文章目录
一,概述
1,什么是决策树
首先看一组图
决策树的本身就是一种树形结构,可以通过一些精心设计的问题,对数据进行分类
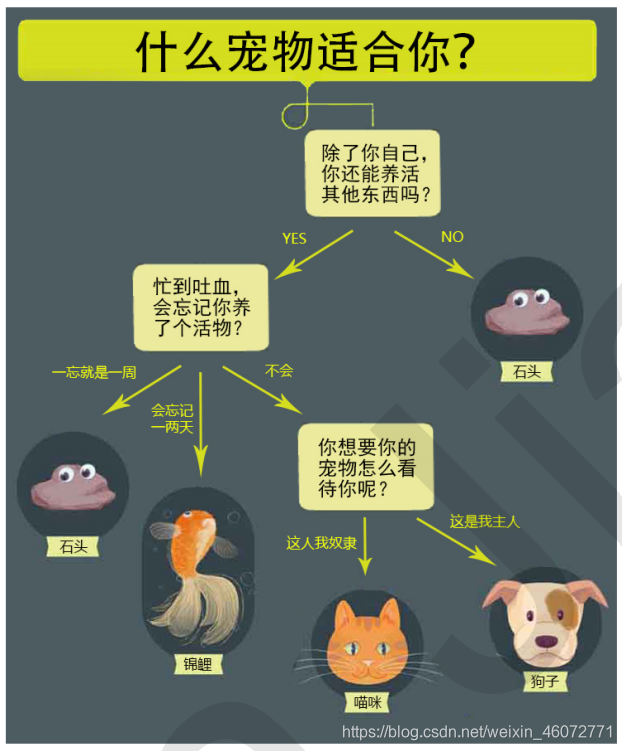
决策树(Decision Tree)是监督学习中的一种算法,并且是一种基本的分类与回归的方法。
决策树有两种:分类树 和 回归树
需要了解的三个概念:

可以把决策树看作是一个 if-then 规则的集合:
— 由决策树的根节点到叶节点的每一条路径构建一条规则
2,特征选择
随着划分过程不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,也就是节点的纯度(purity)越来越高。
下边三个图表示纯度越来越低的过程:
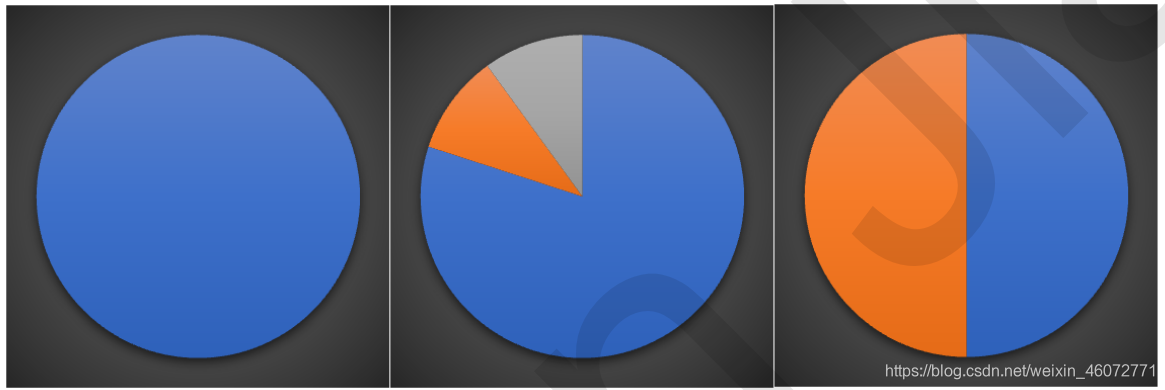
度量不纯度的指标有很多种,比如:熵、增益率、基尼值数。
这里我们使用的是熵,也叫作香农熵。
3,香农熵及计算函数

