算法原理
本文利用self-attention的方式去学习句子的embedding,表示为二维矩阵,而不是一个向量,矩阵中的每一行都表示句子中的不同部分。模型中使用了self-attention机制和一个特殊的regularization term。
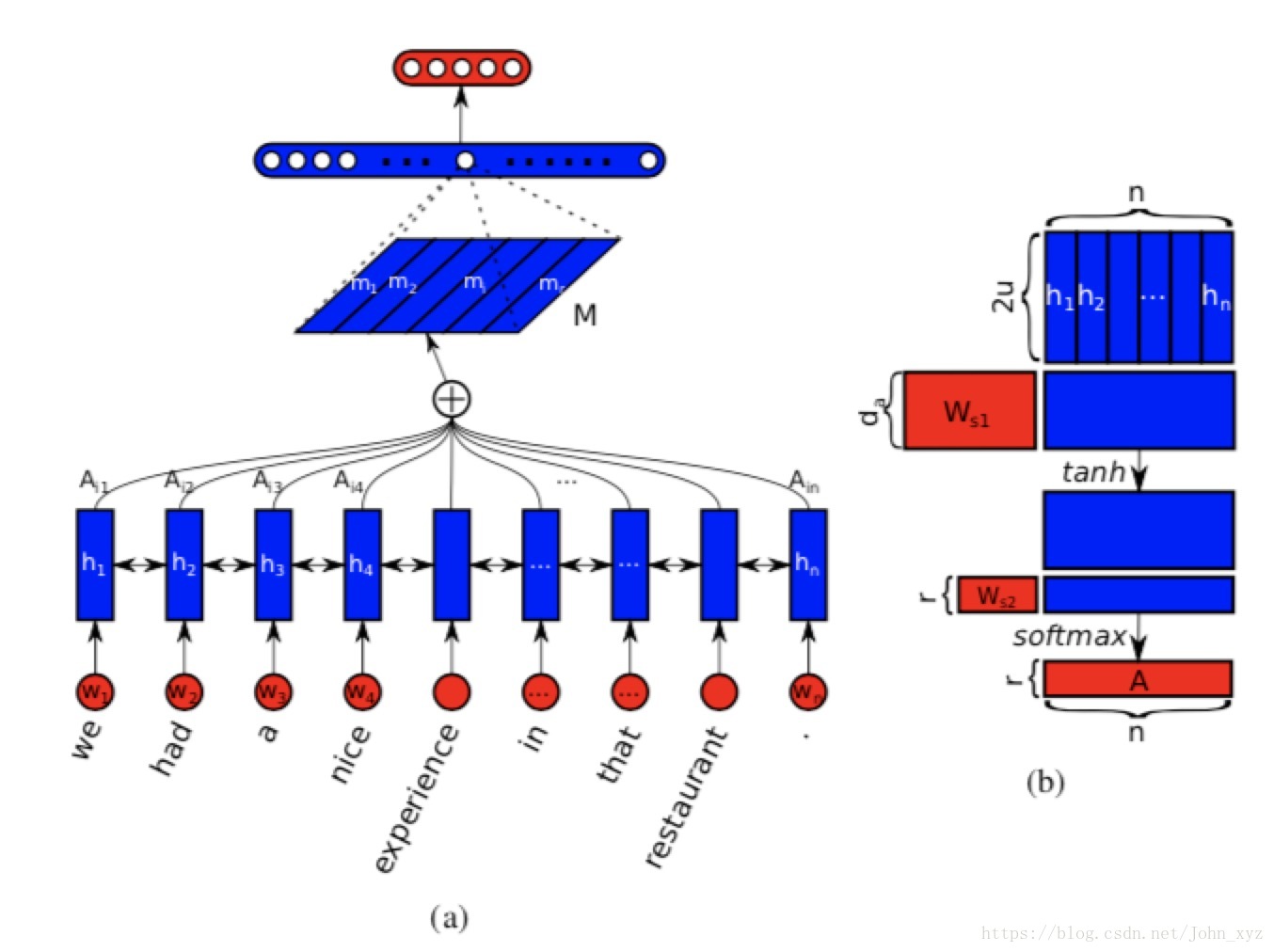
假设我们有一个句子
, 包含
个单词
每个 都是 维的词向量,所以 是一个二维的矩阵,形状为(n,d)。
上图中的图(a)是整个模型的流程,图(b)是计算self-attention的过程。具体的。为了得到单词之间的相关性,使用双向LSTM处理这个句子:
将 和 级连在一起,得到隐状态(hidden state) 。让每一个单向LSTM隐状态单元数是 , 那么 的形状就是
我们的目的是为了将变长的句子编码成固定长度的向量或者矩阵。可以使用 中 个LSTM隐向量的线性组合来表示。因此我们引入了self-attention机制。
所谓的self-attention,就是不同的词有不同的重要性,这个重要性也是根据单词和句子本身计算得到的。上图中的图(b)解释了self-attention的计算过程. 将整个LSTM的隐状态作为输入,输出权重向量
其中 权重矩阵的形状是 , 是长度为 的一维向量。因为 的形状是 ,得到向量 的最终长度为 ,因为 函数可以保证最终和为1,最后将LSTM的隐状态 和计算得到的 向量加权求和,就可以得到句子的表示

这种向量表示一般专注于句子的某个方面。为了实现attention的多样性, 即我们想提取出 个不同的attention,不同的attention方案可以学习到不同侧重点的句子表示,可以用如下公式计算:
, 权重矩阵的形状是 ,上述公式可以看成是没有偏置的两层感知机(MLP)
个加权向量形成加权矩阵 , 将 和LSTM的隐状态 相乘,可以得到sentence embedding ,其形状
惩罚项(Penalization Term)
如果注意机制总是为所有r跳提供相似的权重,则句子嵌入矩阵
会有冗余问题。 因此,我们需要一个惩罚项来鼓励attention的多样性。
是矩阵的Frobenius范数,类似于 正则项。惩罚项 会乘上一个系数,增加到的loss当中。
为了了解惩罚项是如何使attention保持多样性的,我们首先考虑两个不同的attention向量, , , 这两个attention向量的和加起来都为1(因为softmax), 可以看成是离散的概率分布.对任意 中的非对角线元素 ,有
一个最极端的情况,当 和 两个概率分布完全没有重合地方的时候, 会为0,否则就会是一个正数。另一个最极端的情况,如果两个分布完全一样,并且attention都集中在一个单词上。那么会得到最大值1。用 减去单位矩阵, 强制使 的对角线元素为1,这样会使每一个 的attention专注于尽可能少的单词上( 即为对角线元素); 同时也会强制 非对角线元素为0,这样就可以保证attention的多样性。
代码实现
# coding: utf-8
import logging
import tensorflow as tf
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s',level=logging.INFO)
class SelfAttentionSetenceEmbedding(object):
"""TensorFlow implementation of 'A Structured Self Attentive Sentence Embedding'"""
def __init__(self, config, embedding_matrix):
self.lr = config['lr']
self.batch_size = config['batch_size']
self.num_classes = config['num_classes']
self.embedding_size = config['embedding_size']
self.hidden_layer_size = config['hidden_layer_size']
self.beta_l2 = config['beta_l2']
# hyperparameter from paper
# n: sentence length
# d: word embedding dimension
# u : hidden state size
self.n = config['n']
self.d_a = config['d_a']
self.u = config['u']
self.r = config['r']
# load word embedding
self.embedding_matrix = embedding_matrix
def add_placeholders(self):
self.X = tf.placeholder('int32', [None, self.n])
self.y = tf.placeholder('int32', [None, ])
def inference(self):
# define xavier initializer
initializer=tf.contrib.layers.xavier_initializer()
with tf.variable_scope('embedding_layer'):
# fine-tune embedding matrix
W = tf.Variable(self.embedding_matrix, trainable=True, name='embedding_matrix', dtype='float32')
# shape is (None, n, d)
embedding_words = tf.nn.embedding_lookup(W, self.X)
