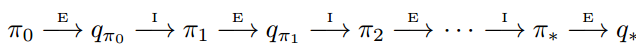这一章我们考虑第一种同时估计值函数和找到最优策略的学习方法。和之前不同,我们不再假设已知环境模型(这是实际中最可能的情况),蒙特卡洛(Monte Carlo, MC)方法只需要和真实/仿真环境交互的经验(state, action, reward)就行了。从仿真环境中学习也是非常有价值的,此时我们只需要状态转移就行(transitions, s, r, s’),很多时候这是容易的,但是很难获得四参数形式的环境概率模型。
MC方法是基于样本returns均值的,因此我们只考虑episodic任务,因为我们需要对在多个episodes中出现的s的returns取平均。只有在完整的episode结束后,才能用MC方法估计值函数和提升策略,因此MC方法是episode-by-episode的,而不是step-by-step(online)的。
MC方法采样并平均每个state-action对,类似于我们在multi-armed bandits中的做法,但是这里将有多个状态(associative or contextual),因此每个state-action对的值与后续状态及策略有关,而因为我们可能不断在提升策略,因此本章讨论的问题也是nonstationary的。
MC方法是基于GPI的,但与DP不同,我们是利用和环境交互的样本来学习值函数的,然后在此基础上提升策略。类似地,我们也先讨论prediction问题,然后讨论策略提升问题,最后讨论基于GPI的control问题。
我们考虑通过MC方法学习一个给定策略的state-value函数(回忆下,state-value是从当前状态开始的期望累积未来折扣回报(expected return))。很自然地,我们会考虑利用
G
t
,
i
(
s
)
G_{t, i}(s)
G t , i ( s )
我们根据策略
π
\pi
π
两种MC都能收敛到
v
π
(
s
)
v_\pi(s)
v π ( s )
G
t
,
i
(
s
)
G_{t, i}(s)
G t , i ( s )
1
/
n
1/\sqrt{n}
1 / n
example 5.1 Blackjack
A
(
s
)
∈
{
h
i
t
s
,
s
t
i
c
k
s
}
A(s)\in \{hits, sticks\}
A ( s ) ∈ { h i t s , s t i c k s }
在example 5.1中,虽然我们有任务的完整模型,但是我们还是无法应用DP方法,因为计算
p
(
r
,
s
′
∣
s
,
a
)
p(r,s'|s,a)
p ( r , s ′ ∣ s , a )
我们可以画出MC方法的backup diagram。
MC方法的backup diagram实际是一条从开始到终止的轨迹,只用samples更新,而DP方法则需要在每个状态上考虑所有的后续状态,且只包含one-step transitions。且MC独立地估计每个值,而DP是bootstrapping的,并不独立。
MC方法的优势:
单个状态的值估计的计算代价与状态数量之间独立,因此可以只处理我们感兴趣的状态;
可以从实际经验和仿真经验中学习;
不需要完整的环境模型;
无偏。
example 5.2 Soap Bubble
如果我们没有四参数模型
p
(
r
,
s
′
∣
s
,
a
)
p(r,s'|s,a)
p ( r , s ′ ∣ s , a )
max
a
∑
s
′
,
r
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
v
∗
(
s
′
)
]
\max\limits_a\sum_{s',r}p(s',r|s,a)[r+ \gamma v_*(s')]
a max ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ v ∗ ( s ′ ) ]
因此我们必须评估action value函数
q
π
(
s
,
a
)
q_\pi(s, a)
q π ( s , a )
通过MC方法估计动作值函数,估值量会上升到
∣
S
∣
∗
∣
A
∣
|S|*|A|
∣ S ∣ ∗ ∣ A ∣
π
\pi
π
exploring starts:指定从某个(s, a)开始,保证以所有的state-action对开端的概率不为0,后面再按照策略选择和计算。这在和实际环境交互学习时无用,且可能会组合爆炸;
采用随机策略保证每个(s,a)都有出现的概率(ε-greedy也是可行的)。
本章后面的讨论暂时假定采用exploring starts的方式。
control指得到最优策略的过程。后面我们把值函数估计都叫做prediction,策略提升叫做improvement,把prediction与improvement的配合叫做control。类似于DP,我们也从GPI(参见上一章)出发。回顾上一章的内容,GPI的过程为:
MC评估值函数需要多个完整的episodes,因此如上图,首先从初始策略
π
0
\pi_0
π 0
q
k
(
s
,
a
)
q_k(s, a)
q k ( s , a )
π
k
+
1
(
s
)
≐
arg
max
a
q
(
s
,
a
)
\pi_{k+1}(s) \doteq \arg \max_a q(s,a)
π k + 1 ( s ) ≐ arg max a q ( s , a )
q
π
k
(
s
,
π
k
+
1
(
s
)
)
=
q
π
k
(
s
,
arg
max
a
q
π
k
(
s
,
a
)
)
=
max
a
q
π
k
(
s
,
a
)
≥
q
π
k
(
s
,
π
k
(
s
)
)
≥
v
π
k
(
s
)
\begin{aligned} q_{\pi_k} (s, \pi_{k+1}(s)) &= q_{\pi_k}(s, \arg \max_a q_{\pi_k}(s,a)) \\ &= \max_a q_{\pi_k}(s,a) \\ & \geq q_{\pi_k}(s, \pi_k(s)) \\ & \geq v_{\pi_k}(s) \end{aligned}
q π k ( s , π k + 1 ( s ) ) = q π k ( s , arg a max q π k ( s , a ) ) = a max q π k ( s , a ) ≥ q π k ( s , π k ( s ) ) ≥ v π k ( s )
上述推导中,应该留意最后一步为什么成立。这是因为如果策略是soft的,那么
v
v
v
q
(
s
,
π
k
)
q(s, \pi_k)
q ( s , π k )
因而满足上一章介绍的策略提升定理。因此可见,MC方法不需要环境模型就能找到最优策略。
但是这其中有两个要求:任务可以进行无限多的episodes;并且结合exploring starts保证探索性。显然这两个假设都不太现实。为了得到一个实际可行的策略,我们必须去掉这两个假设。我们先来解决第二个假设,第一个假设留到下一小节,有两种解决办法,这两种方法都是参考自DP的policy iteration与value iteration的:
类似policy iteration中的方法,保证每次估计误差(更新量)在一定范围内就行;
放弃准确估计值函数,类似value iteration中的方法,只让值函数向着真值前进一小步,就开始提升策略。这应该比第一种效率更高。
这两种办法的有效性由GPI保证。第二种方法如果按照episode-by-episode执行,就是每个episode进行一次Bellman最优迭代更新,则算法称为:MC with Exploring Starts,MCES。
关于算法的几个注意事项:
这是first-visit的,因此unless那句的含义是,只有在
S
0
,
A
0
,
.