二,代码实现
1,需要用到的库(pandas传送门)
import numpy as np
import pandas as pd
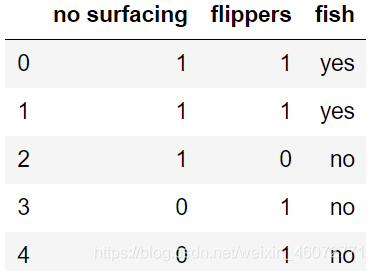
2,数据集
这里使用书上的数据集
def createDatas():
rew_data = {
'no surfacing':[1,1,1,0,0],
'flippers':[1,1,0,1,1],
'fish':['yes','yes','no','no','no']}
dataSet = pd.DataFrame(rew_data)
return dataSet
dataSet = createDatas()
dataSet
3,计算香农熵
输入:原始数据集
输出:熵
def calEnt(dataSet):
n = dataSet.shape[0]
iset = dataSet.iloc[:,-1].value_counts()
p = iset / n
ent = (-p * np.log2(p)).sum()
return ent
计算一下看看
熵越高,信息的不纯度就越高。也就说明混合的数据就越多。
calEnt(dataSet)
>>>0.9709505944546686
4,信息增益

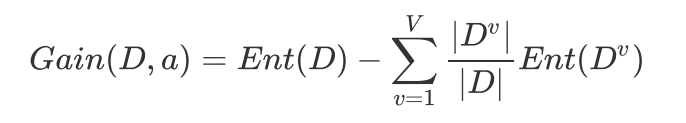
我们来计算一下 第0列 的信息增益
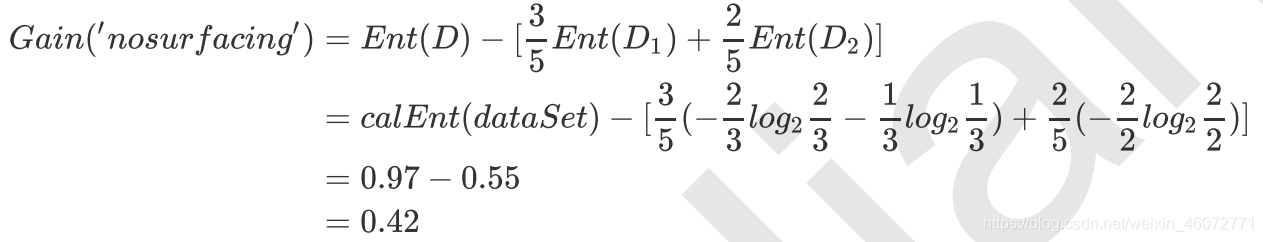
a = (3/5)*(-(2/3)*np.log2(2/3)-(1/3)*np.log2(1/3))
calEnt(dataSet) - a
>>>0.4199730940219749
第1列 的信息增益
a = (4/5)*(-(1/2)*np.log2(1/2)-(1/2)*np.log2(1/2)) + (1/5)*np.log2(1)
calEnt(dataSet) - a
>>>0.17095059445466854
5,数据集最佳切分函数
找出最佳切分列
划分数据集的最佳准则是选择最大信息增益,也就是信息下降最快的方向
函数功能:根据信息增益选择出最佳数据集切分的列
输入:原始数据集
输出:数据集最佳切分列的索引
def bestSplit(dataSet):
baseEnt = calEnt(dataSet) # 计算原始的熵
bestGain = 0 # 初始化信息增益
axis = -1 # 初始化最佳切分列,标签列(索引)
for i in range(dataSet.shape[1] - 1): # 对每一个特征进行循环
levels = dataSet.iloc[:,i].value_counts().index # 当前列的所有取值(没有重复)
ents = 0 # 初始化子节点的信息熵
for j in levels: # 对每一列的每一个取值进行循环
childSet = dataSet[dataSet.iloc[:,i] == j] # 某个子节点的DataFarme
ent = calEnt(childSet) # 该子节点的信息熵
ents += (childSet.shape[0] / dataSet.shape[0]) * ent # 当前列的信息熵
infoGain = baseEnt - ents # 当前列的信息增益
if infoGain > bestGain: # 选择最大的信息增益
bestGain = infoGain
axis = i # 返回所在列的索引
return axis
↓ 可知:第0列为最佳列
bestSplit(dataSet)
>>>0
(第0列 最佳增益:0.42 > 第1列 最佳增益:0.17)
按照给定列切分数据集
参数说明
dataSet:原始数据集
axis:指定列索引
value:指定的属性值
返回
redataSet:按照指定列索引和属性值切分后的数据集
def mySplit(dataSet, axis, value):
col = dataSet.columns[axis]
redataSet = dataSet.loc[dataSet[col] == value,:].drop(col,axis=1)
return redataSet
验证函数,以axis=0(最佳列),value=1为例
mySplit(dataSet, bestSplit(dataSet), 1)

