会议:INTERSPEECH 2019
论文:Prosody Usage Optimization for Children Speech Recognition with Zero Resource Children Speech
作者:Chenda Li, Yanmin Qian
Abstract
儿童语音识别仍然是自动语音识别的一大挑战。由于处理过程更加困难且数据收集成本较高,因此大多数当前的ASR系统仅使用大量成人语音而儿童语音甚至没有语音进行优化。因此,当面对儿童语音时,儿童语音与成人语音之间的声学失配是ASR性能下降的主要原因。为了解决这个问题,我们提出了几种在不使用任何儿童语音数据的情况下改善儿童语音识别的方法。针对基于韵律的特征开发了一种更好的利用策略。首先,在训练和测试中分别探讨音调和韵律修饰,这可以显着减少两种类型的语音之间的不匹配。此外,结合韵律修改后的语音和原始语音进行联合解码的目的是在儿童和成人语音上获得更强大的性能。在普通话语音识别任务中对实验进行评估,培训中只有400小时的成人语音。结果表明,我们提出的方法可以使儿童的语音获得较大的收益,与基线相比,WER降低了约20%,并且对于该系统,成人语音也没有观察到明显的退化。
5. Conclusions
在本文中,我们仅在训练中使用成人数据的情况下,探索了多种韵律用法来改善儿童语音的语音识别系统。 针对基于韵律的功能开发了一种更好的利用策略。 首先,在训练和测试中分别探讨音高和韵律的修改,这可以显着减少两种类型的语音之间的不匹配,并且可以明显改善儿童的语音。 此外,结合韵律修改后的语音和原始语音进行联合解码的目的是在儿童和成人语音上获得更强大的性能。 使用所有提议的技术构建的最终系统可以大大改善普通话儿童的语音识别能力,并且成年人语音的WER不会明显下降。
1. Introduction
近几十年来,已经提出了许多方法来改善自动语音识别(ASR)系统的性能[1,2,3,4]。凭借大量的培训数据和先进的模型结构,ASR系统开发取得了重大进展。但是,现代ASR系统仍然面临的一项挑战是儿童的语音识别。据我们所知,在以前的研究中,与成人ASR系统相比,对儿童ASR系统的投入较少。
改善ASR系统对儿童的表现的一种方法是在训练中引入更多的儿童语料库[5]。由于基于DNN的ASR系统[6]是由数据驱动的,因此通常认为,使用大量训练数据,ASR系统的性能会更好。但是,大多数公共语料库都是由成年演讲者收集的。儿童难以进行ASR训练的语料库通常比成人小[7]。另一种方法是通过算法减少儿童和成人语音之间的声学失配。这些声学失配有某些形式[8、9、10]。声音不匹配的主要原因是儿童的声道短于成人[11、12、13、14]。当将由成人语料库训练的ASR系统应用于儿童语音时,儿童和成人语音之间的不匹配会导致性能下降。
在大多数实际应用中,获得良好标签的儿童语料库的时间和资源成本非常高,尤其是对于某些资源匮乏的语言而言。因此,在本文中,我们尝试通过上述第二种方法解决挑战,使用算法减少了儿童和成人语音之间的声学失配。
主要的声音失配之一是儿童的基本频率通常高于成人的频率[14]。针对基本频率失配,提出了一种韵律修正方法来减小失配。我们以两种方式执行韵律修改方法。第一种方法是在成人训练语料库上修改韵律,使声学特征更接近儿童。相反,第二种方法是在测试时直接对儿童的语音进行韵律修改。
在实践中,上述韵律修饰方法在改善儿童语音识别性能方面效果很好,并且在儿童语音识别方面取得了显着改善。但是,这种方法也会导致成人语音的性能下降。为了克服该缺点并使系统更加健壮,随后引入了联合解码方法,可以进一步提高系统性能。联合解码方法不需要重新训练所构建的系统,这是灵活的并且低成本。
本文的组织如下。在第2节中,为儿童的语音识别引入了韵律功能,包括韵律修改和音调功能。在第3节中,设计了具有不同韵律修改的联合解码体系结构。详细的实验结果和分析将在第4节中进行描述,并在第5节中最终得出结论。
2. Prosody Feature for Children’s Speech
2.1. Motivation
如第1节所述,儿童说话的基本频率高于成人。 成人的基本频率范围,男性通常为85 Hz至180 Hz,女性通常为165 Hz至255 Hz [15,16]。 儿童的基本频率范围是从200 Hz到350 Hz [17]。 因此,将与韵律相关的特征添加到系统中可以改善系统性能。 本文探讨了两种类型,包括通过调整基频来进行韵律修改,以及明确使用音调特征。
2.2. Prosody Modification
我们使用的韵律修改过程可以描述为以下步骤:
首先,通过对原始音频信号f(t)进行因子λ重采样,我们得到了一个新信号f(λt)。将f(t)的傅立叶变换表示为fˆ(ω)。然后,f(λt)的傅立叶变换可以表示为: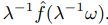 此重采样过程会同时移动频率分量并更改语音持续时间。例如,可以通过对原始语音进行下采样来调整成人语音的基本频率,而语音持续时间将变短。其次,由于我们假定儿童和成人的语音持续时间相同,因此我们对频率调谐的信号执行WSOLA [18]过程。 WSOLA是一种基于波形相似度的高质量时标修改算法,可以使原始信号的基本频率保持不变。
此重采样过程会同时移动频率分量并更改语音持续时间。例如,可以通过对原始语音进行下采样来调整成人语音的基本频率,而语音持续时间将变短。其次,由于我们假定儿童和成人的语音持续时间相同,因此我们对频率调谐的信号执行WSOLA [18]过程。 WSOLA是一种基于波形相似度的高质量时标修改算法,可以使原始信号的基本频率保持不变。
为了增强经过成人语料库训练的ASR系统的性能,以识别儿童的语音,我们对韵律进行了修改,以减少成人和儿童语音之间的声音不匹配。我们提出了两种修改韵律的方法,以消除训练集中的成人语音与评估集中的儿童语音之间的不匹配。一种是调整训练语料库中成人语音的韵律,并使用经韵律修饰的语料库重新训练声学模型。另一种方法是直接在评估中调低孩子说话的韵律。
SoX [19]是一种音频处理工具,我们使用它来进行韵律修改。例如,要调高话音韵律,我们可以使用SoX的速度命令以λ为因子对原始音频进行下采样。此过程会同时更改原始信号的长度,换句话说,语速变得更高。对于本节前面提到的第二个过程,我们使用SoX提供的速度命令(该命令基于WSOLA [18]实现)来修改音频信号的速度,同时保持原始音高和频谱不变。结合这些程序,我们可以在不改变语速的情况下完成韵律修改。
图1显示了原始成人语音和相关的韵律调高语音的频谱图的比较。该话语是从成人训练语料库中随机选择的。原始语音使用λ= 1.1下采样。然后执行WSOLA算法以使持续时间与原始信号相同。从这两个频谱图说明中可以看出,图(b)中的音高和共振峰频率高于图(a)中的音高和共振峰频率。

