前言: 为什么“算法钻取系列”开篇讲解逻辑回归?
(首先, 我是要成为数据科学家的男人)要成为一个数据科学家最重要的是学习 pipeline ,这包括获取和处理数据的过程、了解数据、建立模型、评估结果 (模型和数据处理阶段) 和产品部署。先学习逻辑回归( logistic regression )能尽快地帮助你熟悉数据科学的 pipeline ,并且不会让你一开始就因为各种高阶、花哨的算法而迷失方向
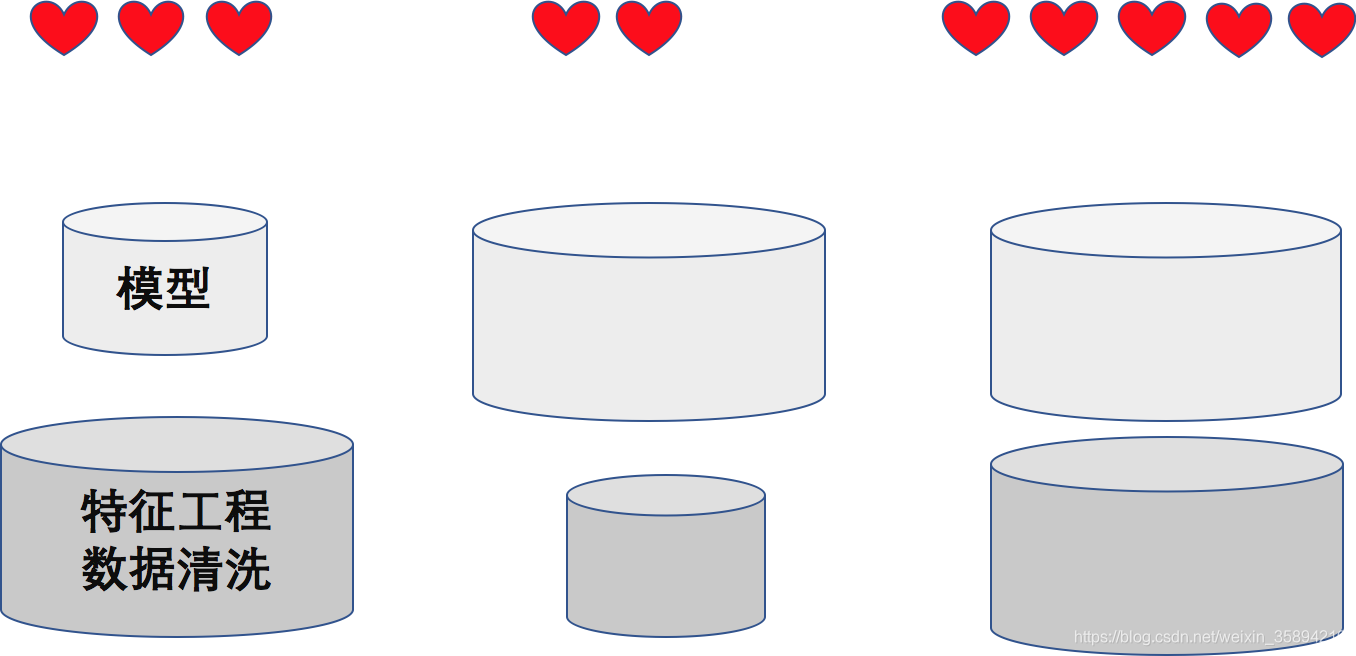
(如何在数据挖掘的比赛中拿到好成绩?见上图)很多使用逻辑回归无法直接解决的问题, 在通过特征工程特征重构之后,都能得到很好的解决, 在机器学习领域所谓好的算法, 只是把任务绝大部分的交给了模型本身, 弱化了特征工程的功能, 终极体就是催生了深度学习这种end-to-end的机器学习方法, 但是深度学习模型其本身就是“特征工程+分类/回归算法”的一类特殊机器学习方法, 最后输出层是回归或分类, 前面的都是特征工程过程(只是我暂时无法理解为什么会构建这些特征). 另一方面, 也是因为对图像语音等非结构化数据特征工程的难度系数更高, 所以在这些领域深度学习大放异彩. 逻辑回归算法很大的意义在于, 它以最简单的姿态向你展示机器学习方法的神奇(一个LR走天下). 他依然具有机器学习算法的三要素: 模型(sigmoid)、策略(最大似然估计)、算法(梯度下降法).
