一、回归和分类的概念
了解回归算法之前,先来明确两个概念,回归和分类。
回归是指通过算法最终预测出一个连续而具体的值。而分类对应可能结果中的一种。
举个例子:从银行贷款,银行根据你提交的资料,最终会决定放贷|不放贷,把你划分到放贷的类型,或不放贷的类型里面,你只能属于其中一个类别,这就叫分类。而银行根据综合评估,最终决定给你贷多少钱,这个就是回归。
二、线性回归
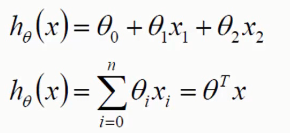
假设有两个特征x1,x2,通过数据训练,可以得到权重参数θ1,θ2,θ0 为固定值,一般为1.
如果有n个特征值,则hθ为n个特征值与权重相乘后的加和,如第二个式子,引入矩阵概念,则可表示为θTx
通常会引入误差来评估准确性。

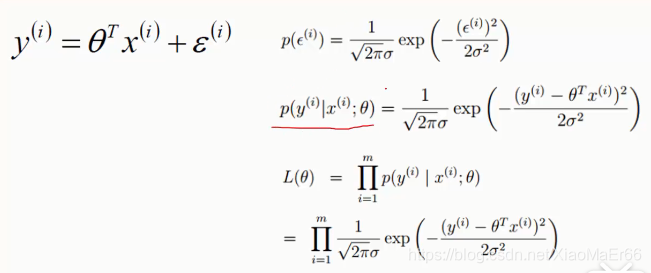
将左边式子代入右边误差概率计算式,找出一个合适的θ使得θ与x的组合使得值最接近于y值的最大概率。
L(θ)-- 似然函数,事件之前相互独立,累乘。
目的:找到合适得θ使得似然函数最大
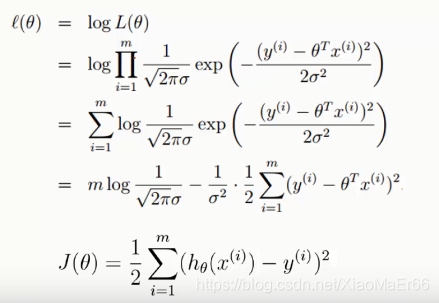
logL(θ)–对数似然函数,使用对数使乘法求最大,变成累加,更易计算。
l(θ)最后一步,减号后面的式子永远为正数,要使得l(θ)最大,只能使减号右边式子最小,J(θ)平方误差代价函数(损失函数)便求的最小值。
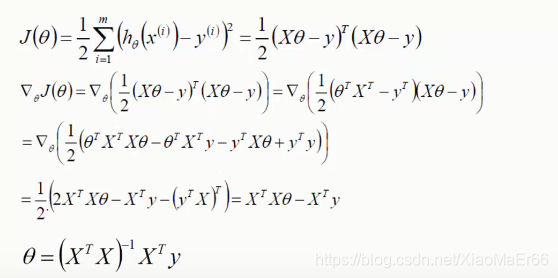
对J(θ)进行求导,引入矩阵,求出θ即可。
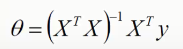
此过程为正规方程求解θ。
利用解析解求解多元线性回归,虽然看起来很方便,但是在解析解求解的过程中会涉及到矩阵求逆的步骤.随着维度的增多,矩阵求逆的代价会越来越大(时间/空间),而且有些矩阵没有逆矩阵,这个时候就需要用近似矩阵,影响精度.
