参考英文文献:
Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch
Transformer Block 弄懂Transformer Layer 和Transformer Block的关系后,豁然开朗_MengYa_DreamZ的博客-CSDN博客
https://www.tensorflow.org/text/tutorials/transformer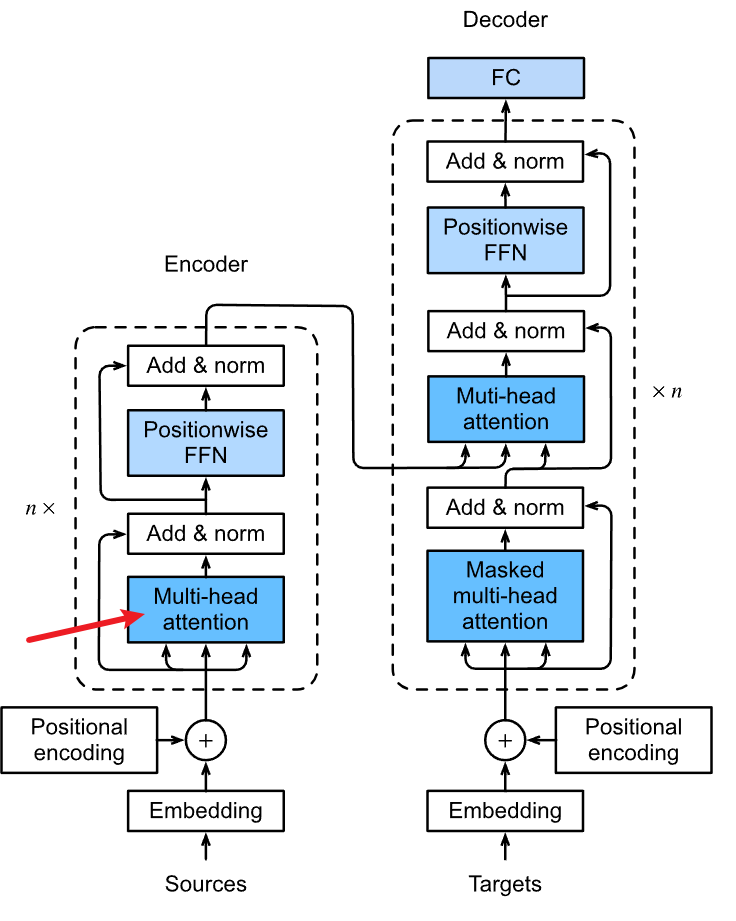
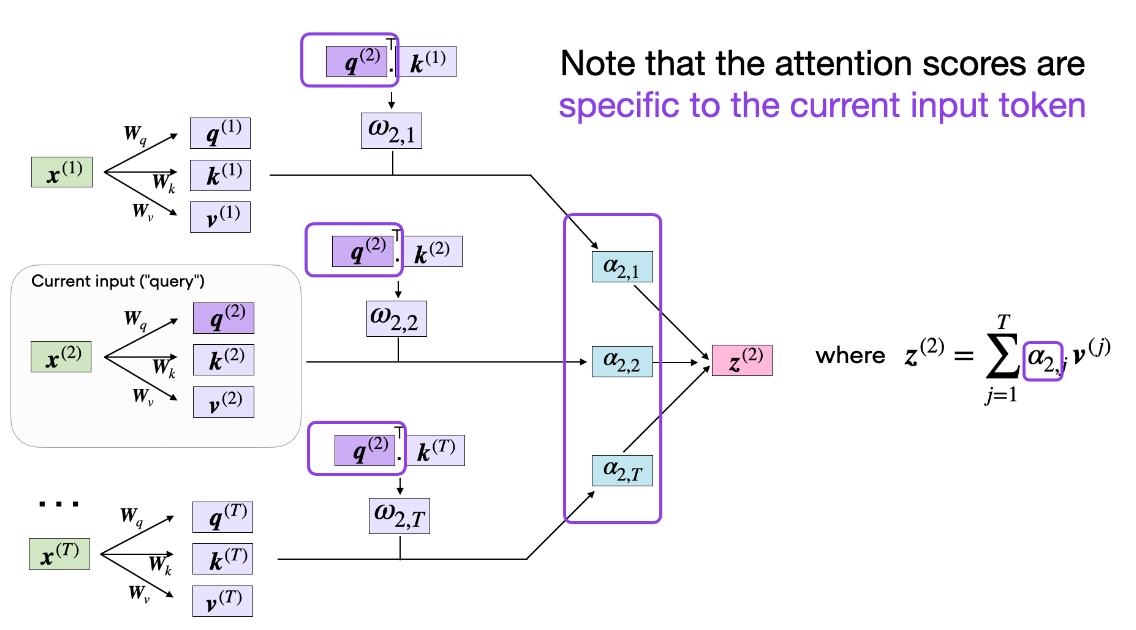
解读参考链接:Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch

上面是一个头的工作原理图,如果是多个头?