线性回归不仅适用于预测,还可以通过模型拟合的参数,从中学习因变量和自变量之间的关系。或者以更加”机器学习”的语言来说,你可以了解你的特征( features )与你的目标( target )之间的关系.
神经网络中的每一个神经元都可以视为一个逻辑回归模型.
参考文章:https://zhuanlan.zhihu.com/p/37621688
逻辑回归的优化方法
1、一阶方法
梯度下降法及其变种系列
2、二阶方法
牛顿法、拟牛顿法
牛顿法的优点: 在求解图函数寻解问题时(矩阵), 比一阶方法速度更快(向量).
牛顿法的缺点: 牛顿法是定长迭代,没有步长因子,所以不能保证函数值稳定的下降,严重时甚至会失败。还有就是牛顿法要求函数一定是二阶可导的。而且计算Hessian矩阵的逆复杂度很大。
逻辑回归需要对特征进行离散化
1、非线性提升模型表达能力: 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合; 离散特征的增加和减少都很容易,易于模型的快速迭代;
2、 速度快: 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
3、 鲁棒性: 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
(1) 方便交叉与特征组合:离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
(2) 简化模型:特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
逻辑回归前提假设
假设数据服从伯努利分布(经典抛硬币问题, 抛硬币抛出了统计学的两个学派: 经典派、贝叶斯学派(多了先验概率))
模型公式
损失函数(策略)
损失函数一般有四种,平方损失函数,对数损失函数,HingeLoss0-1损失函数,绝对值损失函数。
在逻辑回归这个模型下,对数损失函数的训练求解参数的速度是比较快的。
取对数后(还得加负号, 将最大似然估计与损失函数相对应), 当如果实际正例, 预测值为1, 惩罚为0, 预测值为0, 惩罚值无穷大. 逻辑回归进行二分类的方式可以类比成“挑绿豆“: 有一堆豆子, 有红豆有绿豆, 逻辑回归不是将红豆放进一个碗, 绿豆放进一个碗, 而是绿豆放进一个碗, 剩下的就是红豆.
逻辑回归中为什么使用对数损失而不用平方损失
对于逻辑回归,这里所说的对数损失和极大似然是相同的。 不使用平方损失的原因是,在使用 Sigmoid 函数作为正样本的概率时,同时将平方损失作为损失函数,这时所构造出来的损失函数是非凸的,不容易求解,容易得到其局部最优解。 而如果使用极大似然,其目标函数就是对数似然函数,该损失函数是关于未知参数的高阶连续可导的凸函数,便于求其全局最优解。
逻辑回归中损失函数的实际意义?
(1) 直观的,根据极大似然法将这些条件概率连乘取对数取反得到逻辑回归的损失函数,意义在于希望能够最大化这些样本出现的概率,极大似然法本身的假设就是真实存在的样本出现的概率最大,而相对应的参数就是能够使得这些数据出现概率最大的参数,取反则变成希望真实存在的样本出现的概率的负数最小(也就是我们上面的到的损失函数的公式)。
(2) 二元交叉熵是交叉熵的特殊形式,交叉熵用来衡量概率分布的差异,所以二元交叉熵,也就是逻辑回归的损失函数,就是表示预测值的分布和真实值的分布,这两个分布之间的差异程度,那么我们最优化这个损失函数就是希望预测和真实值的分布的差异越来越小。
训练方法(算法)
(1) 修改训练量: 梯度下降法及其变种系列(优劣?);
(2) 修改学习率(模型层次、参数层次): AdaGrad\Adam\RMSprop\Momentum(原理?优劣?)等
工业应用的优点
1、形式简单,模型的可解释性非常好。从特征的权重可以看到不同的特征对最后结果的影响,某个特征的权重值比较高,那么这个特征最后对结果的影响会比较大。
2、模型效果不错。在工程上是可以接受的(作为baseline),如果特征工程做的好,效果不会太差,并且特征工程可以大家并行开发,大大加快开发的速度。
3、训练速度较快。分类的时候,计算量仅仅只和特征的数目相关。并且逻辑回归的分布式优化sgd发展比较成熟,训练的速度可以通过堆机器进一步提高,这样我们可以在短时间内迭代好几个版本的模型。
4、资源占用小,尤其是内存。因为只需要存储各个维度的特征值,。
5、方便输出结果调整。逻辑回归可以很方便的得到最后的分类结果,因为输出的是每个样本的概率分数,我们可以很容易的对这些概率分数进行cutoff,也就是划分阈值(大于某个阈值的是一类,小于某个阈值的是一类)。
缺点
1、准确率并不是很高。因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布。
