policy improvement theorem保证算法最终得到的策略是所有的-soft算法中效果最好的。实际上算法保证了每一步都会得到一个更好的策略,直到算法达到最优。而且这个过程不依赖状态动作值函数在每一步是如何计算出来的,不过依赖于计算结果的正确性。虽然我们只取得了所有
-soft策略中的最优策略,但是我们成功拿掉了ES的假设。
5.5 Off-policy Prediction via Importance Sampling
所有的强化学习控制过程面临一个困境:算法既要通过执行最优动作来学习动作值,但是有需要执行非最优的动作来遍历所有的动作。有个很直接的方法是使用两个策略,一个用来决策当前动作,而另一个被进行评估和改进。正在被评估和改进的叫做目标策略,决定执行动作的叫做行为策略。这个过程叫做off-policy学习。
这本书接下来的部分on-policy和off-policy都会考虑。首先考虑简单点的on-policy算法。off-policy算法一般会有更大的方差而且更难收敛。但是off-policy会应用更广泛且更厉害,因为on-policy可以认为是一种目标策略和行为策略相同的off-policy的算法。
首先考虑对off-policy情况下的策略进行估计。假设有一个目标策略和一个行为策略b,两个策略不相同但是都是固定不变的。我们假设策略
中所有动作选择的可能都要在b中也可能被选择到,这个假设叫做收敛假设。根据这个假设,在b与
不一样的时候,b的选择一定是随机的。而策略
往往是确定性的。
几乎所有的off-policy都会用到一个叫做importance sampling的技术将一个分布中得到的采样用来评估另一个采样的期望值。这个技术是根据状态变化的轨迹发生在目标策略和行为策略中的相对概率来加权平均反馈值。这个相对概率叫做Importance-Sampling ratio。假设从时间t开始在一个策略下得到一个序列
,那么这个序列发生的概率为:
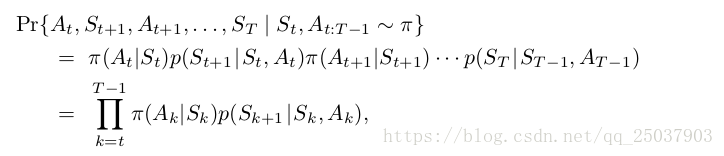
其中p是环境的状态转移分布概率。而这个轨迹序列在目标策略和行为策略中的相对概率为:
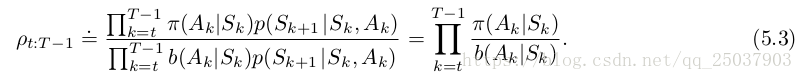
因为我们想要得到目标策略的值函数,但是根据动作策略做动作得到的是动作策略的值函数采样,使用了Importance Sampling ratio进行修正之后就可以得到目标策略的期望, 即。
假设不同episode时间下标统一,然后使用表示所有第一次访问状态s的时间步集合。那么我们根据平均值很容易得到目标策略的状态值函数
,这种计算方式叫做ordinary importance sampling。还有另外一种求和的方式是使用相对概率系数进行加权求和,即
,这种方式叫做weighted importance sampling。
对于只有一个观察值的时候,加权求和的结果是这个观察值本身。所以这个方法的值函数期望是而不是
,因此统计上是有偏估计。相反的是不加权求和的结果期望是无偏的,但是它有可能很极端,也就是方差会很大。特别是有些情况比如轨迹序列本身和目标策略产生的序列很接近,但是相对概率是10,这样就可能远离期望的结果。正式的说就是,ordinary importance sampling的期望是无偏的,但是方差是有可能没有上限的因为相对比值是没有上限的。相反weighted importance sampling的方法期望是有偏的但是方差会逐渐趋近于0,即使比例有可能是无穷大。所以在实际应用中一般会选择weighted importance sampling。不过ordinary 的方法很容易用到近似算法中,第二部分会讲到。
不过对于every-visit的算法,这两种估计算法都是有偏的但是方差都会收敛到0。但是实际中还是使用every-visit更多,因为这样不需要记录某个状态是否被访问过。
练习5.5 10 5
练习5.6
练习5.7 ordinary 方差一开始就会很明显的体现,weighted方法可能刚开始的时候前几个例子的方差恰好不明显。
练习5.8 依然会无限大 因为使用every-visit方法后每一项的方差更大,加起来也就更大。
5.6 Incremental Implementation
使用第二章讲的增量式的方法也可以把蒙特卡洛预测法改写成增量式的形式。对于on-policy来说和第二章讲的方法没有区别,可以直接使用。对于off-policy而言可能需要区分ordinary方法和weighted方法。不过对于ordinary方法来说改动也很小,只是把每次增量的部分改为使用相对概率系数修正后的版本即可。
对于weighted求和的off-policy的方法,需要进行一些不同的改变。假设我们有一个状态开始的很多个返回值序列并且对应每个都有一个相对概率系数
。那么该状态的值函数估计定义为
。为了得到增量式的形式就必须计算每次的系数和,则增量形式写为:

