声明:语音合成论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
Triple M: A Practical Neural Text-to-speech System With Multi-guidance Attention And Multi-band Multi-time Lpcnet
本文为腾讯2020.02发布的文章,文章主要使用multi-guidance attention 和multi-band multi-time lpcnet来构建对齐较优,可以处理长句子,具有较高实时率的系统。具体的文章链接
https://arxiv.org/pdf/2102.00247.pdf
(好家伙,集百家之长。先不论最终效果如何,看到这样文章还是挺有趣。)
1 背景
虽然端到端的语音合成已经很成熟,但依然存在落地难得问题,尤其是输入和输出的对齐问题。本文提出了使用forward attention和GMM-based attention作为辅助来优化base attention:LSA,使其处理长句子更加鲁棒。另外,本文同时使用multi-band和multi-time对lpcnet进行优化,从而大大提高合成速度。
2 详细设计
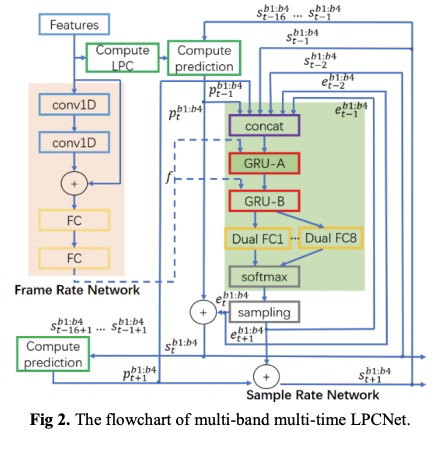
本文的系统如图1所示,首先训练的时候同时训练forward-attention,gmm-based attention和lsa部分,但推理的时候只使用lsa对齐。对于lpcnet的优化同时使用multi-band和multi-time对lpcnet进行优化,每一次生成8个采样点,具体的结构如图2所示。

3 实验
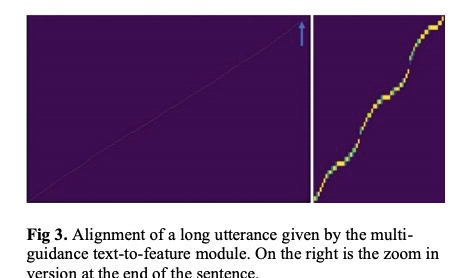
先看一下对齐情况,图3是本文multi-guidance attention处理长句子(200汉子)的效果,而原始的lsa是无法处理该长句子。另外如果处理长句子,使用forward-attention, gmm-attention和lsa的错误率分别40%,15%和60%。而使用本文的方案则错误率为2%。接下来table1展示了MOS的结果,本文的mos比baseline还稍微高一些。最后分析一下本文的multi-band multi-time的lpcnet,结果显示MOS微降情况下,实时率提高2.75倍。


4 总结
章主要使用multi-guidance attention 和multi-band multi-time lpcnet来构建对齐较优,可以处理长句子,具有较高实时率的系统。