.
.
,
S
t
−
1
,
A
t
−
1
S_0, A_0, ..., S_{t-1}, A_{t-1}
S 0 , A 0 , . . . , S t − 1 , A t − 1
S
t
,
A
t
S_t, A_t
S t , A t
该算法可以容易地改成迭代的形式,这样就不必为了求均值保存所有的returns了。
第一/二章中我们说明了非平稳过程问题(本算法就是,因为策略一直在变化),我们应该更信任最近的returns,而上述算法中是直接平均的,但是当算法循环无穷episodes时,前面不准确returns的影响会被稀释掉,因此也能达到全局最优。这个全局最优不动点看起来一定会达到,但是到现在为止却还没有完全证明。
example 5.3 Solving Blackjack
如何避免MCES的exploring starts假设呢?只要保证能无限地持续选中它们就行了,有两种策略:on-policy 和off-policy 。on-policy指产生样本的策略(behavior policy)和被估计的策略(target policy)是同一个策略,而off-policy则指behavior policy与target policy不同。MCES可以基于on-policy扩展,从而不依赖exploring starts,也可以根据off-policy扩展。我们这一节讨论on-policy情形。
on-policy去除exploring starts的方法是:保证每个状态下所有动作的被选概率都不为0(soft-policy),即
π
(
a
∣
s
)
>
0
\pi(a|s) > 0
π ( a ∣ s ) > 0
ϵ
−
g
r
e
e
d
y
\epsilon-greedy
ϵ − g r e e d y
1
−
ϵ
+
ϵ
∣
A
(
s
)
∣
1-\epsilon+\frac{\epsilon}{|A(s)|}
1 − ϵ + ∣ A ( s ) ∣ ϵ
ϵ
∣
A
(
s
)
∣
\frac{\epsilon}{|A(s)|}
∣ A ( s ) ∣ ϵ
ϵ
−
g
r
e
e
d
y
\epsilon-greedy
ϵ − g r e e d y
ϵ
−
s
o
f
t
\epsilon-soft
ϵ − s o f t
ϵ
−
s
o
f
t
\epsilon-soft
ϵ − s o f t
π
(
a
∣
s
)
≥
ε
∣
A
(
s
)
∣
\pi(a|s) \geq \frac{\varepsilon}{|\mathcal{A}(s)|}
π ( a ∣ s ) ≥ ∣ A ( s ) ∣ ε
soft-policy,
ϵ
−
s
o
f
t
\epsilon-soft
ϵ − s o f t
ϵ
−
g
r
e
e
d
y
\epsilon-greedy
ϵ − g r e e d y
基于on-policy的不需要exploring starts的first-visit MC方法,也是在GPI框架下的。基于GPI和ε-greedy,我们最终能得到一个还不错的策略,我们可以让
ϵ
\epsilon
ϵ
注意算法中初始化策略为任意
ϵ
−
s
o
f
t
\epsilon-soft
ϵ − s o f t
ϵ
−
g
r
e
e
d
y
\epsilon-greedy
ϵ − g r e e d y ?这里证明一下:
v
π
′
(
s
)
=
∑
a
π
′
(
a
∣
s
)
q
π
(
s
,
a
)
=
ε
∣
A
(
s
)
∣
∑
a
q
π
(
s
,
a
)
+
(
1
−
ε
)
max
a
q
π
(
s
,
a
)
≥
ε
∣
A
(
s
)
∣
∑
a
q
π
(
s
,
a
)
+
(
1
−
ε
)
∑
a
π
(
a
∣
s
)
−
ε
∣
A
(
s
)
∣
1
−
ε
q
π
(
s
,
a
)
=
ε
∣
A
(
s
)
∣
∑
a
q
π
(
s
,
a
)
−
ε
∣
A
(
s
)
∣
∑
a
q
π
(
s
,
a
)
+
∑
a
π
(
a
∣
s
)
q
π
(
s
,
a
)
=
v
π
(
s
)
\begin{aligned} v_{{\pi}'}(s) &= \sum_a \pi'(a|s) q_\pi (s,a) \\ &= \frac{\varepsilon}{|\mathcal{A}(s)|} \sum_a q_\pi (s,a) + (1-\varepsilon) \color{red} { \max_a q_\pi (s,a) } \\ & \geq \frac{\varepsilon}{|\mathcal{A}(s)|} \sum_a q_\pi (s,a) + (1-\varepsilon) \color{red} {\sum_a \frac{\pi(a|s) - \frac{\varepsilon}{|\mathcal{A}(s)|}}{1 - \varepsilon} q_\pi (s,a) } \\ &= \frac{\varepsilon}{|\mathcal{A}(s)|} \sum_a q_\pi (s,a) - \frac{\varepsilon}{|\mathcal{A}(s)|} \sum_a q_\pi (s,a) + \sum_a \pi(a|s) q_\pi(s,a) \\ &= v_\pi(s) \end{aligned}
v π ′ ( s ) = a ∑ π ′ ( a ∣ s ) q π ( s , a ) = ∣ A ( s ) ∣ ε a ∑ q π ( s , a ) + ( 1 − ε ) a max q π ( s , a ) ≥ ∣ A ( s ) ∣ ε a ∑ q π ( s , a ) + ( 1 − ε ) a ∑ 1 − ε π ( a ∣ s ) − ∣ A ( s ) ∣ ε q π ( s , a ) = ∣ A ( s ) ∣ ε a ∑ q π ( s , a ) − ∣ A ( s ) ∣ ε a ∑ q π ( s , a ) + a ∑ π ( a ∣ s ) q π ( s , a ) = v π ( s )
其中,不等号那一行之所以成立,是因为:
∑
a
π
(
a
∣
s
)
−
ε
∣
A
(
s
)
∣
1
−
ε
=
1
1
−
ε
[
∑
a
π
(
a
∣
s
)
−
∑
a
ε
∣
A
(
s
)
∣
]
=
1
1
−
ε
[
1
−
ε
]
=
1
