一、本文主要内容
中文的命名实体识别的一个双向LSTM-CRF模型,作者找到了最适合中文的LSTM block块, 汉语中存在着较复杂的性质,如缺乏词界、复杂的构成形式、不确定长度、NE嵌套定义等,应用在CNER中的方法:最大熵、隐马尔可夫模型、支持向量机、条件随机场算法等。
基于字符的标记策略在没有中文分词(CWS)结果的情况下取得了相当的性能,这说明中文的NER任务,基于单个汉字是可以做到很好的效果,分词在一定程度上存在误差。
作者分析了一下相关的NER任务的做法,然后发现基于字根的做法很少,而且是基于字根做embedding,于是作者就采用字符级的LSTM(基于字根),进而去做CNER。前一个图是基于字符级的LSTM,后一个是基于字根的一个LSTM
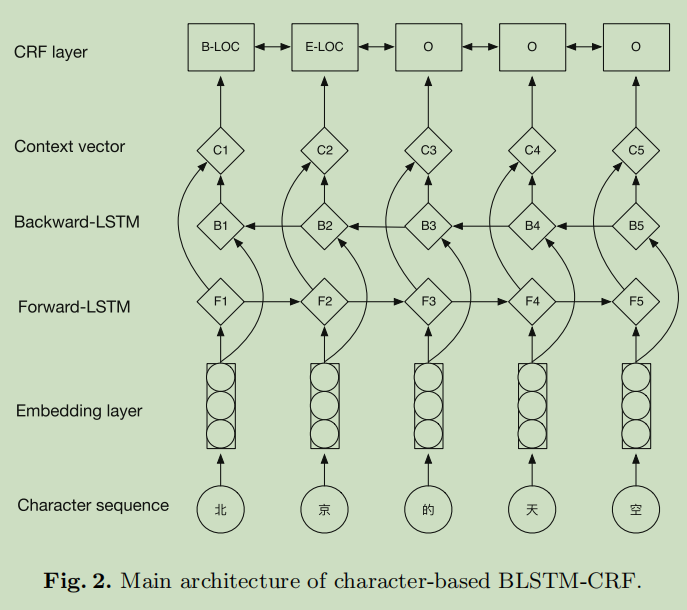
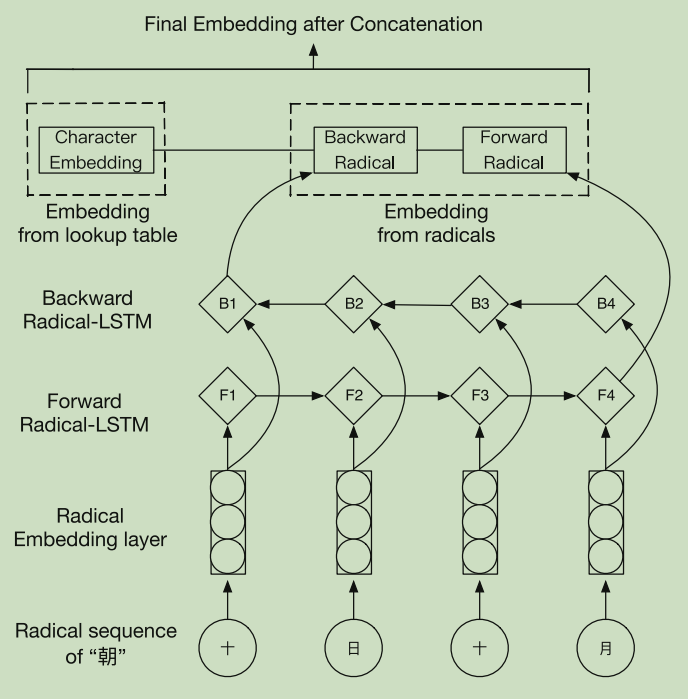
字根的发现,可以在新华字典中找到,a radical-level bidirectional LSTM to capture the radical information ,上图显示我们如何获得字符的最终输入嵌入。
序列标记,采用IOBES
预训练词向量,采用CBOW训练
二、相关工作
dropout training 大小为0.5,back-propagation 算法更新训练参数,用SGD算法以及0.5到50的学习率在训练集上。维度测试为三种:50、100、200
三、个人想法
1、字符级的BI-lstm-crf,效果比基于词的双向LSTM-crf要好。
2、本文扩展了一个新思路,就是词根,但是词根的效果,比预训练词嵌入的效果要差一点,可以将这个再优化或者结合在预训练的词嵌入或者字符嵌入中。
3、将字进行分解,然后,将分解后的词根作为输入,输入到BI-LSTM,再生成这个字的embedding。
4、中文、英文的NER任务,方法略有不同,可以多看几篇后进行总结分析
5、本文也采用的IOBES标记法,这个标记比IBO更能体现实体的前后关系。