2.3. Pitch Feature
可以通过两种方式来表达在优化儿童语音识别中添加额外音高功能的动机。 (1)一方面,音高特征是对声音的听觉感知的一种表现[20]。 在第2.2节中提出的修改韵律的过程中,对语音韵律进行了修改。 直观地讲,提取音高特征有助于DNN声学模型将注意力更多地集中在韵律上。 (2)另一方面,在[21]中,提出了一种有效的音高提取算法。 在该算法中,除了音高特征外,还将提取发声特征和三角音高特征的概率。 先前的著作[21,22]已经表明,添加额外的音高特征可以提高诸如中文和粤语ASR等音调语言的性能。 本文探讨并评估了儿童对普通话的语音识别。
3. Joint Decoding with Prosody Modification
3.1. Shortcoming of prosody modification
韵律修饰方法可以显着改善儿童的语音表现。但是,通常会观察到,如果我们使用韵律调整后的训练数据训练声学模型,或者直接针对儿童的测试语音修改韵律,则成人评估集的性能可能会下降。原因可能是韵律修改仅适用于训练集或测试集,可以减少儿童语音的声音不匹配,但是相反,它可能会增加成人语音的不匹配。
3.2. Joint Decoding
为了克服这个缺点,我们提出了一种联合解码架构,该联合解码架构更容易应用于已经训练有素的ASR系统。受声学系统组合[3,23]中先前工作的启发,在评估过程中,原始语音和韵律修改后的语音都通过声学模型转发,如图2所示。声学模型同时生成两个声学似然度,然后通过α的权重组合这两个似然度。将o和ˆo分别表示为原始和韵律调谐的声学特征,DNN输出的新可能性可以表示为:
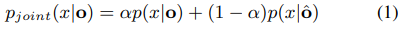
然后,将联合声学似然性pjoint(x | o)通过标准解码管线,以获得最终结果。 这种具有不同韵律修改的联合解码框架可以利用原始语音和新语音的优势,从而可以进一步增强系统的鲁棒性,并改善成人和儿童语音的性能。