\color{red} {\sum_a \frac{\pi(a|s) - \frac{\varepsilon}{|\mathcal{A}(s)|}}{1 - \varepsilon}} = \frac{1}{1 - \varepsilon} \left[ \sum_a \pi(a|s) - \sum_a \frac{\varepsilon}{|\mathcal{A}(s)|} \right] = \frac{1}{1 - \varepsilon}[1 - \varepsilon] =1
∑ a 1 − ε π ( a ∣ s ) − ∣ A ( s ) ∣ ε = 1 − ε 1 [ ∑ a π ( a ∣ s ) − ∑ a ∣ A ( s ) ∣ ε ] = 1 − ε 1 [ 1 − ε ] = 1
这相当于对
q
π
(
s
,
a
)
q_\pi(s, a)
q π ( s , a )
π
(
a
∣
s
)
−
ϵ
∣
A
(
s
)
∣
1
−
ϵ
≥
0
\frac{\pi(a|s)-\frac{\epsilon}{|A(s)|}}{1-\epsilon}\geq0
1 − ϵ π ( a ∣ s ) − ∣ A ( s ) ∣ ϵ ≥ 0
max
a
q
π
(
s
,
a
)
\max\limits_aq_\pi(s,a)
a max q π ( s , a )
因而策略得到了改善。
我们可以换一种角度理解上述内容。我们把
ϵ
−
s
o
f
t
\epsilon-soft
ϵ − s o f t
v
~
∗
\widetilde{v}_*
v
∗
q
~
∗
\widetilde{q}_*
q
∗
在旧环境中,当
ϵ
−
s
o
f
t
\epsilon-soft
ϵ − s o f t
也就是,在旧环境中通过
ϵ
−
s
o
f
t
\epsilon-soft
ϵ − s o f t
v
~
∗
\widetilde{v}_*
v
∗
v
π
v_\pi
v π
这种角度实际上说明了policy iteration在ε-soft策略下也是work的。且能收敛到soft下的最优。通过这样的方式,就可以去掉exploring starts的假设了,虽然只达到了ε-soft下的最优策略。
所有的学习控制方法都面临一个困境:计算最优值函数需要按照最优动作运行,但是为了找到最优动作又需要探索非当前最优策略。那么能不能在保证探索的同时还能得到最优值函数呢?on-policy是妥协的方案,只找到了次优的值函数,这里我们介绍off-policy方法:同时采用两个策略,一个叫做target policy,这是被学习的最优策略,它是确定性的;一个叫behavior policy,这是产生行为的策略,它是soft的。
on-policy原理上比较简单;off-policy则稍微复杂,且具有更大的方差和更慢的收敛速度,但是off-policy更通用和有力,实际上,on-policy是target=behavior的off-policy特殊形式。此外,off-policy还可以利用专家经验数据与非学习控制器,且是学习多步预测世界模型的关键。
我们用
π
\pi
π
b
b
b
b
b
b
π
\pi
π
π
\pi
π
b
b
b
π
(
a
∣
s
)
>
0
\pi(a|s)>0
π ( a ∣ s ) > 0
b
(
a
∣
s
)
>
0
b(a|s)>0
b ( a ∣ s ) > 0
b
b
b
π
\pi
π
off-policy基于重要性采样(importance sampling),即通过一个分布的样本估计另一个分布的期望值。利用target和behavior策略轨迹的相对概率加权returns。这叫做重要性采样比率(importance-sampling ratio)。给定一个起始状态
S
t
S_t
S t
π
\pi
π
A
t
,
S
t
+
1
,
A
t
+
1
,
.
.
.
,
S
T
A_t, S_{t+1}, A_{t+1}, ..., S_T
A t , S t + 1 , A t + 1 , . . . , S T
P
r
{
A
t
,
S
t
+
1
,
A
t
+
1
,
…
,
S
T
∣
S
t
,
A
t
:
T
−
1
∼
π
}
=
π
(
A
t
∣
S
t
)
p
(
S
t
+
1
∣
S
t
,
A
t
)
π
(
A
t
+
1
∣
S
t
+
1
)
⋯
p
(
S
T
∣
S
T
−
1
,
A
T
−
1
)
=
∏
k
=
t
T
−
1
π
(
A
k
∣
S
k
)
p
(
S
k
+
1
∣
S
k
,
A
k
)
Pr \{ A_t, S_{t+1}, A_{t+1}, \dots, S_T | S_t, A_{t:T-1} \sim \pi \} \\ = \pi(A_t| S_t) p(S_{t+1} | S_t, A_t) \color{red} {\pi(A_{t+1 } |S_{t+1})} \cdots p(S_T | S_{T-1}, A_{T-1}) \\ = \prod_{k=t} ^ {T-1} \pi(A_k | S_k) p(S_{k+1}|S_k, A_k)
P r { A t , S t + 1 , A t + 1 , … , S T ∣ S t , A t : T − 1 ∼ π } = π ( A t ∣ S t ) p ( S t + 1 ∣ S t , A t ) π ( A t + 1 ∣ S t + 1 ) ⋯ p ( S T ∣ S T − 1 , A T − 1 ) = ∏ k = t T − 1 π ( A k ∣ S k ) p ( S k + 1 ∣ S k , A k )
因此,我们就能得到behavior policy和target policy各自产生这条轨迹之概率的比值,该比值就是重要性采样比率,且该比率与MDP联合条件概率无关(也就是不依赖模型),只与两个策略有关:
ρ
t
:
T
−
1
≐
∏
k
=
t
T
−
1
π
(
A
k
∣
S
k
)
p
(
S
k
+
1
∣
S
k
,
A
k
)
∏
k
=
t
T
−
1
b
(
A
k
∣
S
k
)
p
(
S
k
+
1
∣
S
k
,
A
k
)
=
∏
k
=
t
T
−
1
π
(
A
k
∣
S
k
)
b
(
A
k
∣
S
k
)
\rho_{t:T-1} \doteq \frac{\prod_{k=t}^{T-1} \pi(A_k | S_k) p(S_{k+1}|S_k, A_k)} {\prod_{k=t}^{T-1} b(A_k | S_k) p(S_{k+1}|S_k, A_k)} = \prod_{k=t}^{T-1} \frac{\pi(A_k|S_k)}{b(A_k|S_k)}