这个算法本身是为off-policy下使用weighted求和准备的,但是使用on-policy算法也可以使用,只需要把系数都写为1。

练习5.9 略 5.10 略
5.7 Off-policy Monte Carlo Control
现在考虑第二种形式的蒙特卡洛控制算法,也就是off-policy形式的控制算法。off-policy分为目标策略和行为策略两个策略,分开的其中一个好处是目标策略可以使确定性的,而行为策略可以不断地采样所有可能的算法。策略无关的蒙特卡洛控制算法利用了前两节讲到的off-policy求值函数的方法,这个方法要求行为策略在每个状态执行每个动作的概率都大于0,因此行为策略需要是-soft的。
下面的图片中展示了算法的伪代码,算法基于GPI框架和weighted importance sampling用来逼近最优策略和最优动作状态值函数
。其中
是根据Q值得到的最优贪婪策略。Q是
的估计值。其中行为策略可以是任意策略,但是需要满足能够遍历所有状态动作对的要求。使用soft策略即可。策略
会在所有访问过的状态上逼近最优策略,而且在这期间行为策略b可以是变化的,即使是在一个episode中间变化。

这个算法有个潜在的问题。算法每次都是在一个episode的结尾进行更新,episode中所有的动作都是greedy的。如果里面的动作有一些不是贪婪的,那么训练可能会变得很慢。目前还不清楚这个问题的严重性,不过使用下面的TD算法可以解决。
练习5.11 因为目标策略是确定性的,因为分子永远是1。
5.10 Summary
这章讲述了从episode的采样中学习值函数和最优策略的蒙特卡洛方法。这个方法相比DP算法有三个优点:一、可以直接通过与环境的交互来进行学习而不需要建模。二、可以通过仿真或者采样模型进行学习。三、可以很容易地只关注其中一些状态的值函数。 可能还有第四个优点那就是蒙特卡洛算法不使用bootstrap。
在设计蒙特卡洛算法时使用了GPI框架,也就是一边policy evaluation一边policy improvement的方法让值和策略都逼近最优。蒙特卡洛方法不需要知道环境的状态转移概率分布,因此需要关注状态动作值函数的估计。蒙特卡洛方法把PE和PI在一次episode结束之后进行交替进行,而且可以写为增量形式。
保持足够的探索是蒙特卡洛控制需要考虑的。exploring starts的算法在仿真的时候可能有用,但实际应用的时候不太合适。另外的解决方案,在on-policy上是需要使策略一直是soft的,在off-policy上可以使用一个soft的行为函数而评估一个确定性的目标函数。
off-policy prediction是指在一个不同于目标策略的动作策略下评估行为策略的值函数。可以使用Importance Sampling的方法来把行为策略的反馈转化为目标策略的反馈。ordinary importance sampling算法使用简单的加权反馈的平均,而weighted importance Sampling使用的是加权反馈的加权平均。ordinary方法方差大但是无偏,weighted法方差是有限的但是有偏,不过实际中常用weighted法。另外off-policy算法仍然有一个未解决的难题。
本章的蒙特卡洛算法和DP算法主要有两个不同,一个是MC算法是从经验采样中直接学习不需要环境模型。二是MC算法不使用bootstrap。两个特点相关但是也可以分开。