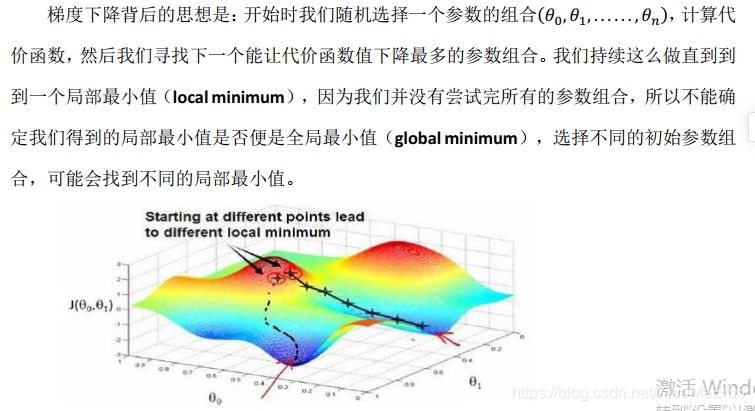
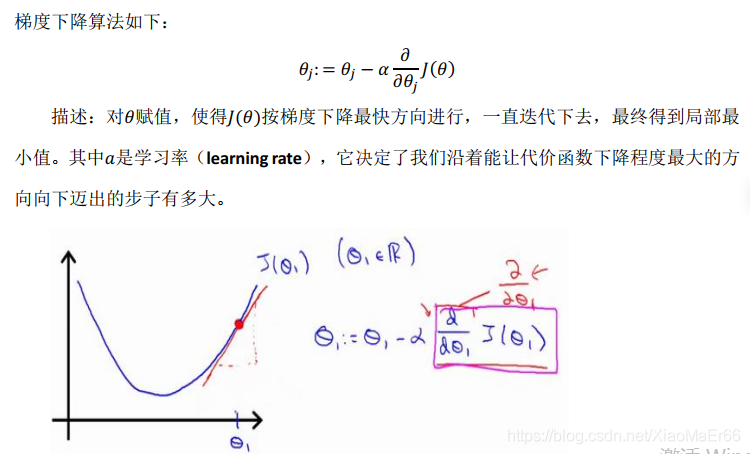
梯度下降(gradient descent)在机器学习中应用十分的广泛,不论是在线性回归还是Logistic回归中,它的主要目的是通过迭代找到目标函数的最小值,或者收敛到最小值。


用python实现代价算法
def computeCost (X,y,theta):
inner=np.power((X*theta.T)-y,2)
#theta.T就是矩阵theta的转置矩阵,theta初始化系数,一般初始化为0,theta=np.matrix(np.zeros(X.shape[1]))
#np.power(A,B) ## 对A中的每个元素求B次方
return np.sum(inner)/(2*len(X))
用python实现梯度下降算法
def gradientDescent(X,y,theta,alpha,iters): #alpha是学习率,iters为迭代次数
temp=np.matrix(np.zeros(theta.shape)) #np.zeros(theta.shape)=[0.,0.],然后将temp变为矩阵[0.,0.]
parameters= int(theta.ravel().shape[1])
#theta.ravel():将多维数组theta降为一维,.shape[1]是统计这个一维数组有多少个元
#parameters表示参数
cost=np.zeros(iters) #初始化代价函数值为0数组,元素个数为迭代次数
for i in range(iters): #循环iters次
error=(X*theta.T)-y
for j in range(parameters):
term = (error, X[:,j]) #将误差与训练数据相乘,term为偏导数,参考笔记P27
temp[0,j] = theta[0,j] - ((alpha / len(X)) * np.sum(term)) #更新theta
theta=temp
cost[i] = computeCost(X,y,theta) #计算每一次的代价函数
return theta,cost
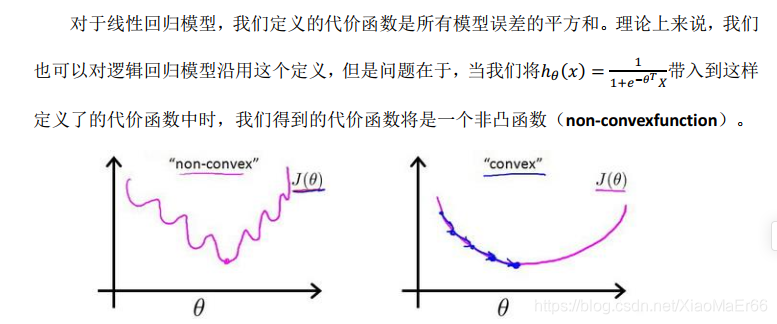
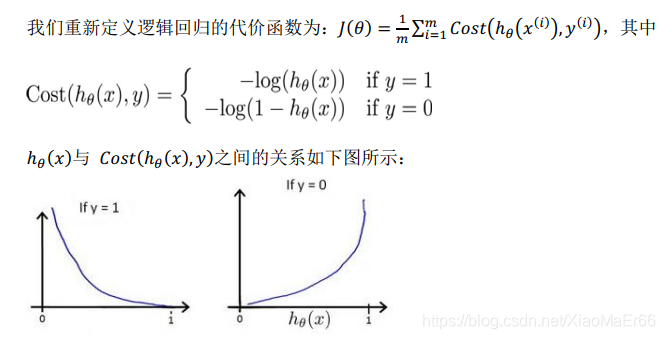