ρ t : T − 1 ≐ ∏ k = t T − 1 b ( A k ∣ S k ) p ( S k + 1 ∣ S k , A k ) ∏ k = t T − 1 π ( A k ∣ S k ) p ( S k + 1 ∣ S k , A k ) = ∏ k = t T − 1 b ( A k ∣ S k ) π ( A k ∣ S k )
我们根据behavior policy得到样本,因此计算出的
G
t
G_t
G t
ρ
t
:
T
−
1
G
t
\rho_{t:T-1} G_t
ρ t : T − 1 G t
E
[
ρ
t
:
T
−
1
G
t
∣
S
t
=
s
]
=
v
π
(
s
)
\mathbb{E}[\rho_{t:T-1} G_t | S_t =s ] = v_\pi (s)
E [ ρ t : T − 1 G t ∣ S t = s ] = v π ( s )
接下来我们给出off-policy的MC算法。为了简便,我们打通episodes,例如,第一个episode的step编号是1~100,那么第二个episode的step号就从101开始。我们用
J
(
s
)
J(s)
J ( s )
T
(
t
)
T(t)
T ( t )
G
t
G_t
G t
t
t
t
T
(
t
)
T(t)
T ( t )
{
G
t
}
t
∈
J
(
s
)
\{G_t\}_{t \in J(s)}
{ G t } t ∈ J ( s )
{
ρ
t
:
T
(
t
)
−
1
}
t
∈
J
(
s
)
\{\rho_{t:T(t)-1}\}_{t \in J(s)}
{ ρ t : T ( t ) − 1 } t ∈ J ( s )
v
π
(
s
)
v_\pi(s)
v π ( s )
ordinary importance sampling:
v
π
(
s
)
≐
∑
t
∈
J
(
s
)
ρ
t
:
T
(
t
)
−
1
G
t
∣
J
(
s
)
∣
v_\pi(s) \doteq \frac {\sum_{t \in \mathcal{J}(s)} \rho_{t:T(t)-1} G_t} {|\mathcal{J}(s)|}
v π ( s ) ≐ ∣ J ( s ) ∣ ∑ t ∈ J ( s ) ρ t : T ( t ) − 1 G t
weighted importance sampling:
v
π
(
s
)
≐
∑
t
∈
J
(
s
)
ρ
t
:
T
(
t
)
−
1
G
t
∑
t
∈
J
(
s
)
ρ
t
:
T
(
t
)
−
1
v_\pi(s) \doteq \frac {\sum_{t \in \mathcal{J}(s)} \rho_{t:T(t)-1} G_t} {\sum_{t \in \mathcal{J}(s)} \rho_{t:T(t)-1}}
v π ( s ) ≐ ∑ t ∈ J ( s ) ρ t : T ( t ) − 1 ∑ t ∈ J ( s ) ρ t : T ( t ) − 1 G t
我们介绍下这两种方法的区别:直观看,ordinary是无偏的,weighted是有偏的(渐进无偏,可以直观理解,当episodes数目趋近于
∞
\infty
∞
∣
J
(
s
)
∣
=
∑
t
∈
J
(
s
)
ρ
t
:
T
(
t
)
−
1
|J(s)|=\sum_{t\in J(s)}\rho_{t:T(t)-1}
∣ J ( s ) ∣ = ∑ t ∈ J ( s ) ρ t : T ( t ) − 1
ρ
t
:
T
(
t
)
−
1
\rho_{t:T(t)-1}
ρ t : T ( t ) − 1
ρ
t
:
T
(
t
)
−
1
\rho_{t:T(t)-1}
ρ t : T ( t ) − 1
V
b
V_b
V b
这两种方法的区别在于方差和偏差。对于方差,显然ordinary方法是无界的,但是weighted方法是有界的,加权因子最大不超过1,实际上weighted的方差是收敛到0的,即使重要性采样比率无界;对于偏差,ordinary无偏,weighted方法渐进无偏。因此,我们往往倾向于weighted方法,但是ordinary方法更容易扩展到函数拟合的方法族中。
注意,对于every-visit情形,两种方法都是有偏的,但是都渐进收敛到0。every-visit是更常用的,这样就不需要记录每个状态的轨迹,且更容易扩展到拟合器的方法族。
example 5.4
example 5.5 Infinite Variance
γ
\gamma
γ
v
π
(
s
)
=
1
v_\pi(s)=1
v π ( s ) = 1
V
a
r
[
ρ
t
:
T
−
1
G
t
∣
S
t
=
s
]
=
∞
Var[\rho_{t:T-1} G_t | S_t =s ] = \infty
V a r [ ρ t : T − 1 G t ∣ S t = s ] = ∞
首先给出方差的展开式:
Var
[
X
]
≐
E
[
(
X
−
X
‾
)
2
]
=
E
[
X
2
−
2
X
X
‾
+
X
‾
2
]
=
E
[
X
2
]
−
X
‾
2
\operatorname{Var}[X] \doteq \mathbb{E}\left[(X-\overline{X})^{2}\right]=\mathbb{E}\left[X^{2}-2 X \overline{X}+\overline{X}^{2}\right]=\mathbb{E}\left[X^{2}\right]-\overline{X}^{2}
V a r [ X ] ≐ E [ ( X − X ) 2 ] = E [ X 2 − 2 X X + X 2 ] = E [ X 2 ] − X 2
我们把
X
X
X
ρ
t
:
T
−
1
G
t
\rho_{t:T-1} G_t
ρ t : T − 1 G t
E
b
[
X
]
=
E
b
[
∏
t
=
0
T
−
1
π
(
A
t
∣
S
t
)
b
(
A
t
∣
S
t
)
G
0
]
=
1
2
⋅
0.1
⋅
(
1
0.5
)
+
1
2
⋅
0.9
⋅
1
2
⋅
0.1
⋅
(
1
0.5
)
2
+
.
.
.
=
0.1
+
0.1
⋅
0.9
+
.
.
.
+
0.1
⋅
0.9
⋅
0.9
+
.
.
.
=
0.1
⋅
∑
k
=
0
∞
0.
