会议:ICASSP 2019
论文:Streaming End-to-end Speech Recognition for Mobile Devices
作者:Yanzhang He, Tara N. Sainath, Rohit Prabhavalkar, Ian McGraw, Raziel Alvarez, Ding Zhao, David Rybach, Anjuli Kannan, Yonghui Wu, Ruoming Pang, Qiao Liang, Deepti Bhatia, Yuan Shangguan, Bo Li, Golan Pundak, Khe Chai Sim, Tom Bagby, Shuo-Yiin Chang, Kanishka Rao, Alexander Gruenstein
ABSTRACT
端到端(E2E)模型直接预测给定输入语音的输出字符序列,是设备语音识别的良好候选模型。然而,E2E模型提出了许多挑战:为了真正有用,这些模型必须实时地以流式方式解码语音;它们必须对用例的长尾具有健壮性;它们必须能够利用用户特定的上下文(例如,联系人列表);最重要的是,它们必须非常精确。在这项工作中,我们描述了我们的努力,建立一个E2E语音记录器使用递归神经网络传感器。在实验评估中,我们发现在许多评估类别中,所提出的方法在延迟和准确性方面都优于传统的基于CTC的模型。
CONCLUSIONS
我们提出了一种基于RNN-T模型的紧凑型E2E语音识别器的设计,它在Google像素手机上的运行速度是实时的两倍,在语音搜索和听写任务上比强大的嵌入式基线系统提高了20%以上的功耗。这是通过对RNN-T模型体系结构的一系列修改、量化推理和使用TTS为E2E模型合成训练数据来实现的。该系统具有流媒体、高精度、低延迟、上下文语音识别等特点,非常适合在设备上应用。
INTRODUCTION
在过去的十年中,深度神经网络的研究推动了自动语音识别(ASR)技术的巨大进步[1]。伴随着智能手机,平板电脑和其他消费类设备的迅猛发展和采用,这些改进已导致语音成为与此类设备进行交互的主要方式之一[2],[3]。在移动设备上识别语音的主要范例是将音频从设备流式传输到服务器,而将解码结果流式传输回用户。将这种基于服务器的系统替换为可以完全在设备上运行的系统从可靠性,延迟和隐私角度来看,它具有重要意义,并已成为研究的活跃领域。突出的示例包括唤醒词检测(即,识别特定的单词或短语)[4],[5],[6],[7],以及大词汇量连续语音识别(LVCSR)[8],[9]。
先前在设备上构建LVCSR系统的尝试通常包括缩小整个系统的传统组件(声学(AM),发音(PM)和语言(LM)模型)以满足计算和内存限制。虽然这可以实现语音命令和听写等狭窄域的准确性奇偶校验[9],但与诸如语音搜索之类的具有挑战性的任务的大型基于服务器的系统相比,性能明显较差。
与以前的方法相反,我们将重点放在基于端到端(E2E)模型[10],[11],[12],[13],[14]的最新进展来构建流系统。这种模型用一个直接预测字符序列的端到端训练有素的全神经模型代替了ASR系统的传统组件,从而大大简化了训练和推理。因此,端到端模型对于设备上的应用极为有吸引力。
早期的E2E工作使用字素或单词目标[16],[17],[18]和[19]来检查连接主义的时间分类(CTC)[15 ]。最近的工作表明,使用递归神经网络换能器(RNN-T)模型[12],[20],[21]或基于注意力的编解码器模型[10],[13]可以进一步提高性能。,[14],[22]。当在足够大量的声学训练数据上进行训练(10,000+小时)时,E2E模型的性能将优于传统的混合RNN-HMM系统[21],[14]。大多数E2E研究都集中于在产生假设之前处理全部输入话语的系统。如果需要流识别,则适合使用RNN-T [12],[20]等模型或基于流注意力的模型(例如MoChA [22])。因此,在这项工作中,我们基于RNN-T模型构建了流式E2E识别器。
在生产环境中在设备上运行端到端模型提出了许多挑战:首先,该模型至少需要与常规系统一样准确,而又不增加延迟(即,用户讲话与语音提示之间的延迟)。文字出现在萤幕上),因此在行动装置上的执行速度或快于即时;第二,该模型应该能够利用设备上的用户上下文(例如联系人列表,歌曲名称等)来提高识别准确性[23];最终,系统必须能够正确识别可能的话语的“长尾巴”,这对于训练有素的E2E系统直接在书面域中生成文本(例如,呼叫两个双四,三六,五→ 致电244-6665)。
