在将数据进行分析或者跑机器学习算法时,缺失值处理是很重要的一步,下面将通过读取csv文件来举例说明。
读取csv文件时常见的缺失值有如下类型。
- 空数据
- 0
- NA
- 其他表示形式,如‘null’
一、空数据和NA数据以及其他表示空的数据
创建一个测试文件,从中可以看出,空数据或者是NA数据都会被默认为是NaN。并且在文件中只有是NA或者是空是才会被转换为NaN,而如果是null、None之类的则会被当作字符串处理。
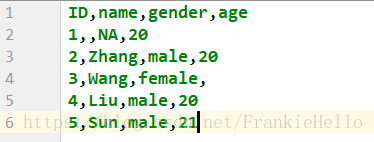
ID name gender age
0 1 NaN NaN 20.0
1 2 Zhang male 20.0
2 3 Wang female NaN
3 4 Liu male 20.0
4 5 Sun male 21.0既然都被转换为了NaN,那么就可以通过pandas.fillna()来将Nan替换为指定的值了。
df = pd.read_csv('./data/for_test.csv')
df['name'] = df['name'].fillna('WU')
df['age'] = df['age'].fillna(df['age'].mean())
df['gender'] = df['gender'].fillna('male')
print(df) ID name gender age
0 1 WU male 20.00
1 2 Zhang male 20.00
2 3 Wang female 20.25
3 4 Liu male 20.00
4 5 Sun male 21.00如果是null或者None之类的表示空的字符串可以先通过replace函数来处理,将这些空都统一为NaN。
df = df.replace('null', value=np.NaN)
二、如何在大规模数据中判断缺失值
通过一中的分析可以知道,无论是空还是Na形式的数据在DataFrame中都会转换为NaN数据类型。
下面通过Kaggle中House Price中的数据来进行举例说明如何在大规模数据中判断缺失值。
df = pd.read_csv('./data/train.csv')
miss_data_total = df.isnull().sum().sort_values(ascending=False)
miss_data_per = (df.isnull().sum()/df.isnull().count()).sort_values(ascending=False)
miss_data = pd.concat([miss_data_total, miss_data_per], axis=1, keys=['Total', 'Percentage'])
print(miss_data.head(10))首先,通过对总体数据进行isnull()判断,然后进行降序处理方便查看。其中,df.isnull().sum()作用就是将df.isnull()返回的True or False数组按照行相加,得到的就是null的个数,而df.isnull().count()则是统计整个True or False 数组的大小,如果这里用df.count()的话之会返回非null数据的个数统计。
Total Percentage
PoolQC 1453 0.995205
MiscFeature 1406 0.963014
Alley 1369 0.937671
Fence 1179 0.807534
FireplaceQu 690 0.472603
LotFrontage 259 0.177397
GarageCond 81 0.055479
GarageType 81 0.055479
GarageYrBlt 81 0.055479
GarageFinish 81 0.055479其中缺失值大于15%的数据列我们就可以考虑将其直接删掉了。
三、如何在大规模数据中处理缺失值
对于缺失值大于15%的数据我们可以直接删除了。
df = df.drop((miss_data[miss_data['Percentage'] > 0.15]).index, axis=1)
对于一些需要再考虑的数据列我们可以先打印出来,再进行选择如何补全数据。
# check the missing data
def cat_exploration(df, column):
print(df[column].value_counts())
# imput the missing data
def cat_imputation(df, column, value):
df.loc[df[column].isnull(), column] = value还有些数据的缺失值通过实际情况判断,结果比较明显,那么就可以直接填充。
df.loc[df['Id'] == 580, 'BsmtCond'] = 'TA'