9
k
=
1.0
\begin{aligned}\mathbb{E}_{b}[X]&=\mathbb{E}_{b}\left[\prod_{t=0}^{T-1} \frac{\pi\left(A_{t} | S_{t}\right)}{b\left(A_{t} | S_{t}\right)} G_{0}\right]\\&=\frac{1}{2}\cdot0.1\cdot(\frac{1}{0.5})+\frac{1}{2}\cdot0.9\cdot\frac{1}{2}\cdot0.1\cdot(\frac{1}{0.5})^2+...\\&=0.1+0.1\cdot0.9+...+0.1\cdot0.9\cdot0.9+...\\&=0.1\cdot\sum\limits_{k=0}^{\infty}0.9^k = 1.0\end{aligned}
E b [ X ] = E b [ t = 0 ∏ T − 1 b ( A t ∣ S t ) π ( A t ∣ S t ) G 0 ] = 2 1 ⋅ 0 . 1 ⋅ ( 0 . 5 1 ) + 2 1 ⋅ 0 . 9 ⋅ 2 1 ⋅ 0 . 1 ⋅ ( 0 . 5 1 ) 2 + . . . = 0 . 1 + 0 . 1 ⋅ 0 . 9 + . . . + 0 . 1 ⋅ 0 . 9 ⋅ 0 . 9 + . . . = 0 . 1 ⋅ k = 0 ∑ ∞ 0 . 9 k = 1 . 0
E
b
[
X
2
]
=
E
b
[
(
∏
t
=
0
T
−
1
π
(
A
t
∣
S
t
)
b
(
A
t
∣
S
t
)
G
0
)
2
]
=
1
2
⋅
0.1
⋅
(
(
1
0.5
)
)
2
+
1
2
⋅
0.9
⋅
1
2
⋅
0.1
⋅
(
(
1
0.5
)
2
)
2
+
.
.
.
=
0.1
∑
k
=
0
∞
0.
9
k
⋅
2
k
⋅
2
=
∞
\begin{aligned}\mathbb{E}_{b}[X^2]&=\mathbb{E}_{b}\left[\left(\prod_{t=0}^{T-1} \frac{\pi\left(A_{t} | S_{t}\right)}{b\left(A_{t} | S_{t}\right)} G_{0}\right)^2\right]\\&=\frac{1}{2}\cdot0.1\cdot((\frac{1}{0.5}))^2+\frac{1}{2}\cdot0.9\cdot\frac{1}{2}\cdot0.1\cdot((\frac{1}{0.5})^2)^2+...\\&=0.1\sum\limits_{k=0}^{\infty}0.9^k\cdot2^k\cdot2=\infty\end{aligned}
E b [ X 2 ] = E b ⎣ ⎡ ( t = 0 ∏ T − 1 b ( A t ∣ S t ) π ( A t ∣ S t ) G 0 ) 2 ⎦ ⎤ = 2 1 ⋅ 0 . 1 ⋅ ( ( 0 . 5 1 ) ) 2 + 2 1 ⋅ 0 . 9 ⋅ 2 1 ⋅ 0 . 1 ⋅ ( ( 0 . 5 1 ) 2 ) 2 + . . . = 0 . 1 k = 0 ∑ ∞ 0 . 9 k ⋅ 2 k ⋅ 2 = ∞
因此
Var
[
X
]
=
∞
\operatorname{Var}[X] = \infty
V a r [ X ] = ∞
MC方法增量地实现,类似第二章中的方法。在第二章中,我们计算rewards的均值,而这里我们计算returns的均值,但是它们都是类似的。我们这里分别讨论ordinary和weighted两种情形。
ordinary
R
i
R_i
R i
Q
n
+
1
=
Q
n
+
1
n
[
ρ
G
n
−
Q
n
]
Q_{n+1} = Q_n + \frac{1}{n} [\rho G_n - Q_n]
Q n + 1 = Q n + n 1 [ ρ G n − Q n ]
weighted
v
π
(
s
)
≐
∑
t
∈
J
(
s
)
ρ
t
:
T
(
t
)
−
1
G
t
∑
t
∈
J
(
s
)
ρ
t
:
T
(
t
)
−
1
v_\pi(s) \doteq \frac {\sum_{t \in \mathcal{J}(s)} \rho_{t:T(t)-1} G_t} {\sum_{t \in \mathcal{J}(s)} \rho_{t:T(t)-1}}
v π ( s ) ≐ ∑ t ∈ J ( s ) ρ t : T ( t ) − 1 ∑ t ∈ J ( s ) ρ t : T ( t ) − 1 G t
我们把加权因子简写为
W
k
W_k
W k
V
n
≐
∑
k
=
1
n
−
1
W
k
G
k
∑
k
=
1
n
−
1
W
k
V_n \doteq \frac{\sum_{k=1}^{n-1} W_k G_k}{\sum_{k=1}^{n-1} W_k}
V n ≐ ∑ k = 1 n − 1 W k ∑ k = 1 n − 1 W k G k
分母是一个求和,我们用
C
n
=
∑
i
=
1
n
W
i
C_n=\sum_{i=1}^nW_i
C n = ∑ i = 1 n W i
V
n
+
1
≐
V
n
+
W
n
C
n
[
G
n
−
V
n
]
V_{n+1} \doteq V_n + \frac{W_n}{C_n} [ G_n - V_n]
V n + 1 ≐ V n + C n W n [ G n − V n ]
C
n
+
1
=
C
n
+
W
n
+
1
C_{n+1} = C_n + W_{n+1}
C n + 1 = C n + W n + 1
proof:
V
n
+
W
n
C
n
[
G
n
−
V
n
]
=
(
1
−
W
n
C
n
)
V
n
+
W
n
C
n
G
n
=
C
n
−
W
n
C
n
∑
k
=
1
n
−
1
W
k
G
k
∑
k
=
1
n
−
1
W
k
+
W
n
G
n
C
n
=
C
n
−
1
C
n
∑
k
=
1
n
−
1
W
k
G
k
C
n
−
1
+
W
n
G
n
C
n
=
∑
k
−
1
n
W
k
G
k
C
n
=
V
n
+
1
\begin{aligned} V_n + \frac{W_n}{C_n}[G_n - V_n] &= (1 - \frac{W_n}{C_n})V_n + \frac{W_n}{C_n}G_n \\ &= \frac{C_n - W_n}{C_n} \frac{\sum_{k=1}^{n-1} W_k G_k}{\sum_{k=1}^{n-1} W_k} + \frac{W_n G_n}{C_n} \\ &= \frac{C_{n-1}}{C_n}\frac{\sum_{k=1}^{n-1} W_k G_k}{C_{n-1}} + \frac{W_n G_n}{C_n} \\ &= \frac{\sum_{k-1}^n W_k G_k}{C_n}\\ & = V_{n+1} \end{aligned}