多头注意力是一种将注意力机制分解为多个子空间的方法,它可以让模型同时关注不同方面的信息,提高模型的表达能力和泛化能力¹。 多头注意力的融合方式是将每个头的注意力输出向量拼接起来,然后经过一个线性变换层,得到最终的注意力输出向量。
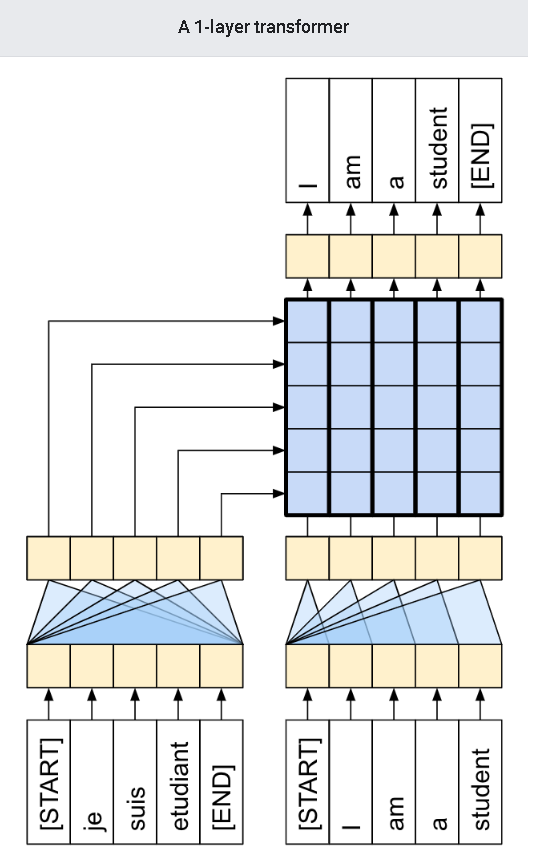
Transformer
- 编码器的输入是源语言的输入序列,例如英语句子。每个输入单词首先经过一个词嵌入层(Word Embedding),将其转换为一个固定维度的向量。然后,每个词向量还要加上一个位置嵌入向量(Positional Encoding),用于表示单词在句子中的位置信息。位置嵌入向量可以通过训练得到,也可以使用三角函数计算得到。词向量和位置向量相加后,就得到了编码器的输入向量。
- 编码器的输出是一个隐藏状态矩阵,每一行对应一个输入单词的编码信息。编码器由多个相同的编码层(Encoder Layer)堆叠而成,每个编码层包含两个子层:多头自注意力层(Multi-Head Self-Attention)和前馈神经网络层(Feed Forward Neural Network)。多头自注意力层用于计算输入序列中每个单词与其他单词的相关性,前馈神经网络层用于对自注意力的输出进行非线性变换。每个子层后面还有一个残差连接(Residual Connection)和一个层归一化(Layer Normalization)操作,用于提高模型的稳定性和泛化能力。编码器的最后一个编码层的输出就是隐藏状态矩阵,它将作为解码器的输入之一。
- 解码器的输入是目标语言的部分输出序列,例如中文句子。每个输出单词也要经过一个词嵌入层和一个位置嵌入层,得到解码器的输入向量。解码器的输出是一个概率分布向量,表示下一个输出单词的预测概率。解码器由多个相同的解码层(Decoder Layer)堆叠而成,每个解码层包含三个子层:多头自注意力层、多头编码-解码注意力层(Multi-Head Encoder-Decoder Attention)和前馈神经网络层。多头自注意力层用于计算输出序列中每个单词与其他单词的相关性,多头编码-解码注意力层用于计算输出序列中每个单词与输入序列中每个单词的相关性,前馈神经网络层用于对注意力的输出进行非线性变换。每个子层后面也有一个残差连接和一个层归一化操作。解码器的最后一个解码层的输出经过一个线性层和一个softmax层,得到下一个输出单词的概率分布向量。