2、很难处理数据不平衡的问题。举个例子:如果我们对于一个正负样本非常不平衡的问题比如正负样本比 10000:1.我们把所有样本都预测为正也能使损失函数的值比较小。但是作为一个分类器,它对正负样本的区分能力不会很好。
3、处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据,或者进一步说,处理二分类的问题 。
4、逻辑回归本身无法筛选特征。有时候,我们会用gbdt来筛选特征,然后再上逻辑回归。
公式推导
参考文章:https://zhuanlan.zhihu.com/p/44591359
算法实现
import numpy as np
import pandas as pd
from numpy import random
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
X = load_breast_cancer().data
y = load_breast_cancer().target
sd = StandardScaler()
X = sd.fit_transform(X)
def sigmoid(x):
return 1.0 / (1 + np.exp(-x))
def BGD(X, y, alpha, maxIterations):
dataMatrix = np.mat(X)
labelMat = np.mat(y).T
m, n = dataMatrix.shape
theta = np.random.rand(n, 1)
thetas = []
for i in range(maxIterations):
h = sigmoid(dataMaxtrix.dot(theta))
error = h - labelMat
thetas.append(theta.T.tolist()[0])
theta = theta - alpha * (dataMatrix.T * error)
thetas = pd.DataFrame(thetas)
thetas.plot(figsize=(10, 10))
return np.asarray(theta)
def SGD(X, y, alpha, maxIterations):
m, n = X.shape
theta = np.random.rand(n, 1)
thetas = []
for i in range(maxIterations):
for k in range(m):
randIndex = int(random.uniform(0, m))
h = sigmoid(X[randIndex].dot(theta))
error = h - y[randIndex]
thetas.append(theta.T.tolist())
theta = theta - alpha * (error * x[randIndex])
thetas = pd.DataFrame(thetas)
thetas.plot(figsize=(10, 10))
return theta
逻辑回归是线性模型还是非线性模型?
sigmoid函数就是一个纯粹的数学变换没有任何的可学习参数,我们的决策是直接根据(z = theta * x)式子得到的,sigmoid只是负责映射成非线性的输出罢了,直观的说就是我们的逻辑回归的输出在进入sigmoid函数之前是线性的值,经过sigmoid之后称为非线性的值,所以从决策平面的来说逻辑回归是线性模型,从输出来看逻辑回归是非线性模型,不过一般是从决策平面来定义线性和非线性的,所以我们还是将逻辑回归归为线性模型。
使用逻辑回归解决多分类问题的方法比较
为了详细说明具体举例,比如有三个类A、B、C,ovo的方式就是不同类之间两个两个配对,(A,B),(A,C),(B,C),每两个类之间训练一个模型,最终训练三个模型做预测最后使用投票法得到最终的结果,当然进行概率平均也是可以的。ovr则是把其中一个类当正类,其它类都当作负类,从而(A,others),(B,others),(C,others),仅取三个模型中非others的类别的类概率作为最终结果,显然第二种方式的复杂度最低并且也是目前最常见的一种多分类的处理方法,包括xgboost、lightgbm内部也都是用这种方式来实现的。二者的预测性能,按照西瓜书给的阐述是大部分情况下性能差不多。
逻辑回归和Softmax回归的定义并分析二者关联
如果类别之间是互斥的,用softmax回归,如果类别之间存在交叉则使用多个logistic 回归
如果使用逻辑回归,你是如何提升模型性能的(如何训练得到最优参数)?
特征离散化、特征交叉、调参(学习率和正则化系数等)、gbdt提取高阶特征、使用正则化等。