**三、逻辑回归(最经典的二分类问题)**虽然名字带回归,实际更多用于分类问题,计算原理跟回归相似。
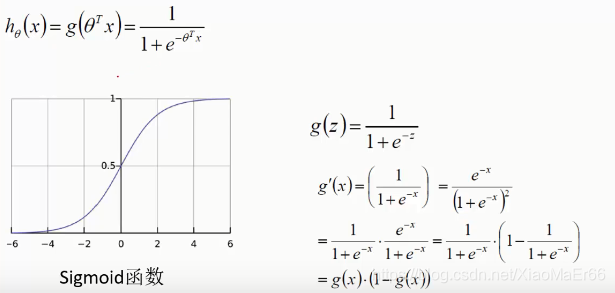
sigmoid函数:x取值范围负无穷到正无穷,y值[0,1],将值映射成概率。
将预测的值传入sigmoid函数中,会得到对于的概率值。

代入梯度下降算法,得到如下式子:

计算时会同时更新所有的θ值。
在样本量极大的时候,每次更新权重会非常耗费时间,这时可以采用随机梯度下降法,这时每次迭代时需要将样本重新打乱,然后不断更新权重。
四、回归算法应用场景
主要用途:
预判和风险识别
获客评估:判断用户是否会成为平台客户;
交易评估:判断用户申请贷款时是否能通过;
风险评估:判断用户还款时是否会预期;
客户留存:判断用户是否会流失;
客户价值:判断用户是否能产生预期的价值;
用户画像:判断用户是否具备某一属性(如性别、品类偏好等)
这些问题都可以看成是二分类问题,这些问题本身有很重要的价值,能够帮助我们更好的了解我们的用户,服务我们的用户。
五、回归算法适用性
1) 可用于概率预测,也可用于分类。
2) 仅能用于线性问题,只有在feature和target是线性关系时,才能用Logistic Regression(不像SVM那样可以应对非线性问题)。这有两点指导意义,一方面当预先知道模型非线性时,果断不使用Logistic Regression; 另一方面,在使用Logistic Regression时注意选择和target呈线性关系的feature。
3) 各feature之间不需要满足条件独立假设,但各个feature的贡献是独立计算的。
六、逻辑回归优缺点
优点:
(1)训练速度较快,分类的时候,计算量仅仅只和特征的数目相关;
(2)简单易理解,模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响;
(3)适合二分类问题,不需要缩放输入特征;
(4)内存资源占用小,因为只需要存储各个维度的特征值;
缺点:
(1)不能用Logistic回归去解决非线性问题,因为Logistic的决策面试线性的;
(2)对多重共线性数据较为敏感;
(3)很难处理数据不平衡的问题;
(4)准确率并不是很高,因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布;
(5)逻辑回归本身无法筛选特征,有时会用gbdt来筛选特征,然后再上逻辑回归。
