论文:
lResT: An Efficient Transformer for Visual Recognition
模型示意图:
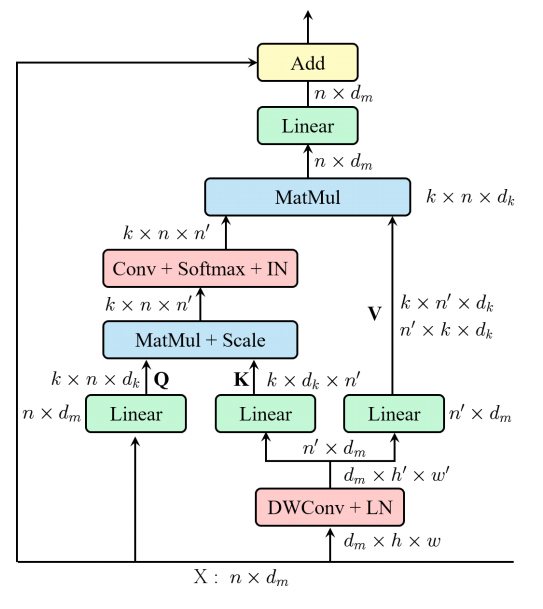
本文解决的主要是SA的两个痛点问题:(1)Self-Attention的计算复杂度和n(n为空间维度的大小)呈平方关系;(2)每个head只有q,k,v的部分信息,如果q,k,v的维度太小,那么就会导致获取不到连续的信息,从而导致性能损失。这篇文章给出的思路也非常简单,在SA中,在FC之前,用了一个卷积来降低了空间的维度,从而得到空间维度上更小的K和V。
代码展示:
import numpy as np
import torch
from torch import nn
from torch.nn import init
class EMSA(nn.Module):
def __init__(self, d_model, d_k, d_v, h,dropout=.1,H=7,W=7,ratio=3,apply_transform=True):
super(EMSA, self).__init__()
self.H=H
self.W=W
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.ratio=ratio
if(self.ratio>1):
self.sr=nn.Sequential()
self.sr_conv=nn.Conv2d(d_model,d_model,kernel_size=ratio+1,stride=ratio,padding=ratio//2,groups=d_model)
self.sr_ln=nn.LayerNorm(d_model)
self.apply_transform=apply_transform and h>1
if(self.apply_transform):
self.transform=nn.Sequential()
self.transform.add_module('conv',nn.Conv2d(h,h,kernel_size=1,stride=1))
self.transform.add_module('softmax',nn.Softmax(-1))
self.transform.add_module('in',nn.InstanceNorm2d(h))
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
b_s, nq ,c = queries.shape
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
if(self.ratio>1):
x=queries.permute(0,2,1).view(b_s,c,self.H,self.W) #bs,c,H,W
x=self.sr_conv(x) #bs,c,h,w
x=x.contiguous().view(b_s,c,-1).permute(0,2,1) #bs,n',c
x=self.sr_ln(x)
k = self.fc_k(x).view(b_s, -1, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, n')
v = self.fc_v(x).view(b_s, -1, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, n', d_v)
else:
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
if(self.apply_transform):
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, n')
att = self.transform(att) # (b_s, h, nq, n')
else:
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, n')
att = torch.softmax(att, -1) # (b_s, h, nq, n')
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
这是一个实现了局部注意力机制的神经网络模块 "EMSA",用于序列序列的数据处理和特征提取。它的主要输入是查询、键和值,其中每个输入都是一个三维张量(batch_size,sequence_length,hidden_size),其中hidden_size是嵌入维度。该模块的设计是基于transformer中的"多头自注意力"机制,但是使用了卷积操作进行计算,以实现局部性。具体来说,EMSA模块包含以下功能:
-
ininit方法 - 用于初始化EMSA模块内的参数,包括输入维度、注意力头数目、键、值和查询维度,以及卷积层、层归一化和正则化层等。
-
forward方法 - 它接受查询,键,值作为输入,并以执行多头自注意力操作。它首先使用全连接层对查询,键和值进行线性映射。然后,如果 "ratio>1” ,则使用二维卷积和层归一化操作对输入进行下采样。接下来,将查询和键进行点积操作,并按照$\sqrt{d_k}$标准化。如果"apply_transform"为True,将点积结果作为输入进行卷积,并使用softmax进行标准化。否则,它直接使用softmax操作。最后,使用点积注意力方法计算输出值并进行线性映射,以获得最终结果。
-
init_weights方法 - 用于对模型参数进行初始化,包括权重和偏差。
在此文件的示例中,EMSA模块的内部参数已经初始化,可以将数据传递给模块实例,并检查输出形状。