V n + C n W n [ G n − V n ] = ( 1 − C n W n ) V n + C n W n G n = C n C n − W n ∑ k = 1 n − 1 W k ∑ k = 1 n − 1 W k G k + C n W n G n = C n C n − 1 C n − 1 ∑ k = 1 n − 1 W k G k + C n W n G n = C n ∑ k − 1 n W k G k = V n + 1
注意
C
0
≐
0
C_0\doteq0
C 0 ≐ 0
V
n
V_n
V n
C
n
C_n
C n
对于on-policy方法,behavior policy与target policy一致,因此
W
≡
1
W\equiv1
W ≡ 1
off-policy是本书介绍的第二种control方法。off-policy中用于产生行为的策略叫做behavior policy,被改进的策略叫做target policy,这两者分开的好处是:即使target policy是确定性的,behavior policy仍然能采样所有actions,因此bebavior policy应该是soft的。
我们仍然基于GPI构造算法,以估计
v
∗
v*
v ∗
q
∗
q*
q ∗
ϵ
−
s
o
f
t
\epsilon-soft
ϵ − s o f t
算法中标黄行的解释:因为
π
\pi
π
π
(
S
t
)
=
A
t
\pi(S_t)=A_t
π ( S t ) = A t
W
W
W
π
\pi
π
γ
<
1
\gamma<1
γ < 1
γ
<
1
\gamma<1
γ < 1
练习:Racetrack问题
之前对off-policy的重要性采样权重都是把returns当作整体看的,没有考虑returns的内部结构,这里利用这个结构降低off-policy估计的方差,这在
γ
<
1.0
\gamma<1.0
γ < 1 . 0
例如,考虑每个episode长100个steps,
γ
=
0
\gamma=0
γ = 0
G
0
=
R
1
G_0=R_1
G 0 = R 1
首先,我们引入部分累积回报(flat partial returns)的概念,h表示在第h步终结:
G
‾
t
:
h
≐
R
t
+
1
+
R
t
+
2
+
⋯
+
R
h
,
0
≤
t
<
h
≤
T
\overline{G}_{t : h} \doteq R_{t+1}+R_{t+2}+\cdots+R_{h}, \quad 0 \leq t<h \leq T
G t : h ≐ R t + 1 + R t + 2 + ⋯ + R h , 0 ≤ t < h ≤ T
注意这里没有折扣因子,这就是flat的含义,partial表示不计算到终结,只计算到horizon h。我们用折扣因子
γ
\gamma
γ
(
1
−
γ
)
(1-\gamma)
( 1 − γ )
γ
\gamma
γ
(
1
−
γ
)
⋅
γ
n
−
1
(1-\gamma)\cdot\gamma^{n-1}
( 1 − γ ) ⋅ γ n − 1
G
t
G_t
G t
G
t
≐
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
⋯
+
γ
T
−
t
−
1
R
T
=
(
1
−
γ
)
R
t
+
1
+
(
1
−
γ
)
γ
(
R
t
+
1
+
R
t
+
2
)
+
(
1
−
γ
)
γ
2
(
R
t
+
1
+
R
t
+
2
+
R
t
+
3
)
⋮
+
(
1
−
γ
)
γ
T
−
t
−
2
(
R
t
+
1
+
R
t
+
2
+
⋯
+
R
T
)
+
γ
T
−
t
−
1
(
R
t
+
1
+
R
t
+
2
+
⋯
+
R
T
)
=
(
1
−
γ
)
∑
h
=
t
+
1
T
−
1
γ
h
−
t
−
1
G
‾
t
:
h
+
γ
T
−
t
−
1
G
‾
t
:
T
\begin{aligned} G_{t} \doteq & R_{t+1}+\gamma R_{t+2}+\gamma^{2} R_{t+3}+\cdots+\gamma^{T-t-1} R_{T} \\=& (1-\gamma) R_{t+1} \\ &+(1-\gamma) \gamma\left(R_{t+1}+R_{t+2}\right) \\ &+(1-\gamma) \gamma^{2}\left(R_{t+1}+R_{t+2}+R_{t+3}\right) \\ & \vdots \\ &+(1-\gamma)\gamma^{T-t-2}\left(R_{t+1}+R_{t+2}+\cdots+R_{T}\right) \\ &+\gamma^{T-t-1}\left(R_{t+1}+R_{t+2}+\cdots+R_{T}\right) \\ &=(1-\gamma) \sum_{h=t+1}^{T-1} \gamma^{h-t-1} \overline{G}_{t:h}+\gamma^{T-t-1} \overline{G}_{t : T} \end{aligned}
G t ≐ = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ + γ T − t − 1 R T ( 1 − γ ) R t + 1 + ( 1 − γ ) γ ( R t + 1 + R t + 2 ) + ( 1 − γ ) γ 2 ( R t + 1 + R t + 2 + R t + 3 ) ⋮ + ( 1 − γ ) γ T − t − 2 ( R t + 1 + R t + 2 + ⋯ + R T ) + γ T − t − 1 ( R t + 1 + R t + 2 + ⋯ + R T ) = ( 1 − γ ) h = t + 1 ∑ T − 1 γ h − t − 1 G t : h + γ T − t − 1 G t : T
因为每一个
G
‾
t
:
h
\overline{G}_{t : h}
G t : h
ρ
t
:
h
−
1
\rho_{t:h-1}
ρ t : h − 1
ordinary:
V
(
s
)
≐
∑
t
∈
J
(
s
)
(
(
1
−
γ
)
∑
h
=
t
+
1
T
(
t
)
−
1
γ
h
−
t
−
1
ρ
t
:
h
−
1
G
‾
t
:
h
+
γ
T
(
t
)
−
t
−
1
ρ
t
:
T
(
t
)
−
1
G
‾
t
:
T
(
t
)
)
∣
J
(
s
)
∣
V(s) \doteq \frac{\sum_{t \in J(s)}\left((1-\gamma) \sum_{h=t+1}^{T(t)-1} \gamma^{h-t-1} \rho_{t : h-1} \overline{G}_{t : h}+\gamma^{T(t)-t-1} \rho_{t : T(t)-1} \overline{G}_{t : T(t)}\right)}{|J(s)|}