为了实现这些目标,我们探索了对基本RNN-T模型的许多改进:使用层归一化[24]来稳定训练;使用大批量[25];使用单词目标[26];使用减少时间的层来加速训练和推理;量化网络参数以减少内存占用并加快计算速度[27]。为了使语境的识别,我们使用一个浅融合方法[28] ,[29] ,以向用户特定上下文偏压,这是我们发现是上面值与传统型号[9] ,[23]。最后,我们描述了vanilla E2E模型的基本局限性:当暴露于看不见的示例时,它们无法以正确的书面形式准确地对口语数字序列的归一化建模。我们通过训练使用文本转语音(TTS)系统生成的综合数据模型来解决此问题[30],该系统可将数字集的性能相对提高18-36%。综合起来,这些创新使我们能够在Google Pixel手机上以两倍于实时的速度解码语音,相对于传统的CTC嵌入式语音搜索和听写任务模型,其字错误率(WER)提高了20%以上。

RECURRENT NEURAL NETWORK TRANSDUCER
略~
两种模型的条件分布都通过神经网络进行参数化,如图1所示。给定输入功能,我们可以堆叠单向长短期存储器(LSTM)[31]层来构造编码器。对于CTC,编码器增加了一个最终的softmax层,该层将编码器输出转换为相关的条件概率分布。相反,RNN-T使用前馈联合网络,该网络接受来自编码器和仅依赖于标签历史的预测网络的结果作为输入。可以使用前后算法[12],[15],[20]计算训练两个模型所需的梯度。
REAL-TIME SPEECH RECOGNITION USING RNN-T
本节描述了各种体系结构和优化方面的改进,这些改进提高了RNN-T模型的准确性,并使我们能够在设备上运行模型的速度比实时运行的速度更快。
3.1. Model Architecture
为了在移动设备上实现高效处理,我们为RNN-T中的编码器和预测网络做出了许多架构设计选择。我们采用由八层单向LSTM单元组成的编码器网络[31]。我们在编码器的每个LSTM层之后添加一个投影层[32],从而减少了循环连接和输出连接的数量。
受[10],[33]的启发,我们还在编码器中添加了一个减少时间的层,以加快训练和推理的速度。略~将时间减少层应用于已经具有30ms输入帧速率的任何一个模型,都有不同的行为。具体来说,我们发现,它能够被插入低至没有精度RNN-T的任何损失的第二LSTM层之后,而将它添加到CTC音素模型(带有效输出帧速率≥ 60毫秒)精度劣化。
3.2. Training Optimizations
为了稳定循环层的隐藏状态动态,我们发现将层归一化[24]应用于编码器和预测网络中的每个LSTM层很有用。与[21]相似,我们使用词片子词单元[26]进行训练,该子词在我们的实验中胜过字素。我们利用有效的前向后向算法[25],该算法允许我们在张量处理单元(TPU)[34]上训练RNN-T模型。与使用GPU相比,这使我们能够以更大的批量进行更快的训练,从而提高了准确性。
3.3. Efficient Inference
最后,我们考虑了许多运行时优化以实现有效的设备上推断。首先,由于RNN-T中的预测网络类似于RNN语言模型,因此其计算与声学无关。因此,我们应用了RNN语言模型中使用的相同状态缓存技术,以避免针对相同的预测历史进行冗余计算。在我们的实验中,这可以节省50-60%的预测网络计算量。此外,我们为编码器和预测网络使用不同的线程,以实现通过异步进行流水线操作,以节省时间。我们进一步将编码器的执行划分为两个与时间减少层之前和之后的组件相对应的线程,这平衡了两个编码器组件与预测网络之间的计算。
3.4. Parameter Quantization
为了减少磁盘和运行时的内存消耗,并优化模型的执行以满足实时要求,我们将参数从32位浮点精度量化为8位定点,如前所述工作[9]。与[9]相比,我们现在使用一种更简单的量化方法,该方法是线性的(与以前一样),但是不再具有显式的“零点”偏移,因此假定值分布在浮点零附近。更具体地说,我们将量化向量x q定义为原始向量x和量化因子θ的乘积,其中
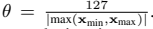
零点偏移的缺乏避免了在执行诸如乘法之类的运算之前必须以较低的精度应用它,从而加快了执行速度。请注意,我们强制量化范围为: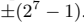