6,递归构建决策树
ID3 算法

编写代码构建决策树
函数功能:基于最大信息增益切分数据集,递归建决策树
输入:原始数据集(最后一列为标签)
输出:字典形式的树
def createTree(dataSet):
featlist = list(dataSet.columns) # 提取数据集所有列(名称)
classlist = dataSet.iloc[:,-1].value_counts() # 获取最后一列 类标签
# 判断:最多标签数目==数据及行数 or 数据集只有一列
if classlist[0] == dataSet.shape[0] or dataSet.shape[1] == 1:
return classlist.index[0] # 是,则返回类标签(递归停止点)
axis = bestSplit(dataSet) # 当前最佳切分列的索引
bestfeat = featlist[axis] # 该列对应的特征
myTree = {bestfeat:{}} # 采用字典嵌套的方式存储树信息
del featlist[axis] # 删除当前特征
valuelist = set(dataSet.iloc[:,axis]) # 提取最佳切分列的所有属性值
for value in valuelist: # 对每一个属性值递归建树
myTree[bestfeat][value] = createTree(mySplit(dataSet,axis,value))
return myTree
运行结果
myTree = createTree(dataSet)
myTree
>>>{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
决策树的存储
使用numpy中的save()函数,直接将字典形式的文件保存为 .npy文件
调用时直接使用 load()函数即可
# 树的存储
np.save('myTree.npy', myTree)
# 树的读取
read_myTree = np.load('myTree.npy').item()
read_myTree
>>>{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
使用决策树执行分类预测
函数功能:对一个测试实例进行分类
参数说明
inputTree:已经生成的决策树
labels:存储选择的最优特征标签
testVec:测试数据列表,顺序对应原数据集
def classify(inputTree, labels, testVec):
firstStr = next(iter(inputTree)) # 获取决策树的第一个节点
secondDict = inputTree[firstStr] # 下一个节点
featIndex = labels.index(firstStr) # 第一个节点所在列的索引
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]) == dict:
classLabel = classify(secondDict[key], labels, testVec)
else:
classLabel = secondDict[key]
return classLabel
函数功能:对测试集进行预测
参数说明
train:训练集
test:测试集
返回
test:分类好的测试集(最后一列为测试结果)
def acc_classify(train,test):
inputTree = createTree(train) # 根据测试集生成一棵树
labels = list(train.columns) # 数据集所有的列名称
result = []
for i in range(test.shape[0]): # 对数据集中的每一条(index)数据进行循环
testVec = test.iloc[i,:-1] # 测试集中的一个实例
classLabel = classify(inputTree,labels,testVec)# 预测该实例的分类
result.append(classLabel) # 将实例追加在result表中
test['predict'] = result # 将预测结果加在标的最后一列
acc = (test.iloc[:,-1] == test.iloc[:,-2]).mean() # 计算准确率
print(f'模型预测准确率为{acc}')
return test
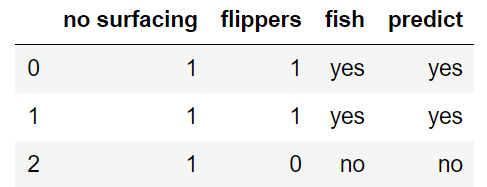
函数测试(使用 原始数据的前3行 作为测试集合)
train = dataSet
test = dataSet.iloc[:3,:]
acc_classify(train,test)
>>>模型预测准确率为1.0
7,使用sklearn中的包实现决策树的绘制
需要使用的包
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
数据的前处理
数据集
x_train = dataSet.iloc[:,:-1]
x_train

标签集
参考文献
.unique()方法的用法
.apply()方法 和 lambda 的用法
y_train = dataSet.iloc[:,-1]
labels = y_train.unique().tolist() # 只留不同的数值,并进行排序
y_train = y_train.apply(lambda x:labels.index(x)) # 将文本转为数字
y_train
>>>0 0
1 0
2 1
3 1
4 1
Name: fish, dtype: int64
构建决策树
clf = DecisionTreeClassifier()
clf = clf.fit(x_train, y_train)
(2020 - 3 - 22 星期日)
