回归算法的本质是解决一个线性方程,
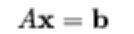
标准估计方法是普通的最小二线性回归。然而,如果没有x满足方程或超过一个x,即解决方案不是唯一的,(常见列多于行)那么就说这个问题是病态的。在这种情况下(病态A),普通最小二乘估计会导致超定(过拟合),或更常见的欠定(下拟合)方程组(A.TAα=A.Tb)。
线性回归
一般预测连续型数据,线性回归主要计算斜率和截距,如果给定的数据集符合线性关系,可以进行线性预测
数据量大,特征少适合做线性回归
逻辑回归,样本太少,精确度不高
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
import sklearn.datasets as datasets
import matplotlib.pyplot as plt
diabetes = datasets.load_diabetes() #糖尿病数据
x=diabetes.data #描述数据
y=diabetes.target
x = x[:,np.newaxis,2] #新建一个轴
x = x[:,0].reshape((442,1)) #转变和y一致
x_train = x[:-20]
x_test = x[-20:]
y_train=y[:-20]
y_test = y[-20:]
lrg = LinearRegression()
lrg.fit(x_train,y_train)
y_new = lrg.predict(x_test)
# plt.scatter(x_test,y_test)
# plt.plot(x_test,y_new)
# plt.savefig('logic_regression.png')岭回归
如果数据的特征属性比样本数据还多(30条数据、500个特征),就适合做岭回归,适合少量数据
实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
from sklearn.linear_model import Ridge
x_train = np.array([[1,1],[3,3]])
y_train = np.array([1.2,3])
ridge = Ridge(alpha=1)
#alpha = 0时,岭回归等价于逻辑回归
#alpha = 1时,放弃一些特征,y偏小
# alpha = -1时,y强化偏大
ridge.fit(x_train,y_train)
ridge.predict([[4,3]])Lasso回归
Lasso算法从最先开始就是为最小二问题的解决而产生的,与岭回归不同;岭回归限定了所有回归系数的平方和不大于t,也就是把所有系数限制在一个多维球体内,包括球面,这样就避免了在使用普通最小二乘法回归的时候,当两个变量相关时,可能产生的两个正负大系数(喇叭口),随着正则项的lambda的增大,高幅振荡的系数迅速转向平稳(参看岭轨迹线)
Lasso算法特点:
1.十分适合稀疏矩阵
2.λ增大时,不重要的变量回归系数=0
下列情况不采用lasso算法
1.是稀疏矩阵时,预测效果最好
2.高度多重相关性时,预测效果不好
逻辑回归
逻辑回归计算分类时,对相同斜率的数据归位一类
我们要在没有回归之前,假设一个回归函数,比如OLS回归可假设回归函数为直线或者多项式等函数。在逻辑回归这里,也是一样要假设一个回归函数。上式就是我们假设的回归函数,在数学上又称之为sigmoid function或者logistic function。我们这里用另一种常用表达式来表达它:
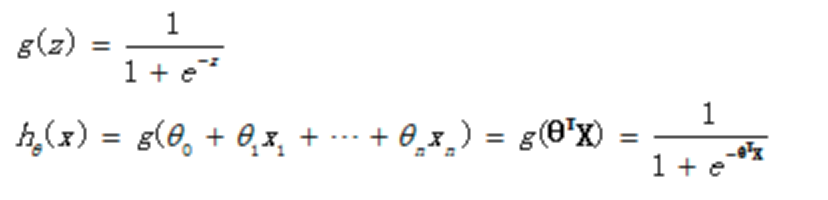
当我们输入特征,得到的hθ(x)其实是这个样本属于1这个分类的概率值。也就是说,逻辑回归是用来得到样本属于某个分类的概率。
最大似然
最大似然法(Maximum Likelihood,ML)也称为最大概似估计,也叫极大似然估计,是一种具有理论性的点估计法,此方法的基本思想是:当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大,而不是像最小二乘估计法旨在得到使得模型能最好地拟合样本数据的参数估计量。(百度)
逻辑回归的损失函数是一个凸函数,求最大值就意味着与我们要应用最大似然原理。也即最佳回归系数,即最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大,也就是使得该n组样本观测值出现的概率最大。
from sklearn.datasets import make_blobs
from sklearn.linear_model import LogisticRegression
data,target=make_blobs(n_samples=300,n_features=2,
centers=[[0,2],[3,1],[4,2]],
cluster_std=0.8)
# plt.scatter(data[:,0],data[:,1],c=target)
# plt.savefig('1.png')
lrg = LogisticRegression()
lrg.fit(data,target)
x_min,x_max=data[:,0].min()-1,data[:,0].max()+1
y_min,y_max=data[:,1].min()-1,data[:,1].max()+1
x,y=np.arange(x_min,x_max,0.01),np.arange(y_min,y_max,0.01)
xx,yy=np.meshgrid(x,y) # shengchengbiaoge
xy_test=np.c_[xx.ravel(),yy.ravel()] #生成测试数据
lrgy_new =lrg.predict(xy_test)
z=lrgy_new.reshape(yy.shape)
# plt.pcolormesh(xx,yy,z,cmap="rainbow")
# plt.scatter(data[:,0],data[:,1],c=target,cmap="gray")
# plt.savefig("11.png")