因此,对于典型的乘法累加运算,2个乘积的乘积之和始终严格小于15位,这使我们可以将多个运算进行到32位累加器中,从而进一步加快了推理速度。我们利用TensorFlow Lite优化工具和运行时在ARM和x86移动体系结构上执行模型[35]。在ARM体系结构上,与浮点执行相比,这实现了3 倍的加速。
CONTEXTUAL BIASING
上下文偏移应用或位置[23]。常规的ASR系统通过从偏置短语列表构建n-gram有限状态转换器(FST)来执行上下文偏置,该短语由解码过程中的解码器图动态组成[36]。这有助于将识别结果偏向上下文FST中包含的n-gram,从而在某些情况下提高了准确性。在E2E RNN-T模型中,我们使用类似于[36]的技术来计算偏差得分P C(y),并与基础模型P(y| x)在波束搜索期间使用浅融合[37]:
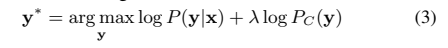
其中,λ是可调超参数,可控制上下文LM在波束搜索期间对整体模型得分产生多大影响。
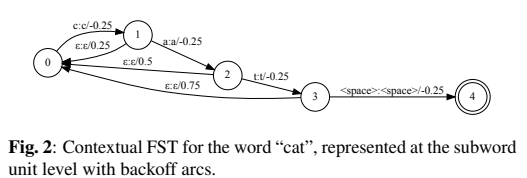
为了构造上下文LM,我们假设提前知道一组词级偏置短语,并将其编译为加权有限状态传感器(WFST)[38]。然后将此单词级WFST G左组合为“ speller” FST S,该词将一系列字素或单词片段转换为相应的单词,以获得上下文LM:C = min(det(S ○ G))。为了避免人为地提高早期匹配但不匹配整个短语的前缀,我们添加了一个特殊的失败弧,该弧删除了提升的分数,如图2所示。。最后,为了提高对专有名词的RNN-T性能(这对偏见至关重要),我们另外训练了500M无监督语音搜索语音(每个训练批次中80%的时间填充有监督数据,而20%的时间填充了无监督数据时间)[39]。非监督数据由我们的生产级识别器进行转录[40]并进行过滤,以仅包含专有名词来包含高置信度。请注意,使用此数据进行训练不会改变我们的语音搜索和听写测试集的结果,而只会提高表2中描述的上下文偏向结果的性能。
TEXT NORMALIZATION
常规模型中训练的口语域[41] ,[42] ,这允许它们看不见数字序列转换为写入域进行解码(例如,导航到两点二十单一的b贝克街导航到贝克街221B),其减轻在该→数据稀疏性问题。这是通过训练基于类的语言模型来完成的,其中使用ADDRESSNUM等类替换训练数据中的实际实例,并训练语法WFST,这些WFST通过手工制定的规则将这些类映射到所有可能的实例。在解码期间,识别器首先在口语域中输出假设,并在类标记中包含数字部分(二十二b </ addressnum>),然后通过手工制作的FST集将其转换为书面域规范化规则。
为了我们的目的,有可能训练E2E模型以输出口述域中的假设,然后使用神经网络[42]或基于FST的系统[41]将假设转换为书面域。为了使总体系统尺寸尽可能小,我们改为训练E2E模型以在书面域中直接输出假设(即,标准化为输出形式)。由于我们在训练中没有观察到足够多的包含数字序列的音频-文本对,因此我们生成了包含数字实体的500万语音集合。我们使用一种语音的串联TTS方法来合成这些数据[43] 创建音频文本对,然后将其扩充到我们的训练数据中(每个批次中有90%的时间填充有监督数据,而有10%的时间填充有合成数据)。
EXPERIMENTAL DETAILS
6.1. Data Sets
用于实验的训练集包括3500万英语发音(〜27,500小时)。培训话语是匿名的和手动转录的,代表了Google的语音搜索和听写流量。该数据集是通过使用室内模拟器人为破坏干净话音,添加不同程度的噪声和混响而创建的,从而使总SNR在0dB到30dB之间,平均SNR为12dB [44]。噪声源来自YouTube和日常生活中嘈杂的环境录音。我们报告结果的主要测试集包括从Google流量中提取的14.8K语音搜索(VS)语音以及15.7K的听写语音,我们将其称为IME测试集。
为了评估上下文偏向的性能,我们报告了4种语音命令测试集的性能,即歌曲(播放媒体的请求),Contacts-Real,Contacts-TTS(呼叫/文本联系人的请求)和Apps(与之交互的请求)一个应用程序)。通过创建网络中的歌曲,联系人或应用程序名称,然后综合上述每个类别中的TTS语音,可以创建除Contacts-Real外的所有集合。该联系人,真正集包含匿名和手工转录的话语来自谷歌的流量中提取。测试集中仅包含旨在与联系人进行交流的语音。然后将噪声人为地添加到TTS数据中,类似于上述过程[44]。