4. Experiments
4.1. Experimental setup and baseline system
我们会使用一个400小时手工转录的普通话成人语料库来训练我们的基准系统。语料库中有481K语音,平均持续时间为3秒,其中95%用作训练集,其余5%用作验证集。有两个测试集可以评估我们提出的方法。第一个包含15626个儿童语音发音的测试集用于评估系统在儿童语音识别任务上的性能。另一个包含成人语音8272的测试集用于评估成人语音识别任务的性能。
首先训练基于高斯混合模型的隐马尔可夫模型(GMM-HMM),该模型由9663个聚类状态组成。然后,使用GMM-HMM模型对400小时语料库进行强制对齐,以获取状态级别标签。 Kaldi工具包[24]用于建立深度神经网络(DNN)声学模型。 DNN包含5个隐藏层,每层包含2048个单位,每层之后使用ReLU激活功能;输入层有1320个单位,因为我们使用的是增量为2阶和±5帧扩展的40维滤波器组功能;输出层由对应于GMM-HMM群集状态的9663个单元组成。
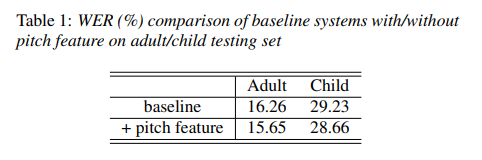
儿童和成人测试集的字错误率(WER)在表1中列为第一行。可以看出,与成人语音相比,孩子的语音难以识别,并且仅对成人语音使用传统的声学建模方法时,性能差距很大。
4.2. Pitch feature
遵循[21]中的方法,使用Kaldi工具包提取3维音高特征,包括发声概率,音高特征和pitch-delta特征。音高功能与40维滤波器组功能结合在一起。实验设置类似于我们在4.1节中提到的设置,DNN中使用了5个隐藏层,每层2048个单位。激活功能是ReLU。对于输入层,使用了43维特征,包括滤波器组和具有2阶增量和±5帧扩展的间距。因此,此设置中的输入层包含1419个单元(考虑到3维间距特征),这与4.1节中的设置有所不同。
如表1所示,借助音调功能,成人和儿童的语音都得到了持续改善。
4.3. Prosody modification on training
2.2节中提到的韵律修改过程是在400小时的成年语料库上执行的,其因子λtrain= {1.05,1.1,1.15}。 然后,根据儿童的语音和成人语音评估使用经韵律修饰的成人语料库训练的声学模型。 模型的配置和训练过程与基线完全相同,表2列出了在训练中使用韵律修改的方法的性能比较。
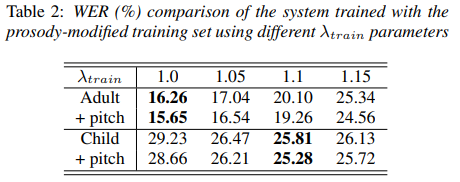
从表2中可以看出,当λtrain= 1.1时,儿童语音识别的性能达到最佳位置。但是,仅用韵律修饰语料训练的系统在对成人语音进行评估时会遭受性能下降。一方面,这种现象表明成人训练语料库上的韵律修饰确实可以改善儿童的语音识别。另一方面,对训练语料库的这种简单的韵律修改会导致真实成人语音和韵律经过修改的成人语音之间的声音失配,从而导致成人语音的性能下降。
为了减少这种退化,将经韵律修改的训练语料库与原始训练语料库相结合,以获得800小时的训练语料库。如表3所示,使用800小时语料库训练的新系统显着降低了对成人语音识别的影响。它表明,将原始的训练语料库与经韵律修饰的语料库相结合,可以使儿童语音的WER降低15%,并且不会对成人语音造成明显的性能下降。

4.4. Prosody modification on testing
在实践中,对测试语料库的韵律修改更加灵活。 该模型无需重新训练,可以直接使用原始成人模型在测试中执行。 建议的韵律修改测试是在原始的400小时成人培训系统上进行评估的。 比较了修正因子λtest= {0.86,0.88,0.9,0.92,0.94}。 如表4所示,观察到与第4.3节类似的结论。 通过直接测试语音的韵律修改,可以显着提高儿童语音的性能,并且当λtest= 0.9时可以达到最佳位置。 相反,随着降低的韵律修改因子,成人语音的准确性逐渐降低。

4.5. Joint decoding with prosody modified speech
在本小节中,评估了用于儿童语音识别的联合解码方法。 DNN声学模型使用400小时的成人语料库进行训练。在评估中,首先以λtest= 0.9进行韵律修改方法,然后将修改后的语音和原始语音都输入到声学模型中。然后,按照第3节中所述的方法,将从DNN声学模型生成的两个似然流进行组合。解码管线与基线设置相同。
实验结果如表5所示,声学模型建立在原始的400小时成人主体上。它表明,与表4中测试语音的直接韵律修改相比,所提出的联合解码可以进一步改善儿童语音的系统性能。另一方面,成人语音的准确性也得到了提高,并且性能下降进行联合解码时,基准成人语音的幅度很小。

4.6. Evaluation summary of the proposed approaches
最后,我们尝试结合本文提出的不同方法来构建我们最好的儿童语音识别系统,其性能比较总结在表6中。

结果表明,所有新提出的方法都可以显着提高儿童的语音识别能力。 不同的方法在不同的级别上利用韵律知识,并且可以将这些单独的技术结合起来以获得进一步改进的系统。 我们的最终系统可以使儿童的语音获得较大的收益,而WER降低约20%,并且与基准相比,成人语音仍然具有相同的高性能。