V ( s ) ≐ ∣ J ( s ) ∣ ∑ t ∈ J ( s ) ( ( 1 − γ ) ∑ h = t + 1 T ( t ) − 1 γ h − t − 1 ρ t : h − 1 G t : h + γ T ( t ) − t − 1 ρ t : T ( t ) − 1 G t : T ( t ) )
weighted:
V
(
s
)
≐
∑
t
∈
J
(
s
)
(
(
1
−
γ
)
∑
h
=
t
+
1
T
(
t
)
−
1
γ
h
−
t
−
1
ρ
t
:
h
−
1
G
‾
t
:
h
+
γ
T
(
t
)
−
t
−
1
ρ
t
:
T
(
t
)
−
1
G
‾
t
:
T
(
t
)
)
∑
t
∈
J
(
s
)
(
(
1
−
γ
)
∑
h
=
t
+
1
T
(
t
)
−
1
γ
h
−
t
−
1
ρ
t
:
h
−
1
+
γ
T
(
t
)
−
t
−
1
ρ
t
:
T
(
t
)
−
1
)
V(s) \doteq \frac{\sum_{t \in J(s)}\left((1-\gamma) \sum_{h=t+1}^{T(t)-1} \gamma^{h-t-1} \rho_{t : h-1} \overline{G}_{t : h}+\gamma^{T(t)-t-1} \rho_{t : T(t)-1} \overline{G}_{t : T(t)}\right)}{\sum_{t \in J(s)}\left((1-\gamma) \sum_{h=t+1}^{T(t)-1} \gamma^{h-t-1} \rho_{t : h-1}+\gamma^{T(t)-t-1} \rho_{t : T(t)-1}\right)}
V ( s ) ≐ ∑ t ∈ J ( s ) ( ( 1 − γ ) ∑ h = t + 1 T ( t ) − 1 γ h − t − 1 ρ t : h − 1 + γ T ( t ) − t − 1 ρ t : T ( t ) − 1 ) ∑ t ∈ J ( s ) ( ( 1 − γ ) ∑ h = t + 1 T ( t ) − 1 γ h − t − 1 ρ t : h − 1 G t : h + γ T ( t ) − t − 1 ρ t : T ( t ) − 1 G t : T ( t ) )
这两种估计叫做discounting-aware重要性采样估计。当
γ
=
1
\gamma=1
γ = 1
还有另外一种方式考虑off-policy重要性采样中return的结构,这种方式甚至可以减小
γ
=
1
\gamma=1
γ = 1
ρ
t
:
T
−
1
G
t
=
ρ
t
:
T
−
1
(
R
t
+
1
+
γ
R
t
+
2
+
⋯
+
γ
T
−
t
−
1
R
T
)
=
ρ
t
:
T
−
1
R
t
+
1
+
γ
ρ
t
:
T
−
1
R
t
+
2
+
⋯
+
γ
T
−
t
−
1
ρ
t
:
T
−
1
R
T
\begin{aligned} \rho_{t : T-1} G_{t} &=\rho_{t : T-1}\left(R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^{T-t-1} R_{T}\right) \\ &=\rho_{t : T-1} R_{t+1}+\gamma \rho_{t : T-1} R_{t+2}+\cdots+\gamma^{T-t-1} \rho_{t : T-1} R_{T} \end{aligned}
ρ t : T − 1 G t = ρ t : T − 1 ( R t + 1 + γ R t + 2 + ⋯ + γ T − t − 1 R T ) = ρ t : T − 1 R t + 1 + γ ρ t : T − 1 R t + 2 + ⋯ + γ T − t − 1 ρ t : T − 1 R T
对这个式子中的第一项,我们继续展开:
ρ
t
:
T
−
1
R
t
+
1
=
π
(
A
t
∣
S
t
)
b
(
A
t
∣
S
t
)
π
(
A
t
+
1
∣
S
t
+
1
)
b
(
A
t
+
1
∣
S
t
+
1
)
π
(
A
t
+
2
∣
S
t
+
2
)
b
(
A
t
+
2
∣
S
t
+
2
)
⋯
π
(
A
T
−
1
∣
S
T
−
1
)
b
(
A
T
−
1
∣
S
T
−
1
)
R
t
+
1
\rho_{t : T-1} R_{t+1}=\frac{\pi\left(A_{t} | S_{t}\right)}{b\left(A_{t} | S_{t}\right)} \frac{\pi\left(A_{t+1} | S_{t+1}\right)}{b\left(A_{t+1} | S_{t+1}\right)} \frac{\pi\left(A_{t+2} | S_{t+2}\right)}{b\left(A_{t+2} | S_{t+2}\right)} \cdots \frac{\pi\left(A_{T-1} | S_{T-1}\right)}{b\left(A_{T-1} | S_{T-1}\right)} R_{t+1}
ρ t : T − 1 R t + 1 = b ( A t ∣ S t ) π ( A t ∣ S t ) b ( A t + 1 ∣ S t + 1 ) π ( A t + 1 ∣ S t + 1 ) b ( A t + 2 ∣ S t + 2 ) π ( A t + 2 ∣ S t + 2 ) ⋯ b ( A T − 1 ∣ S T − 1 ) π ( A T − 1 ∣ S T − 1 ) R t + 1
式子中只有一个reward:
R
t
+
1
R_{t+1}
R t + 1
π
(
A
t
∣
S
t
)
b
(
A
t
∣
S
t
)
\frac{\pi(A_t|S_t)}{b(A_t|S_t)}
b ( A t ∣ S t ) π ( A t ∣ S t )
R
t
+
1
R_{t+1}
R t + 1
E
[
ρ
t
:
T
−
1
R
t
+
1
]
=
E
[
π
(
A
t
+
1
∣
S
t
+
1
)
b
(
A
t
+
1
∣
S
t
+
1
)
π
(
A
t
+
2
∣
S
t
+
2
)
b
(
A
t
+
2
∣
S
t
+
2
)
⋯
π
(
A
T
−
1
∣
S
T
−
1
)
b
(
A
T
−
1
∣
S
T
−
1
)
]
⋅
E
[
π
(
A
t
∣
S
t
)
b
(
A
t
∣
S
t
)
R
t
+
1
]