为了评估数字的性能,我们报告了一个真实数据数字集(Num-Real)的结果,该集合包含从Google流量中提取的匿名语音和手动转录语音。另外,我们还包括使用带有1个声音的并行Wavenet [30]的合成数字集(Num-TTS)的性能。第5节的TTS训练集中没有出现来自数字测试集的说话/成绩单。
6.2. Model Architecture Details
所有实验均使用80维log-Mel特征,并以25ms的窗口进行计算,并每10ms移动一次。与[40]相似,在当前帧t处,这些特征在左侧堆叠3帧并向下采样为30ms帧速率。编码器网络由8个LSTM层组成,其中每个层具有2,048个隐藏单元,然后是640维投影层。对于本文中的所有模型,我们都插入一个缩减因子为N的时间缩减层在第二层编码器之后= 2,可实现整体系统速度提高1.7×,而没有任何精度损失。预测网络是2个LSTM层,其中包含2,048个隐藏单元,每层640维投影。编码器和预测网络被馈送到具有640个隐藏单元的联合网络。联合网络被馈送到softmax层,其中包含76个单位(对于字素)或4,096个单位(对于词片[45])。RNN-T模型的总大小对于字素来说是117M个参数,对于单词来说是120M个参数。对于WPM,量化后的总大小为120MB。所有RNN-T模型都在Tensorflow [46]中的8×8 Tensor处理单元(TPU)切片上进行了训练,全局批量大小为4,096。
在这项工作中,我们将RNN-T模型与强大的基线常规CTC嵌入式模型进行了比较,该模型类似于[9],但更大。声学模型由具有6个LSTM层的CI-phone CTC模型组成,其中每个层具有1200个隐藏单元,其后是400维投影层,以及42个音素输出softmax层。该词典的词汇量为50万个单词。我们使用5克第一遍语言模型和小型高效的第二遍记录LSTM LM。量化后模型的整体大小为130MB,与RNN-T模型的大小相似。
RESULTS
7.1. Quality Improvements
表1概述了RNN-T模型质量的各种改进。首先,E 1显示层范数[24]有助于稳定训练,从而使VS和IME的WER相对提高6%。接下来,通过将RNN-T培训转移到TPU [25]并具有较大的批量,我们可以得到1-4%的相对改进。最后,将单位从字素转换为单词[21](E 3)显示出9%的相对改进。总的来说,我们的算法的变化分别示于VS和IME 27%和25%的相对改善与基线相比,常规CTC嵌入模型(乙0)。本文中进行的所有实验都将使用层范数,单词和TPU训练来报告结果(E 3)。

7.2. Contextual Biasing
表2显示了使用浅融合偏置机制的结果。我们仅使用监督数据(E 4)报告偏倚结果,还包括非监督数据(E 6)。我们还在B 1中显示了CTC常规模型的偏向性能。该表表明,除歌曲外,所有歌曲的E2E偏向性能均优于或与常规模型偏向相同,可能是因为歌曲中的出声率是1.0% ,高于通讯录(0.2%)或应用程序(0.5%)。

7.3. Text normalization
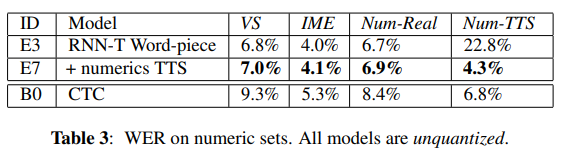
接下来,表3指出了基准RNN-T(E 3)单词模型在两个数字集上的性能。从表中可以看出,Num-TTS装置的WER 确实很高。进一步的错误分析显示,这是由于文本规范化错误引起的:例如,如果用户说出呼叫两个双三四…,则RNN-T模型假设2个双3 4而不是2334。要解决此问题,我们训练RNN -T模型具有更多的数字示例(E 7),如第5节所述,以VS和IME的较小退化为代价,从实质上缓解了此问题。但是,我们注意到,在所有集合上,这仍然比单独的基于FST的归一化器[9](B 0)优于基线系统。
7.4. Real Time Factor
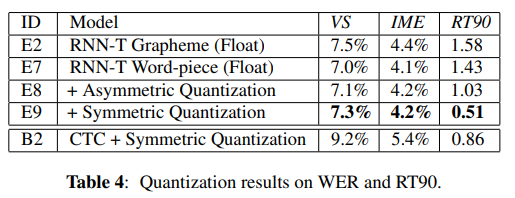
在表4中,我们报告了WER和RT90,即90%的实时因子(处理时间除以音频持续时间),其中较低的值表示处理速度更快,而用户感知的等待时间较短。比较E 2和E 7,我们可以看到RNN-T单词模型在准确性和速度上都优于音素模型。
量化进一步加快了推理速度:与浮点模型(E 7)相比,不对称量化(E 8)将RT90提高了28%,而绝对WER下降仅为0.1%;对称量化(E 9)假设权重集中在零附近,仅在VS WER上引入了额外的小衰减,但导致RT90的大幅降低(与float模型相比降低了64%),是真实速度的两倍。时间。此外,量化将模型尺寸减小了4 倍。我们的最佳模型(E 9)也比传统的CTC模型B 2 快,同时仍可将精度提高20%以上。