with tf.variable_scope('dropout_layer'):
pass
with tf.variable_scope('bi_lstm_layer'):
cell_fw = tf.contrib.rnn.LSTMCell(self.u)
cell_bw = tf.contrib.rnn.LSTMCell(self.u)
H, _ = tf.nn.bidirectional_dynamic_rnn(
cell_fw,
cell_bw,
embedding_words,
dtype=tf.float32)
# hidden state, shape = (batch_size, n, 2*u)
H = tf.concat([H[0], H[1]], axis=2)
with tf.variable_scope("attention_layer"):
W_s1 = tf.get_variable('W_s1', shape=[self.d_a, 2*self.u],initializer=initializer)
W_s2 = tf.get_variable('W_s2', shape=[self.r, self.d_a],initializer=initializer)
# attention
# shape = (r, batch_size*n)
A = tf.nn.softmax(
tf.matmul(W_s2,
tf.tanh(
tf.matmul(W_s1, tf.reshape(H, [2*self.u, -1]))
)
)
)
# shape = (batch_size, r, n)
A = tf.reshape(A, shape=[-1, self.r, self.n])
# shape = (batch_size, r, 2*u)
M = tf.matmul(A, H)
with tf.variable_scope('fully_connected_layer'):
# shape = (batch_size, 2*u*r)
M_flatten = tf.reshape(M, shape=[-1, 2*self.u*self.r])
# first hidden layer
W_f1 = tf.get_variable('W_f1', shape=[self.r*self.u*2, self.hidden_layer_size], initializer=initializer)
b_f1 = tf.get_variable('b_f1', shape=[self.hidden_layer_size], initializer=tf.zeros_initializer())
hidden_output = tf.nn.relu(tf.matmul(M_flatten, W_f1) + b_f1)
# output layer
W_f2 = tf.get_variable('W_f2', shape=[self.hidden_layer_size, self.num_classes], initializer=initializer)
b_f2 = tf.get_variable('b_f2', shape=[self.num_classes], initializer=tf.zeros_initializer())
# shape = (batch_size, num_classes)
self.y_output = tf.matmul(hidden_output, W_f2) + b_f2
with tf.variable_scope('penalization_layer'):
# shape = (batch_size, n, r)
A_T = tf.transpose(A, perm=[0,2,1])
# shape = (r, r)
unit_matrix = tf.eye(self.r, dtype='float32')
# penalization
# subtract with broadcast
self.penalty = tf.norm(
tf.square(tf.matmul(A, A_T) - unit_matrix), axis=[-2,-1], ord='fro'
)
def add_loss(self):
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=self.y, logits=self.y_output)
loss = loss + self.beta_l2 * self.penalty
self.loss = tf.reduce_mean(loss)
tf.summary.scalar('loss', self.loss)
def add_metric(self):
pass
def train(self):
# Applies exponential decay to learning rate
self.global_step = tf.Variable(0, trainable=False)
# define optimizer
optimizer = tf.train.AdamOptimizer(self.lr)
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(extra_update_ops):
self.train_op = optimizer.minimize(self.loss, global_step=self.global_step)
def build_graph(self):
"""build graph for model"""
self.add_placeholders()
self.inference()
self.add_loss()
self.add_metric()
self.train()