\begin{aligned}\mathbb{E}\left[\rho_{t : T-1} R_{t+1}\right]=& \mathbb{E}\left[\frac{\pi\left(A_{t+1} | S_{t+1}\right)}{b\left(A_{t+1} | S_{t+1}\right)} \frac{\pi\left(A_{t+2} | S_{t+2}\right)}{b\left(A_{t+2} | S_{t+2}\right)} \cdots \frac{\pi\left(A_{T-1} | S_{T-1}\right)}{b\left(A_{T-1} | S_{T-1}\right)}\right]\cdot\mathbb{E}\left[\frac{\pi(A_t|S_t)}{b(A_t|S_t)}R_{t+1}\right]\end{aligned}
E [ ρ t : T − 1 R t + 1 ] = E [ b ( A t + 1 ∣ S t + 1 ) π ( A t + 1 ∣ S t + 1 ) b ( A t + 2 ∣ S t + 2 ) π ( A t + 2 ∣ S t + 2 ) ⋯ b ( A T − 1 ∣ S T − 1 ) π ( A T − 1 ∣ S T − 1 ) ] ⋅ E [ b ( A t ∣ S t ) π ( A t ∣ S t ) R t + 1 ]
又因为:
E
[
π
(
A
k
∣
S
k
)
b
(
A
k
∣
S
k
)
]
≐
∑
a
b
(
a
∣
S
k
)
π
(
a
∣
S
k
)
b
(
a
∣
S
k
)
=
∑
a
π
(
a
∣
S
k
)
=
1
\mathbb{E}\left[\frac{\pi\left(A_{k} | S_{k}\right)}{b\left(A_{k} | S_{k}\right)}\right] \doteq \sum_{a} b\left(a | S_{k}\right) \frac{\pi\left(a | S_{k}\right)}{b\left(a | S_{k}\right)}=\sum_{a} \pi\left(a | S_{k}\right)=1
E [ b ( A k ∣ S k ) π ( A k ∣ S k ) ] ≐ ∑ a b ( a ∣ S k ) b ( a ∣ S k ) π ( a ∣ S k ) = ∑ a π ( a ∣ S k ) = 1
因而有:
E
[
ρ
t
:
T
−
1
R
t
+
1
]
=
E
[
ρ
t
:
t
R
t
+
1
]
\mathbb{E}\left[\rho_{t : T-1} R_{t+1}\right]=\mathbb{E}\left[\rho_{t : t} R_{t+1}\right]
E [ ρ t : T − 1 R t + 1 ] = E [ ρ t : t R t + 1 ]
对于scaled returns展开式的其它项,也有这样的结论:
E
[
ρ
t
:
T
−
1
R
t
+
k
]
=
E
[
ρ
t
:
t
+
k
−
1
R
t
+
k
]
\mathbb{E}\left[\rho_{t : T-1} R_{t+k}\right]=\mathbb{E}\left[\rho_{t : t+k-1} R_{t+k}\right]
E [ ρ t : T − 1 R t + k ] = E [ ρ t : t + k − 1 R t + k ]
综合起来,我们得到:
E
[
ρ
t
:
T
−
1
G
t
]
=
E
[
G
~
t
]
\mathbb{E}\left[\rho_{t : T-1} G_{t}\right]=\mathbb{E}\left[\tilde{G}_{t}\right]
E [ ρ t : T − 1 G t ] = E [ G ~ t ]
G
~
t
=
ρ
t
:
t
R
t
+
1
+
γ
ρ
t
:
t
+
1
R
t
+
2
+
γ
2
ρ
t
:
t
+
2
R
t
+
3
+
⋯
+
γ
T
−
t
−
1
ρ
t
:
T
−
1
R
T
\tilde{G}_{t}=\rho_{t : t} R_{t+1}+\gamma \rho_{t : t+1} R_{t+2}+\gamma^{2} \rho_{t : t+2} R_{t+3}+\cdots+\gamma^{T-t-1} \rho_{t : T-1} R_{T}
G ~ t = ρ t : t R t + 1 + γ ρ t : t + 1 R t + 2 + γ 2 ρ t : t + 2 R t + 3 + ⋯ + γ T − t − 1 ρ t : T − 1 R T
我们把这个想法叫做per-decision重要性采样。然后我们可以得到ordinary类型的估计公式:
V
(
s
)
≐
∑
t
∈
T
(
s
)
G
~
t
∣
J
(
s
)
∣
V(s) \doteq \frac{\sum_{t \in \mathcal{T}(s)} \tilde{G}_{t}}{|J(s)|}
V ( s ) ≐ ∣ J ( s ) ∣ ∑ t ∈ T ( s ) G ~ t
对于first-visit情况,该方法是无偏的。
MC直接从sample episodes中学习。MC相比于DP,有三个优势:可以直接从与环境的交互中学习最优行为,不需要模型;可以用在仿真或sample models中;可以高效地关注states的一个小子集,加速学习。此外,对不满足markov性的问题效果更好一些,因为不需要bootstrap。
MC是一种policy evaluation的方法,是无偏的,本章还讨论了episode-by-episode的基于MC的GPI,既可以是on-policy的,也可以是off-policy的,还可以增量实现。
MC的exploration性能不好,解决方法:每个episode从随机的state-action对开始,覆盖所有可能; 利用off-policy方法,可以用stocastic behavior学习确定的target policy。
off-policy预测是基于importance sampling的,包含ordinary importance sampling和weighted importance sampling,它们的特点:Ordinary importance sampling produces unbiased estimates, but has larger, possibly infinite, variance, whereas weighted importance sampling always has
MC prediction.
MC prediction of Action Values.
MC Control.
MCES - on policy.
off policy MC, importance sampling.
incremental implementation.
discounting aware.
per decision.
1 .https://zhuanlan.zhihu.com/c_1060499676423471104